


Tiziano
Mercoledì, 17 Dicembre 2014 17:38
CONVERGENZA DEI PROTOCOLLI LINK-STATE - ASPETTI GENERALI, CARRIER-DELAY E IP EVENT DAMPENING
Un piccolo prologo. Nei giorni 26-27 Novembre scorso, abbiamo organizzato due seminari sul nuovo verbo del Software Defined Networking (SDN) e del suo "degno compare" Openflow, entrambi tenuti dal mitico Ivan Pepelnjak. Durante gli intervalli mi sono trovato a parlare con molti brillanti Ingegneri, esperti di reti IP e delle architetture dei Data Center. Tra una chiacchiera e l'altra, parlando del più e del meno, una persona ha fatto questa affermazione "Noi non utilizziamo OSPF nel nostro Data Center poiché converge in 40 secondi". Mi ha ricordato quelli che dicono che il BGP "converge in tre minuti" ! Dandogli una bonaria pacca sulla spalla, gli ho detto, guarda che quello che affermi era vero 20 anni fa, oggi i protocolli Link-State (OSPF e IS-IS), convergono in poche decine di millisecondi, a volte anche meno. E così ho preso spunto per una serie di Post, di cui questo è il primo, che vuole sfatare anche questo (pseudo-)mito.
ASPETTI GENERALI
Le reti IP hanno storicamente affrontato il problema del ripristino del servizio, tramite i protocolli di routing convenzionali (RIP, EIGRP, OSPF, IS-IS, ecc.). Questi sono stati progettati per riconfigurare automaticamente le tabelle di instradamento in caso di cambi della topologia della rete, dovuti al fuori servizio e/o ripristino del servizio di elementi di rete. Benché questi protocolli si siano dimostrati sul campo particolarmente efficaci, non sono in grado, per loro natura, di soddisfare i requisiti di velocità di ripristino del servizio richiesti dalle applicazioni real-time, come ad esempio la voce e il video diffusivo (broadcast) o interattivo. Infatti, nelle reti di grandi dimensioni, il tempo di convergenza dei protocolli di routing IP, ossia il tempo che intercorre tra la rilevazione di un cambio della topologia della rete e la determinazione delle nuove tabelle di instradamento, per quanto sceso nel tempo, se non si effettuano opportuni tuning, rimane ancora dell’ordine dei secondi, tempo troppo elevato per applicazioni di tipo mission-critical.
Questo è il primo di alcuni Post attraverso i quali illustrerò nuovi meccanismi che consentono di raggiungere l'obiettivo della sub-second convergence, ossia della convergenza in meno di un secondo nei protocolli Link-State. Per ciascun meccanismo illustrato cercherò anche di dare delle linee guida per il loro utilizzo.
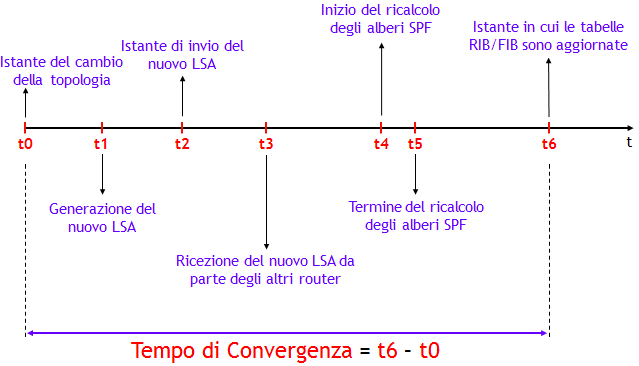
In un protocollo di routing Link-State, a grandi linee, il tempo di convergenza risulta dalla somma di 4 fattori (NOTA: per semplicità utilizzerò nel seguito per i "mattoncini" elementari del Link-State DataBase (LSDB) la terminologia LSA (Link State Advertisement), tipica di OSPF; l'analogo termine in IS-IS è LSP):
- Tempo per rilevare il cambio di topologia : può essere dell’ordine dei msec quando è possibile rilevare un fuori servizio a livello fisico, ma fino a tempi dell’ordine delle decine di secondi quando si fa affidamento sui messaggi HELLO del protocollo. Durante questo periodo di tempo, il traffico che in condizioni di funzionamento nominale avrebbe utilizzato il collegamento e/o nodo fuori servizio, viene inevitabilmente perso.
- Tempo di generazione, invio e propagazione dei LSA: questo tempo è dato dalla differenza tra l’istante in cui il nuovo LSA viene inviato, e la ricezione del nuovo LSA da parte degli altri router. In assenza di perdita dei LSA, i tempi di ritardo variano da una decina a circa un centinaio di msec per router attraversato. Si noti che per motivi di stabilità, dopo la generazione del nuovo LSA, vi è un ritardo nel suo invio (LSA-delay).
- Ricalcolo dei percorsi ottimi via SPF: l’applicazione dell’algoritmo di Dijkstra, nei moderni router, richiede tempi dell’ordine delle decine di msec, anche in presenza di un numero di centinaia di nodi e di centinaia di link. Vi è però un ritardo iniziale del calcolo, anche qui per motivi di stabilità (SPF-delay).
- Aggiornamento RIB e FIB : questo è un tempo che dipende molto dalla particolare piattaforma, e dal numero di prefissi che cambiano il proprio Next-Hop a causa del fuori servizio. Include anche il tempo di aggiornamento delle FIB sulle singole linecard, se applicabile. Come ordine di grandezza, si può pensare a un tempo di un centinaio di msec. Questo tempo dipende però fortemente dal numero di prefissi appresi attraverso il protocollo.
L’obiettivo delle reti moderne è quello di avere tempi di convergenza dell’ordine delle poche decine di msec, comparabili ad esempio a quelli garantiti dai sistemi di protezione dell'ormai vecchio standard SDH. Per questo sono stati sviluppati dei meccanismi che consentono di portare la velocità di convergenza al di sotto del secondo, e in alcuni casi di raggiungere tempi di convergenza dell’ordine delle poche decine di msec.
Con l’evoluzione delle piattaforme, l’affinamento del codice che implementa i protocolli di routing e l’introduzione di nuove funzionalità, i tempi di convergenza dei protocolli Link-State sono diminuiti di molto, passando dalle decine di secondi alle decine di millisecondi.
In passato, uno degli aspetti critici nell’implementazione di questo tipo di protocolli, era il tempo di ricalcolo dei percorsi ottimi attraverso l’algoritmo di Dijkstra. Il notevole aumento della capacità di elaborazione (la celebre legge di Moore !), insieme all’ottimizzazione del codice, ha portato, anche per reti di grandi dimensioni, a tempi dell'esecuzione dell’algoritmo di Dijkstra dell’ordine delle poche decine di msec. Inoltre, la maggiore stabilità dei collegamenti trasmissivi, ha consentito di ridurre notevolmente alcuni timer, che rappresentavano un collo di bottiglia per il tempo di convergenza.
Un altro aspetto fondamentale cambiato rispetto al passato, è che sono stati sviluppati criteri per rilevare più velocemente la perdita di una adiacenza. Infatti, fare affidamento sui timer associati ai messaggi HELLO, comporta tempi elevati per rilevare la caduta dell’adiacenza. Tempi che si potrebbero abbreviare agendo sui valori del periodo dei messaggi HELLO e sull'Holdtime associato, ma il prezzo da pagare è una maggiore occupazione della CPU. Tra le funzionalità introdotte per abbreviare in modo efficiente il tempo per rilevare la perdita di una adiacenza, ho già trattato ampiamente in Post passati il Bidirectional Forwarding Detection (BFD). In questo Post darò informazioni aggiuntive su questo aspetto.
Tra le funzionalità introdotte per l’ottimizzazione del tempo di convergenza, tratterò in Post successivi, le seguenti:
- Tuning dei timer: molti timer, in particolare LSA-delay e SPF-delay, hanno la possibilità di essere abbreviati notevolmente tramite meccanismi di Exponential Backoff o simili. (NOTA: come citato sopra, LSA-delay e SPF-delay sono rispettivamente, il ritardo di generazione di un LSA a fronte della ricezione di un cambio di topologia, e il ritardo di ricalcolo dell’albero SPF a fronte della ricezione di un LSA che annuncia un campio di topologia (NOTA nella NOTA: anche un cambio delle metriche associate alle interfacce viene interpretato come un cambio di topologia, e quindi ha come effetto la generazione di un nuovo LSA e il ricalcolo dei percorsi ottimi via SPF)).
- Ottimizzazione dell’algoritmo SPF: sono state introdotte metodologie come Incremental SPF e Partial Route Calculation, che consentono di non eseguire l’intero algoritmo quando non necessario.
- spf per-prefix prioritization: partendo dalla considerazione che non tutti i prefissi hanno la stessa importanza (es. un prefisso /32 di un router PE utilizzato per stabilire sessioni iBGP, è più importante di una subnet con cui si numera un collegamento punto-punto), sono stati introdotti meccanismi che consentono ai prefissi più importanti di essere trattati con precedenza rispetto a quelli meno importanti (e quindi finiscono nella RIB e FIB prima di altri prefissi !).
- Loop-Free Alternate: è una funzionalità che consente di inserire nella FIB anche un Next-Hop di backup, da utilizzare temporaneamente durante il tempo di convergenza.
Uno degli effetti indesiderati che si ha durante la convergenza di un protocollo di routing, è la formazione di micro-loop, ossia loop temporanei che si formano per brevi periodi, e che scompaiono una volta terminata la convergenza.
La formazione dei micro-loop è causata dallo sfasamento con cui i router determinano i nuovi percorsi ottimi. La figura seguente riporta un esempio del fenomeno.

Con le metriche riportate nella figura, il router A, per raggiungere il prefisso X ha come Next-Hop il router D, mentre il router D ha come Next-Hop il router E. Ora, si supponga che l’adiacenza tra i router D ed E cada, ad esempio per un fuori servizio del collegamento D-E. Come conseguenza, i router D ed E generano il loro nuovo Router Link LSA, per comunicare agli altri router la caduta dell’adiacenza.
A causa dei ritardi di propagazione sul collegamento D-A, che nelle applicazioni pratiche possono raggiungere tempi anche delle decine di msec, il router A riceverà gli LSA generati da D ed E, dopo che il router D ha determinato il nuovo percorso. Il nuovo Next-Hop di D per il prefisso X sarà necessariamente A, per cui, prima che A abbia ricalcolato il nuovo percorso, si verifica un evidente micro-loop. Infatti, A ha (prima del ricalcolo dell’SPF) Next-Hop D, e D ha come nuovo Next-Hop A.
Quanto sono dannosi i micro-loop ? Dipende dalla durata e dai servizi trasportati dalla rete. Nelle reti moderne, dove i timer dei protocolli, come vedremo nel seguito, sono ottimizzati, la durata di un micro-loop è dell’ordine delle decine o al più centinaia di msec, tollerabili dalla maggior parte dei servizi.
È possibile evitare i micro-loop ? Si, sarebbe sufficiente che ciascun nodo avesse, per ciascun prefisso raggiungibile, un Next-Hop alternativo già «pronto per l’uso», ossia precalcolato e presente nella FIB. Il Next-Hop alternativo dovrebbe garantire l’assenza di loop (ossia, essere loop-free) e consentire l’instradamento del traffico su un percorso alternativo (benché non ottimo !), per il tempo necessario alla rete a raggiungere una nuova e stabile situazione di convergenza. Questa funzionalità, nota come Loop-Free Alternate (LFA) è stata sviluppata dai principali costruttori, è oggetto di uno standard IETF, e sarà vista in un Post successivo (NOTA: il lettore familiare con il protocollo proprietario Cisco EIGRP, avrà notato una certa similitudine del LFA con i concetti di Successor e Feasible Successor di EIGRP. In realtà sono la stessa cosa, ma applicati in contesti completamente diversi. Un’altra nota idea simile al LFA, è il servizio Fast Rerouting, che si ha in MPLS-TE (MPLS Traffic Engineering). Altra idea analoga, per chi ha già letto il Post precedente, è la funzionalità BGP PIC).
CARRIER-DELAY
Dopo questa doverosa introduzione generale sulla convergenza dei protocolli di tipo Link-State, voglio trattare in questo Post il primo elemento fondamentale nel processo di convergenza: come minimizzare il tempo per rilevare la perdita di una adiacenza.
Ho già illustrato ampiamente nei precedenti Post il BFD, che trova il suo naturale scenario di applicazione nel caso di collegamenti costituiti da più segmenti come ad esempio PVC Frame Relay o ATM o VLAN Ethernet. Può anche essere utilizzato nel caso di collegamenti back-to-back per risolvere certi tipi di fuori servizio, per cui ne consiglio comunque l'utilizzo.
Nel caso di collegamenti back-to-back, in aggiunta al BFD, è possibile utilizzare un meccanismo di comunicazione "veloce" al protocollo di routing del fuori servizio di una interfaccia, simile al già visto BGP fast-external-fallover.
Nei router Cisco questo meccanismo viene indicato come carrier-delay, ed è il tempo che l’interfaccia attende prima di notificare al supervisor, che il collegamento è down oppure è ritornato nello stato up. Si noti che se una interfaccia va nello stato down e ritorna nello stato up prima della scadenza del carrier-delay, lo stato down viene “filtrato”, ossia non notificato al resto del software.
La configurazione del carrier-delay, nell'IOS/IOS-XR Cisco avviene tramite il seguente comando (NOTA: come sempre, fate attenzione alla versione IOS, il comando non è sempre uguale !):
(config)# interface tipo numero
(config-if)# carrier-delay down msec [up msec]
Per il significato delle parole chiave down e up, si consideri il seguente esempio nell'IOS-XR:
RP/0/RSP0/CPU0:(config)# interface gi0/1/0/0
RP/0/RSP0/CPU0:(config-if)# carrier-delay down 0 up 1000
Questa configurazione implica che la comunicazione di interfaccia down all’IOS avviene immediatamente, mentre un eventuale nuovo up, per mitigare l’effetto di eventuali link flap viene ritardato di 1 sec (= 1.000 msec). Come best-practice di solito si pone down = 0 msec, o nel caso di protezione ottica, a un valore leggermente superiore al tempo di protezione (50-60 msec). Si noti che in molte versioni IOS il valore di default del down è 2.000 msec (=2 sec), ma consiglio comunque sempre di verificare la documentazione Cisco.
Le interfacce POS (Packet Over SONET/SDH), possono fornire una protezione nativa in tempi molto brevi, tipicamente inferiori a 50 msec. Per queste interfacce, è opportuno porre il timer specifico della tecnologia POS, il delay trigger line, a un valore maggiore del tempo di protezione nativo, al fine di nascondere al Livello 3 un fuori servizio non-critico a livello fisico. Nel caso la protezione nativa non sia attivata, è bene porre il delay trigger line a un valore nullo.
Anche nelle interfacce POS è definito il carrier-delay. Il carrier-delay è il ritardo tra la rilevazione dell’assenza di segnale SONET/SDH (o la fine del delay trigger line) e l’update dell’interfaccia a livello IOS. È buona pratica porre questo ritardo sempre a un valore nullo, o come citato sopra, in presenza di protezione ottica a un valore leggermente superiore al tempo di protezione.
Nei router Juniper, è possibile configurare il carrier-delay con il comando seguente:
[edit interfaces interface-name]
tt@router# show
hold-time up msec down msec;
dove il significato delle parole chiave up e down è identico a quello visto per l'IOS Cisco.
IP EVENT DAMPENING
Per una protezione addizionale contro i link flap è bene poi attivare la funzionalità IP event dampening. Questa funzionalità, a grandi linee, è basata su un meccanismo “a memoria”, che permette al router, di costruire uno storico dell’instabilità di una interfaccia, sulla base del quale intraprendere azioni di fuori servizio "forzato" momentaneo dell’interfaccia, ossia, l'interfaccia viene comunque fatta rimanenre nello stato down per un certo tempo, indipendentemente dal suo possibile ritorno nello stato up.
Per definire un’interfaccia instabile, si utilizza un meccanismo di penalizzazione, basato su un valore di penalità, che viene incrementata di un valore costante (nei router Cisco pari a 1.000), in corrispondenza di un down dell'interfaccia.
Nell’intervallo di tempo tra due down successivi, il valore di penalità viene fatto decrescere esponenzialmente. L’andamento del valore di penalità nel tempo, risulta così simile a un tipico “dente di sega”, con il valore che incrementa di una quantità costante negli istanti di ritorno allo stato down dell'interfaccia, e che decrementa esponenzialmente tra due down successivi.
La costante che regola il decadimento esponenziale è denominata half-life, e rappresenta il tempo impiegato a dimezzare il valore di penalità corrente.
Superato un determinato limite, denominato suppress-limit, l’interfaccia viene “congelata”, ossia, viene forzata nello stato down anche se dovesse tornare nello stato up.
L’interfaccia potrà essere riutilizzata, se e solo se è soddisfatta almeno una delle due seguenti condizioni:
- Il valore di penalità scende al di sotto di un valore configurabile, denominato reuse-limit.
- Il tempo trascorso dall’istante in cui l’interfaccia è dichiarata “congelata”, supera il valore configurabile denominato max-suppress-time.
Infine, quando il valore di penalità scende sotto della metà del reuse-limit, la penalità viene azzerata.
(NOTA: per i cultori del BGP, questa funzionalità è stata mutuata dal meccanismo (standard) di stabilità BGP Route Flap Damping, descritto nella RFC 2439).
La funzionalità IP event dampening si configura nell'IOS tramite il comando:
(config)# interface tipo numero
(config-if)# dampening [half-life reuse-limit suppress-limit max-suppress-time]
dove i parametri temporali half-life e max-suppress-time sono espressi in secondi, e i valori di default dei 4 parametri sono [5 1000 2000 20].
Nell'IOS-XR il comando è identico ma i parametri temporali half-life e max-suppress-time sono espressi in minuti, e i valori di default dei 4 parametri sono [1 750 2000 4].
Per chi fosse interessato ad ulteriori approfondimenti sulla funzionalità IP event dampening, consiglio di dare un'occhiata a questo Post, dove tra l'altro potrete trovare una ottima discussione sulla scelta dei parametri.
Nel JUNOS la funzionalità IP event dampening, così come implementata nei router Cisco, non è invece supportata. Credo che gli Ingegneri Juniper ritengano sufficiente l'effetto anti-flapping del comando "hold-time ..." descritto sopra.
OTTIMIZZAZIONE DELLA COMUNICAZIONE DELLO STATO DELL'INTERFACCIA
Infine c'è un altro tuning interessante che è possibile eseguire. Di default nell'IOS, l'evento interfaccia down viene segnalato direttamente alla RIB. Questo implica che la RIB debba eseguire un processo di scanning per cercare i percorsi che hanno come Next-Hop l'interfaccia down, per poi rimuovere tutti i percorsi che hanno quel Next-Hop. Quindi, dopo questo processo viene informato il protocollo di routing, il quale riconverge dopo un certo tempo e quindi vengono riaggiornate RIB e FIB. Un processo che non è molto efficiente, poiché coinvolge due volte l'aggiornamento di RIB e FIB (di cui il primo evitabile). Questo comportamento, nelle versioni più recenti dell'IOS può essere cambiato in modo che a fronte del down dell'interfaccia, venga informato direttamente il protocollo di routing (e non la RIB !), in modo da avere un solo aggiornamento di RIB e FIB (quello a valle della convergenza del protocollo di routing). Nell'IOS, il comando che abilita questo comportamento è il seguente:
router(config)# ip routing protocol purge interface
Nell'IOS-XR questo comportamento "ottimizzato" è di default, quindi non ha bisogno di alcun comando di abilitazione.
Non ho trovato nel JUNOS un comando analogo, probabilmente perché il JUNOS implementa di default il comportamento ottimizzato descritto sopra, ma non l'ho trovato scritto da nessuna parte.
CONCLUSIONI
Con questo Post inizio una trilogia sulla convergenza dei protocolli di routing Link-State, ossia OSPF e IS-IS. Il contenuto di questo Post, nella sua seconda parte è in realtà generale, e si applica a tutti i protocolli di routing. Nei prossimi due illustrerò invece aspetti specifici dei protocolli Link-State.
Se ne volete sapere di più potete seguire i nostri corsi IPN232, IPN233 (entrambi per la tecnologia Cisco), IPN253 e IPN260 (per la tecnologia Juniper).
Pubblicato in
ReissBlog
Etichettato sotto
Domenica, 30 Novembre 2014 14:27
LA (LENTA) CONVERGENZA DEL BGP: UN MITO DA SFATARE - PARTE III
Con questo Post riprendo la mia "campagna di sensibilizzazione" sulla velocità di convergenza del BGP, sempre con lo scopo di sfatare l'atavico mito "che il BGP converge in tre minuti".
Nei due Post precedenti ho trattato due argomenti: il primo riguarda la velocità con cui viene rilevata la perdita di una sessione BGP, mentre il secondo consente di verificare velocemente la raggiungibilità del Next-Hop.
Questa volta tratterò altri due argomenti, uno sostanzialmente invisibile, ossia che non ha (quasi) impatto alcuno sulle configurazioni, mentre l'altro riguarda una funzionalità che invece va attivata su base configurazione.
Prima di trattare questi due ulteriori argomenti è però necessaria una premessa. Con quali criteri il piano di controllo BGP consente di convergere su un nuovo best-path ?
CONVERGENZA SUL PIANO DI CONTROLLO
In un classico backbone che utilizza una architettura di routing IGP+BGP (non importa se BGP core-free o meno, ossia con l'ulteriore aggiunta di MPLS o no), come quello rappresentato nella figura seguente:

si possono individuare tre scenari di fuori servizio, che comportano la convergenza del BGP su un nuovo best-path:
- Fuori servizio di elementi interni al backbone (router e/o collegamenti).
- Fuori servizio di Edge Router, che da qui in poi, con un piccolo abuso di notazione chiameremo router PE (Provider Edge).
- Fuori servizio di collegamenti PE-CE, dove i router CE (Customer Edge, anche qui stiamo forzando un po' la notazione) sono router esterni al backbone, che scambiano nel nostro esempio informazioni di routing con il backbone via eBGP.
Il primo scenario è rappresentato nella figura seguente:

Come avviene la convergenza verso un nuovo best-path ? Ho fatto una piccola prova di laboratorio per mostrare tutti i passi che portano il router PE11 a convergere verso un nuovo best-path, a fronte del fuori servizio del router P11. La rete è costituita da router Cisco con IOS 12.4(11)T. Tra i tre router PE, come mostrato nella figura, vi è una maglia completa di sessioni iBGP, mentre il router CE21 ha due sessioni eBGP verso i due router PE21 e PE22, ai quali annuncia il prefisso 10.1/16. Sui due router PE21 e PE22, ho inoltre attivato la funzione "next-hop self" sulle sessioni iBGP verso PE11. Per rendere la prova più interessante, infine, ho posto la metrica IGP dell'interfaccia del router P12 sul collegamento verso il router PE21, al valore 1.000. Tutte le altre metriche hanno valore 10.
Vediamo dapprima la tabella BGP di PE11:
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 2
Paths: (2 available, best #2, table Default-IP-Routing-Table)
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal
65101
192.168.0.21 (metric 21) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal, best
Come si può notare, PE11 sceglie come best-path il Next-Hop 192.168.0.21, a causa del più basso valore del BGP router-ID (lascio i dettagli al lettore come utile esercizio).
A questo punto, dopo aver attivato sul router PE11 i comandi "debug ip routing" e "debug ip bgp updates", ho spento completamente il router P11. Come c'era da aspettarsi, il BGP Next-Hop cambia (anche qui, lascio i dettagli al lettore come utile esercizio):
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 3
Paths: (2 available, best #1, table Default-IP-Routing-Table)
Flag: 0x800
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal, best
65101
192.168.0.21 (metric 31) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal
Questa è la parte interessante dei debug attivati su PE11:
*Nov 16 16:59:06.263: RT: del 192.168.0.21/32 via 172.20.11.11, ospf metric [110/21]
*Nov 16 16:59:06.267: RT: SET_LAST_RDB for 192.168.0.21/32
OLD rdb: via 11.13.11.13,
NEW rdb: via 172.20.13.12
*Nov 16 16:59:06.279: RT: add 192.168.0.21/32 via 172.20.13.12, ospf metric [110/31]
*Nov 16 16:59:06.283: RT: NET-RED 192.168.0.21/32
*Nov 16 16:59:06.299: RT: del 192.168.0.22/32 via 172.20.11.11, ospf metric [110/21]
*Nov 16 16:59:06.303: RT: SET_LAST_RDB for 192.168.0.22/32
OLD rdb: via 11.13.11.13,
NEW rdb: via 172.20.13.12, Serial1/2
*Nov 16 16:59:06.311: RT: NET-RED 192.168.0.22/32
*Nov 16 16:59:11.331: BGP(0): Revise route installing 1 of 1 routes for 10.1.0.0/16 -> 192.168.0.22(main) to main IP table
*Nov 16 16:59:11.335: RT: 10.1.0.0/16 gateway changed from 192.168.0.21 to 192.168.0.22
*Nov 16 16:59:11.339: RT: NET-RED 10.1.0.0/16
Come si può notare, il tempo di convergenza del BGP verso il nuovo BGP Next-Hop 192.168.0.22 (interfaccia Loopback 0 di PE22) è di poco più di 5 sec (di cui 5 sec imputabili al BGP Next-Hop Tracking (NHT) Trigger Delay). Faccio notare che se non avessi cambiato al valore 1.000 la metrica IGP dell'interfaccia del router P12 sul collegamento verso il router PE21, il BGP Next-Hop non sarebbe nemmeno cambiato.
Riassumendo, la sequenza delle operazioni sul router PE11 è la seguente:
- Il protocollo IGP rileva il fuori servizio delle adiacenze stabilite dal router P11 e determina, attraverso una nuova esecuzione dell'algoritmo SPF, i nuovi percorsi ottimi verso i due possibili BGP Next-Hop PE21 e PE22.
- Se il percorso verso il BGP Next-Hop ottimo cambia, il protocollo IGP lo notifica al processo BGP, viceversa non accade niente.
- PE11 identifica tutti gli annunci BGP con il BGP Next-Hop di cui è variato il percorso, e quindi esegue immediatamente un nuovo processo per la selezione del best-path. Questo tempo è proporzionale al numero di prefissi IP annunciati via BGP e potrebbe essere abbastanza lungo.
- Determinato il nuovo best-path, PE11 aggiorna sia RIB che FIB e il traffico continua a fluire, ma su un percorso diverso.
Il secondo scenario prevede il fuori servizio di un router PE, come mostrato nella figura seguente:
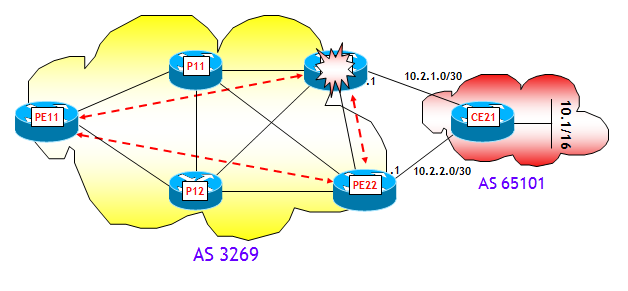
Anche qui ho fatto un test di laboratorio, con la stessa identica configurazione di rete, e dopo aver riportato al valore iniziale 10 la metrica IGP del collegamento P12-->PE21. Inizialmente il best-path per il prefisso 10.1/16 è il router PE21 (per la stessa identica ragione dello scenario precedente; faccio notare che la variazione della metrica del collegamento P12-->PE21 non ha alcuna influenza nella determinazione del best-path, (il perché lo lascio ancora al lettore, che alla fine del Post forse mi odierà per tutto ciò !)):
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 2
Paths: (2 available, best #2, table Default-IP-Routing-Table)
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal
65101
192.168.0.21 (metric 21) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal, best
A questo punto, dopo aver attivato sul router PE11 gli stessi debug dello scenario precedente, ho spento completamente il router PE21, ossia il BGP Next-Hop ottimo (se avessi spento il router PE22 in luogo del router PE21, non sarebbe accaduto niente in termini di convergenza del BGP). Come c'era da aspettarsi, su PE11 il BGP Next-Hop cambia e il piano di controllo del BGP converge al nuovo (e unico rimasto) BGP Next-Hop 192.168.0.22:
PE11# show bgp ipv4 unicast 10.1.0.0
BGP routing table entry for 10.1.0.0/16, version 7
Paths: (2 available, best #1, table Default-IP-Routing-Table)
Not advertised to any peer
65101
192.168.0.22 (metric 21) from 192.168.0.22 (192.168.0.22)
Origin IGP, metric 0, localpref 100, valid, internal, best
65101
192.168.0.21 (inaccessible) from 192.168.0.21 (192.168.0.21)
Origin IGP, metric 0, localpref 100, valid, internal
Per vedere il tempo impiegato, analizziamo la parte interessante dei debug attivati su PE11:
*Nov 16 17:49:37.023: RT: del 192.168.0.21/32 via 172.20.11.11, ospf metric [110/21]
*Nov 16 17:49:37.027: RT: NET-RED 192.168.0.21/32
*Nov 16 17:49:37.031: RT: del 192.168.0.21/32 via 172.20.13.12, ospf metric [110/21]
*Nov 16 17:49:37.035: RT: delete subnet route to 192.168.0.21/32
*Nov 16 17:49:37.039: RT: NET-RED 192.168.0.21/32
*Nov 16 17:49:42.059: BGP(0): Revise route installing 1 of 1 routes for 10.1.0.0/16 -> 192.168.0.22(main) to main IP table
*Nov 16 17:49:42.063: RT: 10.1.0.0/16 gateway changed from 192.168.0.21 to 192.168.0.22
*Nov 16 17:49:42.067: RT: NET-RED 10.1.0.0/16
Come si può notare, anche in questo caso, il tempo di convergenza del BGP verso il nuovo BGP Next-Hop 192.168.0.22 (interfaccia Loopback 0 di PE22) è di poco più di 5 sec (di cui 5 sec imputabili al BGP NHT Trigger Delay).
Riassumendo, la sequenza delle operazioni sul router PE11 è la seguente:
- Il protocollo IGP rileva la non raggiungibilità del router PE21, che è il BGP Next-Hop ottimo.
- Il protocollo IGP notifica al processo BGP che il percorso verso il router PE21 non è più valido (funzionalità BGP NHT).
- PE11 identifica tutti gli annunci BGP con il BGP Next-Hop non più raggiungibile, e quindi esegue immediatamente un nuovo processo per la selezione del best-path.
- Determinato il nuovo best-path, PE11 aggiorna sia RIB che FIB e il traffico continua a fluire, ma su un percorso diverso.
Prima di passare al terzo scenario, vorrei far notare un aspetto chiave: il tempo di convergenza verso il nuovo BGP Next-Hop, in entrambi gli scenari finora descritti, dipende esclusivamente dalla velocità di convergenza del protocollo IGP. Il piano di controllo BGP interviene solo con il BGP NHT Trigger Delay, che se azzerato non ha alcuna influenza, come visto nel Post precedente sul BGP NHT. Quindi in questi scenari, la velocità di convergenza del BGP è praticamente identica alla velocità di convergenza del protocollo IGP (che se opportunamente configurato, non converge in tre minuti, ma in tempi dell'ordine delle decine o poche centinaia di msec !!!).
Il terzo e ultimo scenario prevede il fuori servizio di un collegamento PE-CE, come mostrato nella figura seguente:

Anche qui ho fatto un test di laboratorio, con la stessa identica configurazione di rete degli scenari precedenti.
Ricordo che sui router PE21 e PE22 è attivo il comando "neighbor <PE11> next-hop-self". Inizialmente il best-path per il prefisso 10.1/16, come visto nella prova dello scenario precedente, è il router PE21.
A questo punto, dopo aver attivato sul router PE11 i soliti debug, ho messo in shutdown l'interfaccia lato PE21 del collegamento PE21-CE21 (si noti che se avessi messo invece in shutdown l'interfaccia lato PE22 del collegamento PE22-CE21, non sarebbe accaduto niente in termini di convergenza del BGP). Come c'era da aspettarsi, su PE11 il BGP Next-Hop cambia e il piano di controllo del BGP converge al nuovo BGP Next-Hop 192.168.0.22:
PE11# show bgp ipv4 unicast 10.1.0.0
BGP table version is 3, local router ID is 192.168.0.11
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
*>i10.1.0.0/16 192.168.0.22 0 100 0 65101 i
Per vedere il tempo impiegato, analizziamo la parte interessante dei debug attivati su PE11:
*Nov 16 19:08:12.355: BGP(0): 192.168.0.21 rcv UPDATE about 10.1.0.0/16 -- withdrawn
*Nov 16 19:08:12.367: BGP(0): Revise route installing 1 of 1 routes for 10.1.0.0/16 -> 192.168.0.22(main) to main IP table
*Nov 16 19:08:12.371: RT: 10.1.0.0/16 gateway changed from 192.168.0.21 to 192.168.0.22
*Nov 16 19:08:12.375: RT: NET-RED 10.1.0.0/16
L'analisi dei debug consente una prima osservazione molto importante: la velocità di convergenza, a differenza dei due scenari precedenti, non dipende dalla convergenza del protocollo IGP, ma esclusivamente dal piano di controllo BGP. Questo accade a causa della presenza del comando "neighbor <PE11> next-hop-self" sui router PE21 e PE22. Infatti, questo comporta che il router PE11 vede come BGP Next-Hop gli indirizzi 192.168.0.21 (PE21) e 192.168.0.22 (PE22), e non gli indirizzi lato CE dei collegamenti punto-punto PE-CE, per cui il fuori servizio dei collegamenti PE-CE non ha alcun impatto sui BGP Next-Hop visti da PE11. La convergenza avviene quindi solo grazie allo scambio di messaggi BGP. In particolare ciò che avviene è che a fronte dello shutdown dell'interfaccia lato PE21 del collegamento PE21-CE21, grazie alla funzionalità "bgp fast external fall-over" vista nel primo Post sulla convergenza del BGP, la sessione BGP PE21-CE21 viene immediatamente disattivata e quindi PE21 invia ai suoi BGP peer PE11 e PE22, un messaggio BGP UPDATE per ritirare il prefisso 10.1/16 (in generale, tutti i prefissi appresi da CE21). A fronte di ciò, PE11 ricalcola il nuovo best-path (si noti che per PE22 il best-path non cambia !), che come visto sopra, è il Next-Hop 192.168.0.22 (PE22). Anche PE21 ricalcola il nuovo best-path, che anche in questo caso diventa il Next-Hop 192.168.0.22 (PE22). Su PE11 tutto ciò avviene in 20 msec ! (NOTA: in realtà a questo tempo bisognerebbe aggiungere il tempo di generazione del messaggio BGP UPDATE da parte di PE21, e il tempo di propagazione dello stesso da PE21 a PE11, ma sono tempi molto piccoli). Questo tempo di convergenza così piccolo è però ingannevole, perché in generale dipende dal numero di prefissi che CE21 annuncia all'AS 3269. Se CE21 annunciasse l'intera Full Internet Routing Table il discorso sarebbe ben diverso, perché PE21 dovrebbe rieseguire il processo di selezione per centinaia di migliaia di prefissi !
Ribadisco però il punto chiave, la convergenza avviene esclusivamente a livello BGP, la funzionalità BGP NHT in questo caso non aiuta poiché per PE11 il BGP Next-Hop rimane regolarmente nella Tabella di Routing.
Cosa avverrebbe se noi togliessimo il comando "neighbor <PE11> next-hop-self" sui router PE21 e PE22 ? Innanzitutto è necessario redistribuire nel protocollo IGP le subnet IP utilizzate nella numerazione dei collegamenti punto-punto PE-CE, oppure in alternativa farle partecipare al processo IGP (possibilmente con un passive-interface sull'interfaccia lato PE !), altrimenti PE11, vedrebbe i BGP Next-Hop irraggiungibili. Fatto ciò, i BGP Next-Hop diventano gli indirizzi IP lato CE dei collegamenti punto-punto PE-CE. Il fuori servizio del collegamento PE21-CE21 comporta in questo caso che il protocollo IGP ritiri dalla Tabella di Routing di PE11 la subnet IP con cui è numerato il collegamento PE21-CE21, e quindi entra in funzione il BGP NHT. In generale, in topologie con un grande numero di annunci BGP questo comporta indubbiamente un notevole vantaggio in termini di convergenza. Quando invece il numero di annunci BGP è basso, i vantaggi in termini di velocità di convergenza sono compensati dagli svantaggi della redistribuzione della subnet dei collegamenti PE-CE nel protocollo IGP (incremento della memoria necessaria per i LSDB, della dimensione delle Tabelle di Routing, possibili problemi di sicurezza, ecc.).
Riassumendo quanto visto finora, in due dei tre scenari descritti (nel primo e secondo), la velocità di convergenza del BGP dipende essenzialmente dalla velocità di convergenza del protocollo IGP (e questo già sfata il mito che il BGP è molto più lento a convergere dei protocolli IGP), mentre nel terzo dipende dal piano di controllo BGP. In tutti gli scenari comunque, il processo BGP viene avvisato di un cambiamento, e deve effettuare uno scanning della Tabella BGP per individuare tutti i prefissi affetti dal cambiamento. Questo processo di scanning, benché event-driven, comporta un tempo proporzionale al numero di prefissi IP. Il processo potrebbe essere ottimizzato (vedi ad esempio gli scoped walks nell'IOS XR), ma il tempo rimane comunque dipendente dal numero di prefissi annunciati. L'ideale sarebbe avere un processo indipendente dal numero di prefissi, ed è questo che tratteremo nelle prossime sezioni.
FIB FLAT E FIB GERARCHICHE
Un aspetto molto importante per la convergenza, ma invisibile dall'esterno, è come è organizzata la FIB (Forwarding Information Base), ossia la tabella (tipicamente hardware) che il router utilizza per la commutazione dei pacchetti. La costruzione della FIB a partire dalle informazioni contenute nella RIB (Routing Information Base, meglio nota come Tabella di Routing) utilizza algoritmi vendor-dependent (CEF Cisco, PFE Juniper, ecc.) (NOTA: sentito mai parlare di Openflow ? E' un nuovo protocollo che nella mente dei suoi ideatori dovrebbe rendere standard il protocollo di comunicazione RIB-FIB, ossia di rendere standard il colloquio "piano di controllo - piano dati").
La FIB può avere una architettura flat oppure gerarchica. Nell'architettura flat, ogni prefisso presente nella FIB (sia esso appreso via BGP o IGP) ha associate le informazioni per il forwarding (interfaccia di uscita, MAC rewrite, etichette MPLS, ed eventualmente altro, se necessario, vedi figura seguente). Le informazioni per il forwarding vengono spesso anche dette Direct Next-Hop.
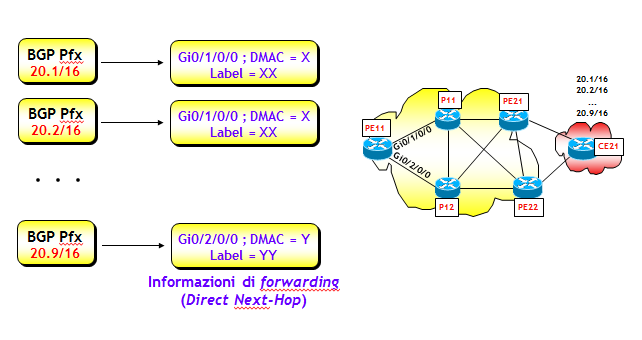
Una architettura flat non è però molto efficiente, poiché un qualsiasi cambio che riguarda il Direct Next-Hop, richiede l'aggiornamento di tutti i prefissi associati a quel Direct Next-Hop. Ovviamente, con questo tipo di architettura, il tempo di aggiornamento della FIB dipende dal numero di prefissi presenti nella stessa, e può diventare molto elevato. Se la FIB ha solo un centinaio di prefissi, anche una architettura flat va bene, ma se il numero di prefissi fosse dell'ordine delle centinaia di migliaia, l'aggiornamento potrebbe richiedere anche più di un minuto ! Le FIB con architettura flat potevano andar bene 20 anni fa, quando la Full Internet Routing Table aveva meno di 10k prefissi. Nelle reti IP del 21-esimo secolo, dove la Full Internet Routing Table supera le 500k righe, è necessario adottare un approccio diverso. L'architettura della FIB è stata così riprogettata per rendere il suo aggiornamento più veloce. L'idea è organizzarla su tre livelli gerarchici:
Prefisso --> Puntatore --> Informazioni di forwarding
dove il puntatore, spesso anche detto Indirect Next-Hop, altro non è nel nostro caso che un BGP Next-Hop, come mostrato anche nella figura seguente (in realtà alcuni costruttori utilizzano come Indirect Next-Hop un numero scelto internamente dal router, ma per capire meglio i concetti che stò esponendo, è più semplice considerarlo come fosse un BGP Next-Hop). Uno (o più, nel caso di BGP multipath) di questi puntatori (puntatore attivo) è quello effettivamente utilizzato per determinare le informzioni di forwarding. L'associazione "Puntatore --> Informazioni di forwarding" viene determinata (tipicamente) da un protocollo IGP.
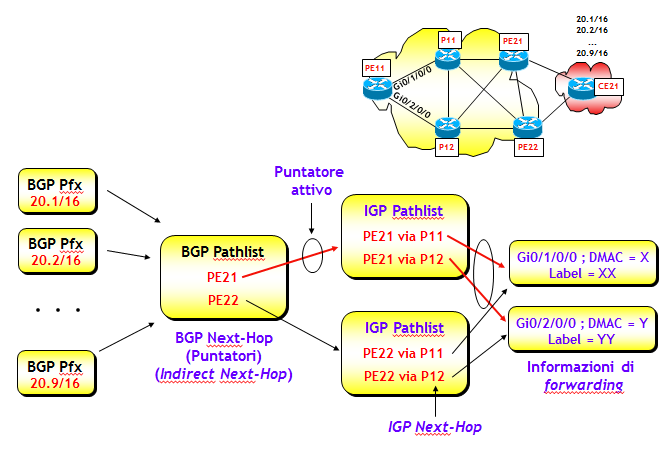
Per capire perché questa semplice idea migliori di molto le proprietà di convergenza della FIB, mostrerò cosa accade nel caso dei tre scenari descritti nella sezione precedente. Per tutti gli scenari ipotizzerò che CE21 annunci i prefissi 20.X/16, X=1, ..., 9, e senza perdita di generalità supporrò che tutti i prefissi 20.X/16 siano raggiungibili da PE11, attraverso lo stesso BGP Next-Hop PE21 (che è quindi il puntatore inizialmente attivo).
Consideriamo il primo scenario, ipotizzando come prima, il fuori servizio del router P11.
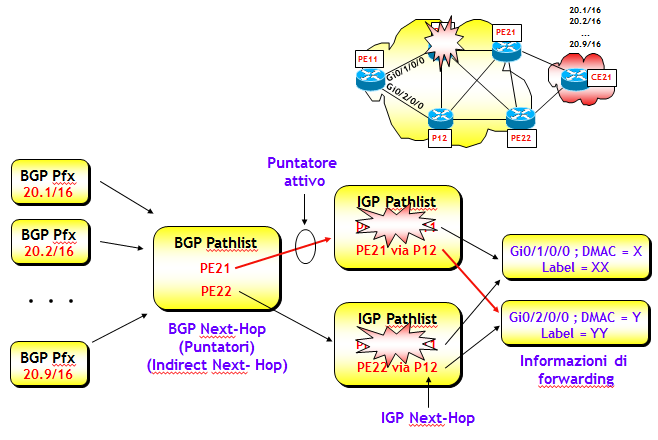
Sul router di edge in ingresso PE11, il protocollo IGP determina velocemente i nuovi percorsi ottimi verso i router PE21 e PE22, e quindi la FIB aggiorna l'IGP Pathlist. I puntatori (BGP Next-Hop) non cambiano, l'unica cosa che potrebbe cambiare a livello di puntatori è il loro utilizzo, che dipende dai nuovi costi IGP verso i BGP Next-Hop. Ma l'eventuale cambio del puntatore può avvenire solo a valle di un nuovo processo di selezione BGP, che è compito del piano di controllo BGP.
Se prima del fuori servizio del router P11 veniva utilizzato come puntatore attivo PE21, dopo la convergenza del piano di controllo BGP la FIB potrebbe utilizzare come puntatore attivo PE22, se il nuovo costo IGP verso PE22 risultasse inferiore rispetto a quello verso PE21. Ma durante la convergenza del piano di controllo BGP, la FIB continua a utilizzare lo stesso puntatore precedente (ossia PE21).
La convergenza è immediata e, si badi bene, non dipende in alcun modo dal piano di controllo BGP, né quindi dal numero di prefissi BGP, ma solo dalla velocità di convergenza del protocollo IGP, ma su questo aspetto tornerò ampiamente nella prossima sezione. Faccio notare inoltre che in questo scenario, la presenza di un puntatore alternativo non è in realtà necessaria. Infatti, qualora non vi sia, il traffico continuerebbe a fluire sempre verso l'unico BGP Next-Hop, solo che utilizzerebbe un percorso interno diverso.
Consideriamo ora il secondo scenario, ipotizzando il fuori servizio del router di edge PE21.

Anche qui, il protocollo IGP, secondo i suoi tempi di convergenza, informa velocemente i router di edge PE11 e PE22 che PE21 non è più raggiungibile. A fronte di questa nuova situazione, la FIB elimina il puntatore verso PE21 e redirige il traffico immediatamente, utilizzando il secondo puntatore disponibile, che diventa così attivo. In questo caso, a differenza del precedente, entra in funzione anche il BGP NHT, che attiva la convergenza sul piano di controllo BGP. Ma se anche questa fosse lunga, il traffico comunque continuerebbe nel frattempo a fluire regolarmente grazie alla disponibilità del secondo puntatore, che come detto sopra, entra in funzione immediatamente. In questo scenario, la convergenza al nuovo puntatore attivo è immediata e avviene direttamente sul piano dati, senza l'intervento del piano di controllo BGP. Inoltre, i tempi di convergenza non dipenderebbero dal numero di prefissi, ma solo dalla velocità di convergenza del protocollo IGP.
Infine, consideriamo il terzo scenario, ipotizzando il fuori servizio del collegamento PE21-CE21. In questo scenario ipotizzerò che i due router di edge PE21 e PE22 utilizzino il comando "neighbor <PE11> next-hop-self" e che l'indirizzo utilizzato per le sessioni iBGP sia un proprio indirizzo dell'interfaccia Loopback 0. Come già visto sopra, questo è un caso diverso dai due precedenti poiché il fuori servizio del collegamento PE21-CE21 non ha alcun impatto sui puntatori né sulle IGP Pathlist. Però il router di edge PE21 può sfruttare la sua FIB gerarchica e cambiare immediatamente il suo puntatore da CE21 a PE22. Il traffico da PE11 verso i prefissi annunciati da CE21 seguirà quindi il percorso PE11-->PE21-->PE22-->CE21, come mostrato nella figura seguente.
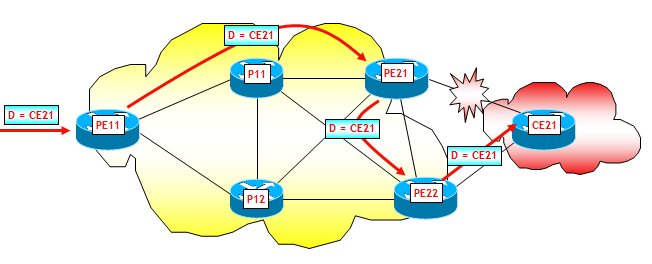
Attenzione che questo passaggio potrebbe però generare dei forwarding loop, seppur temporanei (anche detti micro-loop, vedi sezione "ALCUNI ASPETTI PROGETTUALI") ! Anche qui, su PE21 però e non su PE11, entra in funzione il BGP NHT, che attiva il piano di controllo BGP e la riconvergenza di PE11 sul secondo BGP Next-Hop disponibile. Anche qui, se pure questa convergenza fosse lunga, il traffico comunque continuerebbe nel frattempo a fluire regolarmente grazie alla disponibilità del secondo puntatore sul router PE21, che come appena detto entra in funzione immediatamente. Terminata la convergenza del piano di controllo BGP, il traffico continuerà a fluire, ma seguendo il percorso più "naturale" PE11-->PE22-->CE21.
In tutti i tre scenari, l'utilizzo di una FIB gerarchica consente di ridurre a livelli dell'ordine delle poche decine di msec il tempo di convergenza, o meglio, il tempo di perdità della connettività (LoC, Loss of Connettivity).
Nelle moderne piattaforme di routing, l'utilizzo delle FIB con architetture gerarchiche è pervasivo e spesso non richiede speciali comandi di configurazione. Per questo ho scritto sopra, che questo è un aspetto molto spesso invisibile dall'esterno.
Ora però viene il bello, perché il lettore attento avrà notato che la storia non finisce qui, infatti manca un tassello fondamentale. A meno di non abilitare il BGP multipath (se possibile !) nel secondo e terzo scenario, come fa l'algoritmo di gestione della FIB a conoscere il BGP Next-Hop alternativo ? E poi, ma questo BGP Next-hop alternativo siamo sicuri che sia sempre disponibile ? Senza la presenza di un BGP Next-Hop alternativo, la FIB deve necessariamente ricorrere al piano di controllo BGP per averne un altro. E questo allungherebbe di molto la convergenza, rendendo l'utilizzo delle FIB gerarchiche praticamente inutile.
BGP PREFIX INDEPENDENT CONVERGENCE (BGP PIC)
Supponiamo per il momento di trascurare il problema, e di partire dall'ipotesi che il BGP Next-Hop alternativo sia disponibile. Su questo problema però dovrò necessariamente ritornare, perché l'ipotesi che sto facendo in molti casi non corrisponde al vero (il lettore può intanto pensare in quali casi), per cui è necessario inventarsi qualcosa di nuovo (o qualche diabolico trucco sfruttando funzionalità "classiche") affinché ciò avvenga, e questo sarà l'oggetto principale di vari Post successivi, perché i metodi proposti sono molteplici.
Già sappiamo che il BGP NHT è in grado di rilevare velocemente la perdita di un BGP Next-Hop, e che questa informazione attiva un switchover locale al nuovo BGP Next-Hop. Questo switchover, qualora si utilizzi una architettura gerarchica della FIB, non richiede alcuno scanning della Tabella BGP e nessuna rielezione del best-path, ma semplicemente un cambio di puntatore.
Il processo di switchover non dipende quindi dal numero di prefissi presenti nella FIB, ma è piuttosto una semplice operazione che avviene a livello di FIB, ossia di piano dati. Per questa ragione, questa funzionalità viene indicata come Prefix Independent Convergence (PIC).
Nel primo scenario descritto nella sezione precedente si parla di funzionalità BGP PIC Core, e in questo scenario avere un BGP Next-Hop alternativo non è strettamente necessario (anche se spesso si ha comunque per motivi di fault-tolerance). Questo perché, in ogni caso, il BGP Next-Hop attualmente in uso è sempre disponibile, non avendo il fuori servizio di un elemento interno alla rete alcun impatto sulla sua raggiungibilità, ma ha impatto solo sul percorso interno per raggiungerlo (ovviamente, sempre che il backbone sia stato progettato correttamente, con magliatura sufficiente a garantire una buona disponibilità di cammini interni multipli che evitino partizioni del backbone stesso). Successivamente, il piano di controllo BGP potrebbe anche scegliere un nuovo BGP Next-Hop, se ritenuto più conveniente, ma questo è un problema del piano di controllo BGP, senza alcun impatto sulla convergenza sul piano dati.
Negli altri due scenari, la disponibilità di un BGP Next-Hop alternativo è vitale, perché se il BGP Next-Hop attivo diviene irraggiungibile, è necessario averne uno di riserva "pronto all'uso", altrimenti bisogna ricorrere al piano di controllo BGP per trovarne uno alternativo, allungando i tempi di convergenza. In questi due scenari si parla di funzionalità BGP PIC Edge.
Questa idea del BGP PIC non è nuova ed è già stata applicata in passato per la prima volta nel noto protocollo di routing proprietario Cisco EIGRP, dove insieme al Next-Hop primario (Successor) nella FIB viene inserito anche un Next-Hop alternativo loop-free (Feasible Successor). Per i più aggiornati, questa funzionalità è oggi presente anche nei protocolli di routing di tipo Link-State (OSPF e IS-IS), con il nome di LFA (Loop Free Alternate).
Si noti comunque che questo non significa che la normale convergenza sul piano di controllo BGP non avvenga, ma solo che è possibile utilizzare immediatamente un Next-Hop alternativo, già preinstallato nella FIB, riducendo così drasticamente la perdita di traffico durante la convergenza del piano di controllo.
Per chi fosse a conoscenza del funzionamento del servizio MPLS-TE Fast-ReRoute, questo è analogo a quanto avviene durante il fuori servizio di un nodo o collegamento parte di un tunnel MPLS-TE principale: il traffico ritenuto importante, ossia quello da proteggere, scorre momentaneamente su un tunnel MPLS-TE di backup preinstallato, che evita il nodo o collegamento fuori servizio. Il tunnel di backup viene però utilizzato fino a quando l'Edge-LSR che origina il tunnel principale non determina un percorso alternativo, lo segnala (via RSVP-TE) e quindi ci inoltra il traffico.
In una vecchia presentazione di Clarence Filsfils di Cisco, potete trovare una prova interessante che mostra come in uno scenario in cui un AS che ha due sessioni BGP con un altro AS, e riceve da questo la Full Internet Routing Table (a quel tempo di circa 350k prefissi, oggi di più di 530k prefissi), grazie alla funzionalità PIC, un router (Cisco 12k) connesso con due sessioni iBGP ai due router di edge con l'altro AS, impiegava solo 180 msec a convergere sul Next-Hop alternativo,mentre senza la funzionalità PIC, il tempo di convergenza diventava dell'ordine delle decine di secondi.
ALCUNI ASPETTI PROGETTUALI
Quando si parla di BGP PIC, sostanzialmente si parla di convergenza sul piano dati, invece che sul piano di controllo. Quindi uno potrebbe pensare che non vi sia da prendere alcun accorgimento progettuale. Non è proprio così, perché per raggiungere tempi convergenza dell'ordine delle decine di msec, qualcosa da fare c'è:
- Poiché nei vari scenari descritti sopra, in particolare nei primi due, il tempo di convergenza del BGP è strettamente legato al tempo di convergenza del protocollo IGP, è necessario eseguire un opportuno tuning del protocollo IGP, mettendo in campo tutte le funzionalità disponibili che consentono di ottenere una convergenza veloce.
- E' necessario fare attenzione a possibili forwarding (micro-)loop, che possono verificarsi in scenari non BGP core-free.
- Nello scenario BGP PIC Edge, è necessario assicurarsi la presenza di un BGP Next-Hop di backup (alternativo).
Quest'ultimo aspetto l'ho citato sopra e sarà l'oggetto di Post futuri. Per quanto riguarda il primo, in realtà per questo Post è fuori tema. Per completezza voglio solo dare qualche suggerimento, ma tenete conto che in seguito tratterò diffusamente su questo blog gli aspetti di convergenza di OSPF e IS-IS:
- Utilizzate sempre meccanismi che consentano di rilevare il più velocemente possibile la perdita di una adiacenza (BFD, Carrier-delay). Evitate di fare affidamento su meccanismi tipo fast-hello, che potrebbero sovraccaricare troppo la CPU dei router.
- Eseguite un tuning efficiente dei timer di generazione dei LSA/LSP e di ricalcolo via SPF dei percorsi ottimi. Già da solo questo accorgimento, insieme a quello del punto precedente, consente di portare il tempo di convergenza al di sotto del secondo.
- Partendo dalla considerazione che non tutti i prefissi hanno la stessa importanza (es. un prefisso /32 di un router PE utilizzato per stabilire sessioni iBGP, è più importante di una subnet con cui si numera un collegamento punto-punto), configurate meccanismi tipo "spf per-prefix prioritization", in modo tale che i prefissi più importanti vengano trattati con precedenza rispetto a quelli meno importanti (e quindi finiscono per primi nelle RIB e FIB !).
- Mantenete il vostro protocollo snello e pulito, evitando di redistribuire all'interno subnet IP non necessarie ed evitando funzionalità che non danno alcun valore aggiunto.
- Valutate, se la topologia della rete lo consente, l'introduzione in rete di funzionalità tipo LFA (Loop Free Alternate).
Per quanto riguarda il secondo aspetto, voglio solo farvi vedere come potrebbero formarsi dei forwarding micro-loop e quali sono le contromisure da adottare. Considerate la rete che ho utilizzato sopra per le prove di laboratorio, ma a differenza di quanto visto finora, supponiamo di attivare anche sessioni iBGP (con "next-hop-self" attivo) tra ogni router PE e i router interni di transito P, ad esempio, tra PE21 e i due router P11 e P12 (vedi figura seguente, dove per evitare di pasticciarla ho solo disegnato le sessioni iBGP che hanno come estremo comune PE21). Ora, con questo progetto di rete, anche il router P12 riceverà gli annunci iBGP da PE21 e PE22 per i prefissi originati da CE21. Supponiamo che P12 scelga come best-path PE21 e che il collegamento PE21-CE21 vada fuori servizio. Come già visto sopra, il router PE21 redirige il traffico diretto a CE21 utilizzando come Next-Hop (remoto) il router PE22, supponiamo passando per P12 (possibile, a causa delle metriche IGP). Se P12 non avesse ancora ricevuto dal piano di controllo BGP il ritiro del prefisso originato da CE21, e quindi non avesse ancora determinato il nuovo best-path, cosa tra l'altro molto probabile poiché PE21 può sfruttare la funzionalità PIC ma P12 no, e tra l'altro P12 non può nemmeno sfruttare la funzionalità BGP NHT (perché ?), P12 rimanderebbe il traffico indietro a PE21, generando così un micro-loop.
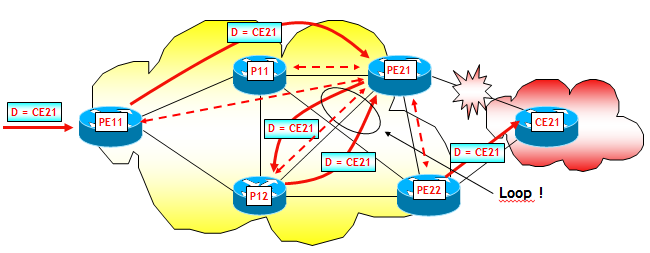
Il micro-loop cessa non appena anche P12 riceve dal piano di controllo BGP il ritiro del prefisso originato da CE21.
Come è possibile evitare questi micro-loop ? Io consiglio sempre di progettare un backbone BGP core-free, utilizzando MPLS all'interno (ricordo che BGP core-free significa che i router interni non hanno bisogno del BGP !). Così facendo, i router P agiscono solo come strumenti di collegamento tra i router PE e non hanno accesso al contenuto del payload MPLS, e quindi non possono rimandare i pacchetti indietro. Altri artifici come i tunnel GRE li sconsiglio, anche se possono, teoricamente, essere utilizzati.
CONFIGURAZIONE DELLA FUNZIONALITA' PIC NELLE PIATTAFORME CISCO
Per abilitare l'installazione nella FIB di un Next-Hop di backup, sempre che questo sia disponibile (ma io sto ipotizzando che sia disponibile !), è necessaria una opportuna configurazione.
Vediamo dapprima l'ambiente Cisco. Innanzitutto è necessario accertarsi che la piattaforma che si sta configurando abbia o no abilitata una FIB gerarchica (la funzionalità PIC senza una FIB gerarchica non ha molto senso !).
Come spesso accade nell'ambiente Cisco, è necessario fare attenzione al tipo di piattaforma. La FIB gerarchica in alcune piattaforme è abilitata di default (es. CRS, XR12k ASR9k, NX-OS), e quindi per queste non vi è bisogno di alcun comando particolare di configurazione, mentre in piattaforme tipo serie 7600, ASR1k, la FIB gerarchica va abilitata con il (terribile) comando globale "cef table output-chain build favor convergence-speed".
Per la funzionalità BGP PIC core non vi è bisogno d'altro, mentre per la funzionalità BGP PIC Edge è necessario abilitare l'installazione nella FIB di un Next-Hop di backup. Nell'IOS vi sono due modalità di BGP PIC Edge, multipath e unipath. La modalità multipath, che si ha in uno scenario active/active (ossia, quando entrambi i BGP Next-Hop disponibili sono utilizzati per inoltrare il traffico) non richiede alcuna configurazione particolare, se non la classica abilitazione del BGP multipath attraverso il comando "maximum-paths ..." a livello di processo BGP. La modalità unipath, tipica di uno scenario active/standby, richiede invece il comando (NOTA: in qualche caso la modalità unipath viene abilitata automaticamente previa abilitazione di un'altra funzionalità, come ad esempio nel caso della funzionalità BGP best-external, che sarà trattata in uno dei prossimi Post):
router bgp AS
address-family {ipv4 [vrf ...] | vpnv4 | ipv6}
bgp additional-paths install
Nell'IOS-XR la configurazione è un po' più articolata e richiede una routing policy (forse aperta a futuri sviluppi):
route-policy NOME-RP
set path-selection backup 1 install [... opzioni omesse...]
end-policy
!
router bgp AS
address-family {ipv4 [vrf ...] | vpnv4 | ipv6 [vrf ...] | vpnv6} unicast
additional-paths selection route-policy NOME-RP
Utilizzando il solito nostro glorioso GSR 12416 con IOS-XR 4.2.4, l'unica piattaforma del nostro Lab in grado di supportare la funzionalità PIC, ho eseguito un piccolo test. Ho fatto in modo che questo router, che ho chiamato PE2-3,ricevesse due annunci di due diversi percorsi verso il prefisso 10.1.99.12/32, il primo con BGP Next-Hop (remoto) 192.168.0.11 (risultato best-path) il secondo con BGP Next-Hop (sempre remoto) 192.168.0.12. Ho quindi abilitato la funzionalità PIC con i seguenti comandi:
route-policy REISS-BACKUP
set path-selection backup 1 install
end-policy
!
router bgp 3269
address-family ipv4 unicast
additional-paths selection route-policy REISS-BACKUP
!
neighbor 192.168.0.1
remote-as 3269
update-source Loopback0
address-family ipv4 unicast
!
!
neighbor 192.168.0.2
remote-as 3269
update-source Loopback0
address-family ipv4 unicast
!
!
!
Faccio notare che gli indirizzi 192.168.0.1 e 192.168.0.2 sono quelli di due Route Reflector, ma ho "magheggiato" con operazioni elementari in modo che PE2-3 ricevesse due annunci distinti del prefisso 10.1.99.12/32.
Riporto di seguito delle visualizzazioni ottenute con comandi classici, che consentono di verificare l'abilitazione della funzionalità BGP PIC Edge.
La prima visualizzazione riguarda il dettaglio degli annunci BGP del prefisso 10.1.99.12/32, presenti nella Tabella BGP di PE3-2:
RP/0/1/CPU0:PE2-3# show bgp 10.1.99.12/32
Thu Nov 20 18:01:19.445 UTC
BGP routing table entry for 10.1.99.12/32
Versions:
Process bRIB/RIB SendTblVer
Speaker 8 8
Last Modified: Nov 20 18:00:26.003 for 00:00:53
Paths: (2 available, best #1)
Not advertised to any peer
Path #1: Received by speaker 0
Not advertised to any peer
65012
192.168.0.11 (metric 32) from 192.168.0.1 (192.168.0.11)
Origin IGP, metric 0, localpref 100, valid, internal, best, group-best
Received Path ID 0, Local Path ID 1, version 7
Originator: 192.168.0.11, Cluster list: 192.168.0.1
Path #2: Received by speaker 0
Not advertised to any peer
65012
192.168.0.12 (metric 32) from 192.168.0.2 (192.168.0.12)
Origin IGP, metric 0, localpref 100, valid, internal, backup, add-path
Received Path ID 0, Local Path ID 2, version 8
Originator: 192.168.0.12, Cluster list: 192.168.0.2
Il percorso di backup è (ovviamente) quello "non best". La presenza della parola "backup" nella terzultima riga della visualizzazione mostra che l'abilitazione della funzionalità BGP PIC Edge è andata a buon fine.
La seconda visualizzazione riguarda il dettaglio delle informazioni nella RIB (Tabella di Routing), relative al prefisso 10.1.99.12/32:
RP/0/1/CPU0:PE2-3# show route 10.1.99.12/32
Thu Nov 20 18:03:13.641 UTC
Routing entry for 10.1.99.12/32
Known via "bgp 3269", distance 200, metric 0
Tag 65012
Number of pic paths 1 , type internal
Installed Nov 20 18:00:26.433 for 00:02:47
Routing Descriptor Blocks
192.168.0.11, from 192.168.0.1
Route metric is 0
192.168.0.12, from 192.168.0.2, BGP backup path
Route metric is 0
No advertising protos.
Dalla visualizzazione si deduce che esistono due percorsi verso il prefisso 10.1.99.12/32, di cui quello di backup (evidenziato con "BGP backup path") è quello che ha BGP Next-Hop 192.168.0.12.
Infine, la terza visualizzazione (la più importante) riguarda la Tabella CEF:
RP/0/1/CPU0:PE2-3# show cef 10.1.99.12/32
Thu Nov 20 18:11:17.971 UTC
10.1.99.12/32, version 43, internal 0x14000001 (ptr 0xae3523d0) [1], 0x0 (0x0), 0x0 (0x0)
Updated Nov 20 18:00:26.436
local adjacency 172.16.2.21
Prefix Len 32, traffic index 0, precedence routine (0), priority 4
via 192.168.0.11, 2 dependencies, recursive [flags 0x6000]
path-idx 0 [0xae352010 0x0]
next hop 192.168.0.11 via 192.168.0.11/32
via 192.168.0.12, 2 dependencies, recursive, backup [flags 0x6100]
path-idx 1 [0xae352088 0x0]
next hop 192.168.0.12 via 192.168.0.12/32
Dalla visualizzazione si deduce che nella FIB esistono due percorsi verso il prefisso 10.1.99.12/32, di cui quello di backup (evidenziato con "backup") è quello che ha BGP Next-Hop 192.168.0.12.
CONFIGURAZIONE DELLA FUNZIONALITA' PIC NELLE PIATTAFORME JUNIPER
Per quanto riguarda il JUNOS, l'architettura gerarchica della FIB va abilitata con il comando seguente:
tt@router# show routing-options
forwarding-table {
indirect-next-hop;
}
Per verificare se il comando ha avuto effetto, l'unico modo è utilizzare il comando (nascosto) "show krt indirect-next-hop". Con una piccola prova che ho effettuato, questo è il risultato che ho ottenuto:
tt@PE2-2> show krt indirect-next-hop
Indirect Nexthop:
Index: 262142 Protocol next-hop address: 192.168.1.12
RIB Table: inet.0
Policy Version: 0 References: 1
Locks: 2 0x165c0e8
Flags: 0x1
Ref RIB Table: unknown
Next hop: 172.30.2.1 via ge-0/0/0.0
L'abilitazione dell'architettura gerarchica della FIB è segnalata dalla flag 0x1 (Flags: 0x1). Quando il comando "indirect-next-hop" viene eliminato, o disattivato tramite il comando seguente (ma non si capisce perché uno dovrebbe farlo):
tt@router# show routing-options
forwarding-table {
no-indirect-next-hop;
}
il valore della flag cambia da 0x1 a 0x0.
Faccio notare che il comando "show krt indirect-next-hop" non è documentato, ma è l'unico (almeno secondo alcuni documenti JUNOS) che consente di verificare se il comando "indirect-next-hop" è stato eseguito. Un'altra prova (anche migliore) ovviamente è il monitoraggio delle prestazioni di convergenza a seguito del fuori servizio di un elemento di rete, prima e dopo l'esecuzione del comando "indirect-next-hop".
Per la funzionalità BGP PIC Core non vi è bisogno d'altro, mentre per la funzionalità BGP PIC Edge è necessaria una opportuna configurazione. Il JUNOS supporta il BGP PIC Edge solo con per il servizio L3VPN. Vi sono due comandi diversi in funzione del tipo di protezione. Il primo tipo riguarda la protezione da fuori servizio di un altro router PE. L'abilitazione della funzionalità BGP PIC Edge avviene in questo caso attraverso il semplice comando:
[edit routing-instances NOME-RI]
tt@router# show
routing-options {
protect core;
}
Non avendo a disposizione piattaforme Juniper in grado di supportare questo comando, vi rimando a questo esempio, disponibile nella documentazione Juniper. Vi avverto però che per poter capire bene l'esempio, è necessaria una buona conoscenza dell'implementazione dei servizi L3VPN nel JUNOS.
Il secondo tipo di protezione riguarda il fuori servizio di un collegamento PE-CE. L'abilitazione della funzionalità BGP PIC Edge avviene in questo caso attraverso il semplice comando:
[edit routing-instances NOME-RI protocols bgp group NOME-GRUPPO]
tt@router# show
family ( inet | inet6 ) {
unicast {
protection;
}
}
Anche qui, non avendo a disposizione piattaforme Juniper in grado di supportare questo comando, vi rimando a questo esempio, disponibile nella documentazione Juniper.
CONCLUSIONI
Con questo Post, spero di aver dato il colpo finale alla "credenza popolare" che il BGP sia lento a convergere. La realtà, come risulta dalla lettura, è ben diversa e oggi si può tranquillamente dire che il BGP converge con tempi dell'ordine delle decine di msec. Naturalmente questo comporta un tuning accurato del protocollo IGP, l'applicazione del BGP PIC Core/Edge e l'implementazione di FIB con struttura gerarchica. I principali costruttori di apparati come Cisco e Juniper mettono a disposizione tutti gli strumenti per fare questo, basta applicarli !
La storia comunque non finisce qui, ho detto più volte che manca un tassello fondamentale, ossia fare in modo che un router abbia a disposizione un secondo annuncio, oltre al best-path, da utilizzare come backup. A volte questo secondo annuncio si ha senza fare alcunché, ma in alcune situazioni importanti da un punto di vista pratico, questo non avviene. Ed è di questo che mi occuperò in futuro.
Siete nuovi al BGP, oppure avete bisogno di ulteriori approfondimenti ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247.
Pubblicato in
ReissBlog
Etichettato sotto
Domenica, 09 Novembre 2014 14:55
MPLS NEWS: LOAD BALANCING VIA FAT E ENTROPY LABELS
MPLS è uno standard che mi ha intrigato sin dalla sua nascita (nel lontano 1997, anche se i primi standard ufficiali e le prime applicazioni sul campo si sono avute agli inizi del 2001). La ragione è che è un'idea molto semplice, già nota e utilizzata in altri standard (es. ATM, Frame Relay), ma che ha reso le reti IP molto più flessibili nel trasporto del traffico e nell'offerta dei servizi di rete.
Dopo tanti anni MPLS può essere considerato una realtà (molto spesso "amata", qualche volta "odiata") delle reti IP, utilizzato dalla quasi totalità dei grandi ISP (Internet Service Provider) e nelle grandi reti Enterprise. Chi conosce bene l'argomento sa però che MPLS ha bisogno di una "intelligenza" per funzionare, e questa nella quasi totalità dei servizi è offerta dal BGP e dalla incredibile flessibilità che questo offre. Tanto che si dovrebbe parlare più correttamente di servizi BGP/MPLS più che di servizi MPLS. Il BGP è la "mente", MPLS è il "braccio" operativo che trasporta il traffico. In altre parole, BGP gioca il ruolo chiave nel piano di controllo e MPLS nel piano dati.
Benché ormai consolidato, di tanto in tanto anche MPLS è soggetto a "restyling", che consentono di migliorare il suo funzionamento. In questo Post tratterò due nuovi standard, molto semplici, che consentono di migliorare i criteri con cui MPLS può essere utilizzato per una distribuzione più uniforme del traffico sulla rete, quando vi siano tra origine e destinazione dei LSP (Label Switched Path) MPLS, più percorsi (ottimi) "identici", ad esempio due o più percorsi IGP a costo minimo (tecnica nota come Load Balancing (da qui in poi abbreviata in LB) o anche ECMP, Equal-Cost Multi-Path).
Prima di parlare dei due nuovi standard, è bene però fare il "riassunto delle puntate precedenti", ossia ricordare come le attuali piattaforme effettuano il LB di pacchetti MPLS. In altre parole, forse più eleganti ma meno suggestive, come sia possibile con le attuali piattaforme, dividere il traffico di pacchetti MPLS tra una origine e destinazione, in due LSP differenti.
Ci sono due aspetti che caratterizzano il LB di pacchetti MPLS. Il primo riguarda i percorsi MPLS (LSP MPLS). Nel caso in cui questi siano determinati da un protocollo IGP (tipicamente nelle applicazioni pratiche OSPF o IS-IS, anche se in teoria è possibile utilizzare qualsiasi protocollo IGP), e le etichette MPLS associate ai percorsi IGP siano di conseguenza determinate dal protocollo LDP, il LB dei pacchetti MPLS è possibile solo in presenza di percorsi IGP multipli a minimo costo. Nei punti di diramazione dei percorsi, il traffico MPLS viene ripartito dai LSR (o Edge-LSR se un punto di diramazione coincide con l'origine del LSP) con qualche criterio su due o più Next-Hop IGP. Ad esempio, nella figura seguente, supponendo che tutte le interfacce abbiamo metrica identica (il valore è ininfluente), il router PE1, che è un Edge-LSR e P11, che è un LSR, sono dei punti di diramazione per il traffico. I pacchetti o trame L2 entranti, nella figura indicati con 1, 2 e 3, vengono quindi ripartiti con qualche criterio sui Next-Hop disponibili.

Quando invece i LSP MPLS sono costruiti attraverso il Traffic Engineering MPLS (LSP MPLS-TE), per effettuare una qualche forma di LB è necessario stabilire due o più LSP MPLS-TE tra lo stesso router origine e lo stesso router destinazione.
Il secondo aspetto è molto più importante ed è quello che ha dato origine ai due nuovi standard di cui parlerò in questo Post: con quali criteri i pacchetti MPLS vengono assegnati ai percorsi alternativi disponibili ? Ossia, quando un router ha a disposizione più Next-Hop per instradare un pacchetto MPLS, con quali criteri assegna il pacchetto a un determinato Next-Hop ? Questo è un aspetto che ha un impatto molto importante sulla qualità del servizio. Per vedere il perché, supponiamo per semplicità di avere due Next-Hop possibili. Il LSR che deve decidere come assegnare i pacchetti MPLS ai Next-Hop ha varie scelte a disposizione. Ad esempio, potrebbe assegnare i pacchetti sempre allo stesso Next-Hop. Ma questo, a parte il fatto che evita il LB "tout court", potrebbe portare alla congestione di un collegamento, quando l'altro disponibile è magari scarico. Una seconda alternativa è quella di effettuare un LB "per pacchetto", ossia inviare alternativamente un pacchetto verso un Next-Hop, e il successivo verso l'altro Next-Hop. Benché semplice, questo criterio, se da un lato consente di evitare il problema precedente e distribuire il traffico abbastanza equamente sui due collegamenti disponibili, ha però un grosso difetto: i pacchetti, che normalmente appartengono a un flusso di traffico ben definito (es. una conversazione VoIP, una connessione TCP Client-Server, ecc.), vengono consegnati a destinazione fuori sequenza, obbligando il protocollo di trasporto al riordino dei pacchetti. Inoltre, poiché i singoli pacchetti di un flusso possono seguire percorsi più o meno congestionati, aumentano ritardo e jitter. Agli inizi della storia, a causa della sua semplicità di implementazione, era comunque questa la strategia adottata dai maggiori costruttori.
L'ideale sarebbe di assegnare i pacchetti ai Next-Hop disponibili, mantenendo la sequenzialità all'interno dei singoli flussi di traffico. Ma qui ci si scontra con un problema chiave. MPLS nella sua intestazione, a volte chiamata shim header dove shim significa "snella", non ha un campo che gli consenta di dedurre a quale protocollo appartiene il pacchetto o trama L2 che sta trasportando (un pacchetto IPv4, IPv6, Apple-Talk, una trama Ethernet, PPP, ecc., chissa ?), e quindi non è in grado di determinare i pacchetti di uno stesso flusso, men che meno inferire alcunché sulla granularità del flusso.
A ben vedere, il problema sarebbe di banale soluzione nel caso in cui i LSP MPLS siano realizzati attraverso il Traffic Engineering MPLS. In questo caso infatti, il LSR origine dei LSP MPLS-TE, avendo a disposizione l'intero pacchetto o trama da trasportare nei LSP MPLS-TE disponibili, potrebbe guardare a particolari campi (di Livello2, 3 e/o 4) all'interno della trama o del pacchetto, individuare i singoli flussi con più o meno granularità, e assegnare i singoli flussi ai vari LSP MPLS-TE disponibili. Giusto per fare un esempio pratico, supponiamo che da un Edge-LSR origine vengano realizzati due LSP MPLS-TE verso la stessa destinazione. Come questi vengono realizzati, se staticamente o attraverso il Constraint-Based Routing con vincoli più o meno sofisticati (es. vincoli SRLG, classi amministrative, ecc.) è assolutamente indifferente. Supponiamo inoltre che sui due LSP MPLS-TE si debbano veicolare pacchetti IPv4. Per distribuire il traffico in modo "intelligente" sui due LSP MPLS-TE disponibili, l'Edge-LSR di ingresso potrebbe essere configurato con una sorta di Policy-Based Routing che funzioni in questo modo: se il pacchetto appartiene a un flusso X (individuato ad esempio guardando i soli indirizzi IP sorgente e destinazione) allora invia il pacchetto al primo LSP MPLS-TE; se il pacchetto appartiene a un flusso Y (sempre individuato guardando i soli indirizzi IP sorgente e destinazione), allora invia il pacchetto al secondo LSP MPLS-TE. Poiché i flussi con diverse coppie <IP sorgente; IP destinazione> sono in genere molti, la logica viene implementata attraverso un algoritmo di Hash, che (per semplificare) a fronte di una determinata coppia <IP sorgente; IP destinazione> determina un numero intero, nel nostro esempio 1 o 2; qualora il risultato fosse 1, il pacchetto verrebbe inviato al primo MPLS-TE; se, viceversa, il risultato fosse 2, il pacchetto verrebbe inviato al secondo MPLS-TE (NOTA: ribadisco che questa è solo una versione semplificata, ma esplicativa, del funzionamento dell'algoritmo di Hash).
Quando i LSP seguono invece i percorsi IGP e le etichette MPLS stabilite dal protocollo LDP, il problema è molto più sottile poiché, come detto sopra, i LSR di transito non conoscono esattamente cosa ci sia dietro un pacchetto MPLS, ma possono solo dedurlo con qualche trucco più o meno intelligente. Il problema è che questi trucchi, che sono per la maggior parte vendor-dependent, a volte non funzionano.
Prima di andare avanti, vediamo come i due maggiori costruttori di apparati, Cisco e Juniper, risolvono il problema.
LOAD BALANCING DI PACCHETTI MPLS NEI ROUTER CISCO
I router Cisco, in presenza di Next-Hop IGP multipli, effettuano di default il LB dei pacchetti MPLS. Ho fatto una prova sui nostri Lab, utilizzando OSPF come protocollo IGP, e abilitando LDP. Automaticamente, come noto, questo è sufficiente a stabilire LSP MPLS end-to-end tra due qualsiasi router. Consideriamo il caso di uno di questi LSP, originato in un router che ho chiamato PE11, e terminato su un router PE21, che ha indirizzo IP dell'interfaccia Loopback 0 pari a 192.168.1.21. Il percorso MPLS attraversa il LSR di transito CS11, che ha due percorsi OSPF verso il prefisso IP 192.168.1.21:
CS11# show ip route 192.168.1.21
Routing entry for 192.168.1.21/32
Known via "ospf 11", distance 110, metric 21, type intra area
Last update from 172.30.13.21 on Serial1/3, 00:08:33 ago
Routing Descriptor Blocks:
* 172.30.14.22, from 192.168.1.21, 00:08:33 ago, via Serial1/4
Route metric is 21, traffic share count is 1
172.30.13.21, from 192.168.1.21, 00:08:33 ago, via Serial1/3
Route metric is 21, traffic share count is 1
Il dettaglio della tabella di forwarding MPLS, per quanto riguarda la terminazione del LSP è il seguente:
CS11# show mpls forwarding-table 192.168.1.21 detail
Local Outgoing Prefix Bytes tag Outgoing Next Hop
tag tag or VC or Tunnel Id switched interface
25 27 192.168.1.21/32 0 Se1/4 point2point
MAC/Encaps=4/8, MRU=1500, Tag Stack{27}
0F008847 0001B000
No output feature configured
Per-destination load-sharing, slots: 0 2 4 6 8 10 12 14
23 192.168.1.21/32 0 Se1/3 point2point
MAC/Encaps=4/8, MRU=1500, Tag Stack{23}
0F008847 00017000
No output feature configured
Per-destination load-sharing, slots: 1 3 5 7 9 11 13 15
Come si può notare, i pacchetti MPLS che arrivano a CS11 con etichetta MPLS 25, vengono inviati o al Next-Hop "interfaccia Se1/4" (punto-punto !) con etichetta 27, o al Next-Hop "interfaccia Se1/3" con etichetta 23. Dalla visualizzazione si evince inoltre che CS11 utilizza di default, per assegnare i pacchetti MPLS ai Next-Hop, un algoritmo di tipo "per-flusso" (Per-destination load-sharing ...) (NOTA: l'IOS Cisco consente di abilitare comunque il LB per pacchetto con il comando a livello interfaccia "ip load-sharing per-packet", ma è sconsigliato).
I numeri che seguono la parola "slots" indicano i cosiddetti Hash Bucket, e sono determinati dall'algoritmo CEF attraverso un algoritmo di Hash. Gli Hash Bucket sono in totale 16 e vengono utilizzati nel seguente modo: se il risultato dell'algoritmo di Hash è un numero pari (0, 2, 4, ...) invia il pacchetto attraverso l'interfaccia Se1/4 con etichetta MPLS 27. Viceversa, se il risultato è un numero dispari, invia il pacchetto attraverso l'interfaccia Se1/3 con etichetta MPLS 23 (NOTA: il numero di Hash Bucket varia in funzione della piattaforma, e rappresenta il numero massimo di percorsi su cui è possibile fare LB).
Rimane il problema chiave: quali variabili utilizza in input l'algoritmo di Hash (spesso indicate in letteratura come keys) ? Cisco utilizza di default questa strategia (NOTA: questa strategia potrebbe variare leggermente in funzione della piattaforma, ma la sostanza non cambia):
- Se il pacchetto trasportato da MPLS è un pacchetto IPv4, l'algoritmo di Hash utilizza come variabili in input gli indirizzi IPv4 sorgente e destinazione.
- Se il pacchetto trasportato da MPLS è un pacchetto IPv6, l'algoritmo di Hash utilizza come variabili in input gli indirizzi IPv5 sorgente e destinazione.
- Se il pacchetto trasportato da MPLS non è né un pacchetto IPv4 né un pacchetto IPv6, l'algoritmo di Hash utilizza come unica variabile in input il valore dell'etichetta MPLS più interna, ossia l'ultima nella pila di etichette MPLS (in altre parole, per i più esperti di MPLS, quella che ha il bit S=1).
Questo sembrerebbe chiudere il cerchio e quindi terminare la storia. Purtroppo non è così. Questo trucco fallisce miseramente in presenza di trasporto di trame di Livello 2, come ad esempio nei servizi VPWS (Virtual Private Wire Service) e VPLS (Virtual Private LAN Service). Supponiamo ad esempio che il LSP del nostro esempio trasporti delle trame Ethernet, perché magari abbiamo realizzato un servizio VPLS per collegare dei router CE collegati ai due PE origine e destinazione del LSP MPLS (PE11 e PE21). In questo caso sorgono due problemi:
- Se l'indirizzo MAC destinazione ha i primi 4 bit che coincidono con 4 o 6, il LSR considera l'intera trama Ethernet come un pacchetto IPv4 o IPv6, sbagliando clamorosamente. Per evitare questo, la documentazione Cisco consiglia di aggiungere sempre i 4 byte della Control Word, che, secondo la RFC 4385, ha sempre i primi 4 bit nulli (e quindi mai pari a 4 o 6).
- Viceversa, se i primi 4 bit non coincidono con 4 o 6, è vero che il router non sbaglia, ma il LB, che è basato in questo caso sull'etichetta MPLS più interna (che in questo caso coincide con la VC Label che caratterizza lo pseudowire), non è molto efficiente poiché non consente di distribuire il traffico su più Next-Hop.
Entrambi questi problemi sarebbero di facile soluzione se un LSR avesse accesso all'intero payload MPLS, come ad esempio l'Edge-LSR di ingresso. Vedremo che i due nuovi standard che saranno illustrati in seguito, sono proprio basati su questa considerazione.
LOAD BALANCING DI PACCHETTI MPLS NEI ROUTER JUNIPER
Gli esperti di router Juniper sanno che a differenza dei router Cisco, il LB non viene effettuato di default ma va abilitato con la seguente sequenza di comandi:
policy-options {
policy-statement LB {
then {
load-balance per-packet;
}
}
routing-options {
forwarding-table {
export LB;
}
}
dove però, attenzione, il comando "load-balance per-packet" è molto ambiguo, perché non abilita il LB per pacchetto, ma il LB "per flusso". Purtroppo però il comando è questo e così bisogna tenerselo.
Nel caso di un LSR di transito, se questo ha due o più Next-Hop "ottimi" disponibili, l'abilitazione del LB comporta per ciascun pacchetto MPLS entrante, come nei router Cisco, la possibilità di utilizzarli tutti, come nel seguente esempio con due Next-Hop disponibili:
tt@CE1> show route forwarding-table family mpls label 299824
Routing table: default.mpls
MPLS:
Destination Type RtRef Next hop Type Index NhRef Netif
299824 user 0 ulst 131070 2
10.1.11.1 Swap 299792 562 1 fe-0/0/0.0
10.1.21.1 Swap 299776 563 1 fe-0/0/1.0
Con quale criterio di default i router Juniper utilizzano i due Next-Hop disponibili ? Non ho trovato nella documentazione Juniper informazioni precise in merito, però in ogni caso c'è la possibilità di scegliere le variabili da utilizzare in input all'algoritmo di Hash per la scelta del Next-Hop. Le variabili possono essere molteplici e vanno dalle etichette MPLS ai campi di livello 3 e/o 4. Ogni piattaforma poi ha più o meno variabili configurabili. La scelta va eseguita nella gerarchia di configurazione [edit forwarding-options hash-key family mpls]. Ad esempio, qualora si volessero utilizzare come input, la prima etichetta MPLS (la più esterna), quella successiva e gli indirizzi IP sorgente e destinazione, la configurazione da eseguire è la seguente:
[edit forwarding-options hash-key family mpls]
tt@router# show
label-1;
label-2;
payload {
ip;
}
In realtà, piuttosto che tutti i 64 bit delle prime intestazioni MPLS contenenti le prime due etichette, vengono utilizzati tutti i 32 bit della prima intestazione e i primi 16 bit della seconda. Un elenco di tutte le variabili configurabili disponibili nelle varie piattaforme, può essere trovato in questo documento:
LOAD BALANCING VIA FAT LABELS (RFC 6391)
Da quanto detto sopra, l'elemento chiave per eseguire un LB efficiente è l'Edge-LSR di ingresso, che è l'unico in grado di effettuare una deep inspection sul pacchetto o trama L2 entrante prima dell'incapsulamento MPLS. In teoria anche i router intermedi potrebbero effettuare questa deep inspection, ma al prezzo di un serio degrado delle prestazioni. L'ideale sarebbe di effettuare questa deep inspection solo sull'Edge-LSR di ingresso e quindi aggiungere al pacchetto MPLS una nuova variabile da utilizzare come input all'algoritmo di Hash. Su questa idea si basa la soluzione introdotta nella RFC 6391 "Flow-Aware Transport of Pseudowires over an MPLS Packet Switched Network" del Novembre 2011, che si basa sull'aggiunta di una nuova etichetta MPLS (FAT Label), da utilizzare esclusivamente come input all'algoritmo di Hash (NOTA: FAT in questo caso non significa "grasso" , ma è un acronimo che sta per Flow-Aware Transport; dico questo perché magari qualcuno potrebbe pensare che poiché l'intestazione MPLS viene anche chiamata shim header, ossia "intestazione snella", viene aggiunta una FAT Label, ossia "etichetta grassa", per riportarla al giusto peso (ovviamente sto solo scherzando ) !).
La soluzione è molto semplice, ma vale solo per gli pseudowire, e quindi utilizzabile in servizi MPLS come VPWS e VPLS (solo con segnalazione LDP).
Come dicevo sopra l'idea è molto semplice. Poiché l'Edge-LSR di ingresso ha a disposizione la trama L2 da trasportare negli pseudowire, può eseguire una deep inspection ed individuare i flussi "divisibili" presenti all'interno di tutto il traffico trasportato dallo pseudowire. Per ciascun flusso viene quindi generata una FAT Label, che viene aggiunta nella posizione più interna della pila delle due etichette MPLS utilizzate dallo pseudowire, ossia, tra la VC Label e la Control Word (vedi figura seguente).
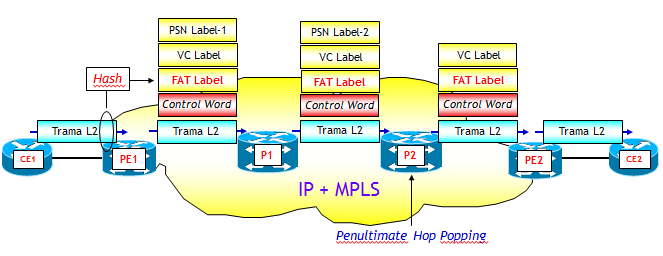
La FAT Label viene generata attraverso un algoritmo di Hash, che ha come variabili in input vari campi di Livello 2, 3 e/o 4. La FAT Label viene quindi utilizzata dai LSR di transito come sola variabile di input all'algoritmo di Hash che esegue il LB. I campi di Livello 2, 3 e/o 4 utilizzati per determinare la FAT Label sono i campi che individuano, con più o meno granularità, i flussi "divisibili" all'interno di tutto il traffico trasportato dallo pseudowire. La FAT Label non viene utilizzata per l'instradamento, ma solo ed esclusivamente per il LB, e viene tolta dall'Edge-LSR di uscita prima di consegnare la trama L2 al router destinazione.
Poiché non tutti i router potrebbero supportare l'utilizzo della FAT Label, questa funzionalità va negoziata attraverso una opportuna segnalazione. La RFC 6391 specifica la segnalazione via LDP (multi-hop) e nulla dice riguardo alla segnalazione BGP. La segnalazione avviene attraverso il nuovo modulo Flow Label sub-TLV, inserito nel modulo Interface Parameter sub-TLV. Per chi non fosse familiare con la segnalazione LDP multi-hop degli pseudowire, l'Interface Parameter sub-TLV è un modulo TLV (Type-Length-Value) aggiunto alla fine del modulo TLV PW ID FEC TLV, parte di un messaggio LDP LABEL MAPPING (vedi figura seguente), che viene utilizzato per definire alcuni parametri specifici di una interfaccia lato CE (es. MTU, stringa di descrizione, VLAN ID).

Per una spiegazione dettagliata dei vari campi, il lettore interessato può consultare la RFC 4447. A sua volta il campo Interface Parameter sub-TLV è composto da tanti moduli TLV, di cui uno di questi potrebbe essere il nuovo modulo Flow Label sub-TLV, che ha il formato riportato nella figura seguente:

I due campi significativi sono i due bit T e R, il cui significato indica il supporto delle FAT Label rispettivamente in trasmissione e in ricezione. Un router che supporta le FAT Label può quindi segnalarlo ponendo i due bit T e R entrambi a 1.
La figura seguente mostra uno scenario di utilizzo delle FAT Label.
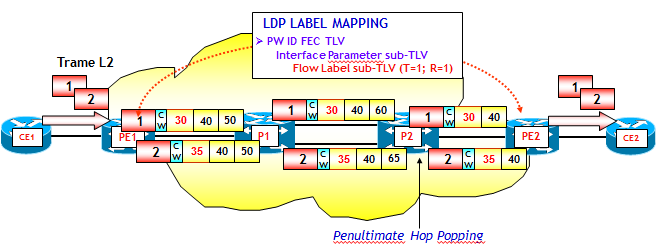
Per ipotesi, entrambi gli Edge-LSR PE1 e PE2 supportano le FAT Label. Il supporto viene comunicato in fase di segnalazione attraverso il modulo Flow Label sub-TLV con i bit T=R=1. Supponiamo che l'Edge-LSR di ingresso, per ipotesi il router PE1, riceva due flussi IPv4 da trasportare all'interno dello stesso pseudowire. Per ciascun flusso, PE1 determina una FAT Label, che viene interposta tra la VC Label e la Control Word. Le due FAT Label (30 e 35 nella figura), vengono utilizzate dal router P come input all'algoritmo di Hash che consente di effettuare il LB sui due collegamenti disponibili. L'Edge-LSR di uscita, il router PE2, a causa del Penultimate Hop Popping, riceve quindi le trame con due etichette MPLS, la VC Label e la FAT Label. La VC Label come noto serve ad individuare lo pseudowire, e la FAT Label a questo punto non viene utilizzata poiché il pacchetto MPLS è giunto al "capolinea". PE2 esegue infine una operazione di Label Pop su entrambe le etichette, e invia le trame L2 a destinazione.
Circa il supporto delle FAT Label nei router Cisco e Juniper, ho appurato che nei router Cisco sono supportate nei router della serie 76xx e negli ASR 9k, a partire dall'IOS XR 4.2.1. Negli ASR 9k la configurazione da eseguire per abilitare il supporto delle FAT Label è la seguente:
RP/0/RP0/CPU0:router(config)#l2vpn
RP/0/RP0/CPU0:router(config-l2vpn)#pw-class NOME-PW-CLASS
RP/0/RP0/CPU0:router(config-l2vpn-pwc)#encapsulation mpls
RP/0/RP0/CPU0:router(config-l2vpn-pwc-mpls)#load-balancing flow-label { both | receive | transmit }
E' possibile inoltre scegliere le variabili in input dell'algoritmo di Hash che consente di determinare le FAT Label, anche se la scelta è limitata. Ad esempio, nel caso di pacchetti IP, con il comando:
RP/0/RP0/CPU0:router(config)#l2vpn
RP/0/RP0/CPU0:router(config-l2vpn)# load-balancing flow src-dst-ip
è possibile utilizzare come variabili di input gli indirizzi IP sorgente e destinazione. In alternativa, con il comando "load-balancing flow src-dst-mac" è possibile utilizzare come variabili gli indirizzi MAC sorgente e destinazione (solo nel caso di trame Ethernet, ovviamente).
Il JUNOS supporta le FAT Label sia per i servizi VPWS e VPLS con segnalazione LDP e auto-discovery sia manuale che via BGP. Per semplicità, illustrerò le configurazioni solo per il caso di auto-discovery manuale. La configurazione da eseguire per abilitare il supporto delle FAT Label è la seguente:
[edit protocols l2circuit neighbor neighbor-id interface interfaccia]
tt@Edge-LSR-Ingresso# show
flow-label-transmit;
flow-label-receive;
Un esempio completo di configurazione è il seguente:
[edit protocols l2circuit]
tt@PE1# show
neighbor 192.168.0.2 {
interface ge-0/0/0.0 { # Attachment Circuit lato CE
virtual-circuit-id 100;
flow-label-transmit;
flow-label-receive;
}
}
La scelta delle variabili in input dell'algoritmo di Hash che consente di determinare le FAT Label, può essere eseguita con i comandi illustrati in precedenza all'interno della gerarchia di configurazione [edit forwarding-options hash-key family mpls], dove però, faccio notare, non ha senso inserire nelle variabili le etichette MPLS perché le trame L2 arrivano all'Edge-LSR di ingresso senza etichette MPLS.
LOAD BALANCING VIA ENTROPY LABELS (RFC 6790)
Il trucco delle FAT Label, come visto nella sezione precedente, si applica solo al caso degli pseudowire, e funziona perché l'Edge-LSR di uscita conosce esattamente il valore numerico della VC Label, dietro la quale si "nasconde" la FAT Label. Lo stesso trucco non funzionerebbe ad esempio, nel caso di semplice trasporto con singola etichetta. Questo perché in tal caso, a causa del Penultimate Hop Popping (PHP), il pacchetto MPLS arriverebbe all'Edge-LSR di uscita con la sola FAT Label, e questo non saprebbe come gestirla, non avendola scelta.
Successivamente alla RFC 6391, è uscita un nuovo standard, che specifica un metodo più generale, valido non solo nel caso di pseudowire, ma in generale per ogni tipo di trasporto MPLS. Lo standard in questione è definito nella RFC 6790 "The Use of Entropy Labels in MPLS Forwarding", del Novembre 2012. L'idea di fondo è la stessa della RFC 6391, ma la modalità di applicazione è diversa e, come detto, più generale. Al pari delle FAT Label, le Entropy Label non sono segnalate e non sono utilizzate per il forwarding, ma solo per il LB. Come valore può essere utilizzato un qualsiasi numero, purché non appartenente a quelli riservati (valori 0-15).
++++++++++ BREVE FUORI TEMA ++++++++++
L'utilizzo del termine Entropy (entropia) per indicare queste etichette è molto suggestivo e richiama un noto concetto della fisica che si applica a vari campi, tra cui la termodinamica, la meccanica statistica, la teoria dei segnali, la teoria dell'informazione, ecc. . L'entropia (dal greco antico ?ν en, "dentro", e τροπ? tropé, "trasformazione") è una grandezza (più in particolare una coordinata generalizzata) che viene interpretata come una misura del disordine presente in un sistema fisico qualsiasi, incluso, come caso limite, l'universo.
++++++++++ FINE FUORI TEMA ++++++++++
Dopo questa breve digressione, ritornando al nostro caso, è possibile pensare a un flusso di pacchetti come un insieme disordinato di elementi, e all'aumentare del disordine (ossia, del numero di flussi) cresce il numero di etichette MPLS necessario a "ordinarli". Le Entropy Label possono quindi essere pensate come delle etichette che cercano di mettere ordine in un sistema altamente disordinato. Non so se sia questa l'interpretazione che hanno dato gli autori della RFC all'utilizzo del termine Entropy, ma a me suona suggestivo così.
Si noti che per servizi come L2VPN, L3VPN, 6PE, 6VPE, ecc., a causa della presenza di una VC Label, o VPN Label, ecc., in funzione del servizio, (talvolta anche chiamata, in generale, Application Label), vi è minore ambiguità per gli Edge-LSR di uscita nel riconoscere una Entropy Label (in modo identico a quanto avviene per le FAT Label). Però per il semplice forwarding di pacchetti IP, come detto sopra, a causa del PHP un Edge-LSR di uscita non è in grado di sapere che l'etichetta ricevuta appartiene a una Entropy Label piuttosto a una normale Application Label. Ad esempio, pensate ad un router PE (che gioca in questo caso il ruolo di Edge-LSR di uscita) che per un servizio L3VPN annunci (via MP-iBGP) la VPN Label 1954, associata a un prefisso VPN-IPv4. Nel momento in cui riceverà successivamente un pacchetto MPLS con la sola etichetta MPLS 1954, come farà a sapere se quella è una Entropy Label o una VPN Label ? Chiaramente, una decisione sbagliata porta il payload MPLS trasportato in una direzione sbagliata.
Per evitare qualsiasi ambiguità, la RFC 6790 ha definito l'etichetta speciale con valore 7, denominata Entropy Label Indicator (ELI). Questa etichetta va sempre anteposta a una Entropy Label, in modo tale che chi riceve un pacchetto MPLS, sa con certezza che dopo la ELI vi è una Entropy Label. Sia la ELI che la Entropy Label sono imposte tramite una operazione di Label Push dall'Edge-LSR di ingresso.
Come avviene per le FAT Label, il supporto delle Entropy Label va negoziato. La RFC 6790 stabilisce come va effettuata la negoziazione sia per il protocollo LDP, che per i protocolli BGP e RSVP-TE.
Nel caso del protocollo LDP, la negoziazione avviene attraverso il nuovo modulo ELC TLV (Entropy Label Capability TLV), che viene aggiunto ai parametri opzionali dei messaggi LDP LABEL MAPPING. La struttura del modulo ELC TLV è riportata nella figura seguente:
dove il significato dei bit U e F è specificato dal protocollo LDP classico (RFC 5036). Per il modulo ELC TLV, entrambi questi bit sono posti a 1. Ricordo che il bit U, quando pari a 1 indica che un LDP peer che riceve il messaggio LDP LABEL MAPPING con un modulo ELC TLV, qualora non sia in grado di elaborarlo deve ignorarlo. Il bit F invece, quando posto a 1 indica che un modulo ELC TLV in ogni caso deve essere propagato hop-by-hop nella direzione downstream agli altri LDP peer. La presenza di un modulo ELC TLV in un messaggio LDP LABEL MAPPING, indica all'Edge-LSR di ingresso, che l'Edge-LSR di uscita supporta l'elaborazione delle Entropy Label.
Solo per fare un esempio, la figura seguente mostra come avviene la segnalazione nel caso di un LSP MPLS realizzato via LDP+IGP, che trasporta pacchetti del servizio L3VPN, e cosa avviene nel piano dati. In funzione dell'implementazione, i router P, che sono LSR, possono utilizzare come variabili di input all'algoritmo di Hash per il LB o l'intera pila di etichette MPLS (ad esclusione dell'etichetta ELI), o la sola Entropy Label (NOTA: la RFC 6790 non impone regole precise al riguardo).

Circa il supporto delle Entropy Label nei router Cisco e Juniper, non mi risulta al momento che la RFC 6790 sia ancora supportata dai router Cisco, mentre è già supportata nel JUNOS a partire dalla versione 14.1 (solo in alcune piattaforme, della serie MX, T e PTX). Per LSP MPLS realizzati via IGP+LDP, la configurazione da eseguire sugli Edge-LSR è la seguente
(vedi http://www.juniper.net/techpubs/en_US/junos14.1/topics/reference/configuration-statement/entropy-label-edit-protocols-mpls.html):
[edit protocols ldp]
tt@router# show
entropy-label {
ingress-policy nome routing-policy;
}
dove attraverso la routing policy vengono individuate le FEC (Forwarding Equivalence Class) a cui appartengono i pacchetti a cui aggiungere l'Entropy Label.
La documentazione JUNOS (http://www.juniper.net/techpubs/en_US/junos14.1/topics/task/configuration/mpls-entopy-label-configuring.html), dice inoltre che i LSR di transito non richiedono alcuna configurazione.
CONCLUSIONI
MPLS è uno standard ormai ben consolidato, che richiede però di tanto in tanto qualche manutenzione. In questo Post ho illustrato due nuovi standard, che consentono di migliorare le prestazioni di Load Balancing. Cercherò eventualmente di tornarci su non appena le implementazioni dei maggiori costruttori saranno più stabili. Purtroppo i router che ho a disposizione nei nostri Lab, non mi consentono di effettuare delle prove. Le funzionalità esposte in questo Post sono appannaggio di router di fascia alta, e al momento la nostra "cassa" non ci permette di acquistarli.
Siete nuovi a MPLS, oppure avete bisogno di ulteriori approfondimenti ? Tanti anni fa (nel lontano 2003) ho scritto un libro sull'argomento "MPLS: fondamenti e applicazioni alle reti IP", Ed. Hoepli. Purtroppo non è più in commercio per manifesti "limiti di età". Se siete interessati a una copia scrivetemi una e-mail (Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.) e vedrò come fare. Oppure seguite i nostro corsi IPN272 "MPLS: dalla teoria alla pratica", IPN273 "MPLS: servizi avanzati", IPN276 "MPLS nell'IOS XR Cisco", IPN258 "MPLS nel JUNOS Juniper".
Siete nuovi a MPLS, oppure avete bisogno di ulteriori approfondimenti ? Tanti anni fa (nel lontano 2003) ho scritto un libro sull'argomento "MPLS: fondamenti e applicazioni alle reti IP", Ed. Hoepli. Purtroppo non è più in commercio per manifesti "limiti di età". Se siete interessati a una copia scrivetemi una e-mail (Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.) e vedrò come fare. Oppure seguite i nostro corsi IPN272 "MPLS: dalla teoria alla pratica", IPN273 "MPLS: servizi avanzati", IPN276 "MPLS nell'IOS XR Cisco", IPN258 "MPLS nel JUNOS Juniper".
Pubblicato in
ReissBlog
Etichettato sotto
Sabato, 22 Novembre 2014 06:20
LIBRO "IS-IS:DALLA TEORIA ALLA PRATICA" : CAP. 4
Questa settimana il Capitolo 4 del libro su IS-IS, breve (6 pagine) ma importante.
Nel Capitolo vengono illustrati i (sotto-)protocolli utilizzati da IS-IS per il suo funzionamento e il formato e incapsulamento delle PDU IS-IS (ossia, dei messaggi IS-IS).
Gli aspetti importanti trattati sono:
- Come vengono trasportati i messaggi IS-IS. A differenza dei protocolli di routing sviluppati in ambito IETF (OSPF, RIP, BGP), e anche del protocollo proprietario Cisco EIGRP, i messaggi IS-IS non sono incapsulati in pacchetti IP, ma direttamente a Livello 2.
- I tipi di PDU IS-IS, che saranno comunque dettagliati meglio nei prossimi capitoli.
- Il concetto di modulo TLV, che consente facilmente l’introduzione in IS-IS di nuove funzionalità.
Due di questi aspetti, l'incapsulamento direttamente su trame di Livello 2 e l'estendibilità garantita dai moduli TLV, sono considerati dei vantaggi rispetto a OSPF. Ma su questo avrò tempo e modi, nel seguito, per argomentare in modo più approfondito.
Buona lettura !!!
Coming up next ... un post sulla funzionalità PIC (Prefix Independent Convergence) del BGP. Non perdetevelo, è molto importante.
{phocadownload view=file|id=16|target=s}
Pubblicato in
ReissBlog
Etichettato sotto
Sabato, 01 Novembre 2014 13:17
LA (LENTA) CONVERGENZA DEL BGP: UN MITO DA SFATARE - PARTE II
Nel Post precedente sulla convergenza del BGP, ho posto l'accento su come sia possibile chiudere una sessione BGP senza aspettare la scadenza dell'Holdtime negoziato tra i due BGP peer.
In questo Post, e in Post successivi, poiché l'argomento è complesso, focalizzarò invece l'attenzione su cosa accade quando il BGP Next-Hop diventa irraggiungibile.
DAL BGP TIME-DRIVEN AL BGP EVENT-DRIVEN
Per capire la genesi del problema e il perché questo può allungare considerevolmente i tempi di convergenza, vediamo cosa accadeva nelle prime implementazioni del BGP nei router Cisco.
Per ciascun prefisso BGP tipicamente la risoluzione del BGP Next-Hop è di tipo ricorsivo. Con ciò si intende che spesso (non sempre comunque), il BGP Next-Hop non è direttamente connesso e quindi il router deve eseguire un nuovo lookup sulla Tabella di Routing (RIB) per trovare un percorso verso il BGP Next-Hop. Percorso determinato da un protocollo IGP (es. OSPF, IS-IS, ecc.), o anche, ma solo in situazioni particolarmente elementari, via routing statico.
Questa interazione tra BGP e protocolli IGP veniva implementata nei router (Cisco) dal un particolare processo noto come BGP scanner. Il processo BGP scanner esegue una scansione periodica della Tabella BGP attraverso la quale, vengono effettuati su tutti gli annunci presenti, vari controlli e aggiornamenti, come ad esempio, la raggiungibilità del BGP Next-Hop (in caso negativo l’annuncio viene eliminato dalla Tabella BGP, e se best-path, rifatto il processo di selezione per determinare il nuovo best-path), aggiornamenti della penalità del meccanismo Route Flap Damping, controllo degli annunci condizionati, ecc. . Il valore di default del periodo del processo di scanning è di 60 sec, valore che può essere variato attraverso il comando:
router(config)# router bgp <numero-AS>
router(config-router)# bgp scan-time <valore-in-secondi>
dove l’intervallo dei valori ammessi è [5, 60] . È bene tener presente che, un valore basso comporta vantaggi in termini di velocità di convergenza, ma per contro un maggiore impegno della CPU. Il valore effettivo del periodo del processo di scanning utilizzato dal router, può essere verificato attraverso il classico comando di visualizzazione “show bgp (ipv4 | ipv6) unicast summary” (nuova versione del vecchio e caro comando IPv4 "show ip bgp summary").
Perché il processo BGP scanner allunga i tempi di convergenza ? Pensate per un momento che terminato un ciclo del processo, dopo qualche secondo un BGP Next-Hop divenga irraggiungibile. Il protocollo IGP se ne accorge abbastanza velocemente, ma a causa del BGP scanner, il processo BGP se ne accorge dopo poco meno di 60 sec (statisticamente, mettendosi al centro del periodo di scanning di default di 60 sec, dopo circa 30 sec). Questo comporta che per un certo tempo (al limite quasi 60 sec, utilizzando il valore di default), il traffico incorre, con alta probabilità, in forwarding loop e/o black-hole.
La differenza di velocità di convergenza tra IGP e BGP diventa qui molto evidente. Mentre il protocollo IGP rileva la perdita di un prefisso molto velocemente (tipicamente in meno di un secondo, e con tuning opportuni dei timer principali e l'introduzione della funzionalità LFA (Loop Free Alternate) anche con tempi dell'ordine delle poche decine di msec; nel seguito scriverò dei Post su questo), il BGP (Cisco !) ha tempi di convergenza di decine di secondi (al limite quasi 60).
L'ideale sarebbe avere una comunicazione immediata (o quasi immediata) da parte del protocollo IGP al BGP, che il BGP Next-Hop è diventato irraggiungibile. In particolare, sarebbe una buona cosa passare da una gestione della validazione del BGP Next-Hop di tipo time-driven (basata sul processo BGP scanner), ad una event-driven, basata su una comunicazione da IGP a BGP, sulla raggiungibilità del BGP Next-Hop.
LA FUNZIONE BGP NEXT-HOP TRACKING
Nella sua evoluzione, l'implementazione Cisco del BGP è passata, con l'introduzione della funzione "BGP Next-Hop Tracking" (da qui in poi abbreviata in BGP NHT), da una gestione time-driven a una gestione event-driven.
D'altro canto, questa funzione è stata sempre implementata nel JUNOS, che ha quindi utilizzato sempre un approccio di tipo event-driven (almeno a mia memoria, non ho informazioni sulla versione 1.1 del JUNOS !).
Vediamo allora un po' più da vicino come la funzione BGP NHT è implementata nei router Cisco. L'idea è quella di permettere al processo BGP di registrare i possibili BGP Next-Hop (con un processo chiamato "RIB watcher") e quindi di chiedere una sorta di avviso ogniqualvolta vi sia una variazione sulla raggiungibilità del BGP Next-Hop (in realtà, non solo la raggiungibilità, ma un qualsiasi cambio riguardante la raggiungibilità del BGP Next-Hop, come ad esempio il costo IGP per raggiungerlo, che ricordo, ha un impatto sul processo di selezione BGP). Si noti che il numero di BGP Next-Hop è di gran lunga inferiore al numero di prefissi appresi via BGP , per cui la funzione BGP NHT non è molto pesante per la CPU, né per il consumo di memoria (si pensi ad esempio a un router che riceve la Full Internet Routing Table da due ISP; i prefissi sono dell'ordine delle centinaia di migliaia (ad oggi più di 530k !), ma i BGP Next-Hop sono solo due).
Vediamo ora alcuni aspetti di configurazione nei router Cisco. Innanzitutto, in tutte le nuove versioni IOS (IOS, IOS XE, IOS XR, ecc.) la funzione BGP NHT è implementata di default (nell'IOS a partire dalle 12.0(29)S e 12.3(14)T). Può essere solo disabilitata (ad esempio, nel caso di flap del BGP Next-Hop, non risolto da meccanismi di damping, in altri casi solo se si viene colti da una sindrome tafazziana !) con il comando seguente:
router(config)# router bgp <numero-AS>
router(config-router)# address-family ...
router(config-router-af)# no bgp nexthop trigger enable
Vi sono due altri aspetti di configurazione su cui vale la pena soffermarsi. Il primo riguarda il ritardo con cui il processo BGP utilizza le informazioni sui BGP Next-Hop ricevute dal protocollo IGP. Di default il BGP utilizza queste informazioni dopo un ritardo di 5 sec. Questo perché si da modo al BGP di collezionare più eventi comunicati dal protocollo IGP, e quindi di ottimizzarne l'elaborazione. Tipicamemente questo ritardo dovrebbe essere configurato a un valore leggermente superiore alla velocità di convergenza del protocollo IGP, ma è possibile anche configurarlo nullo, per fare in modo che ogni evento comunicato dal protocollo IGP venga elaborato immediatamente (attenzione però che questo potrebbe causare possibili oscillazioni delle route BGP, a causa di oscillazioni (cambi di stato) del BGP Next-Hop). Per variare questo ritardo, si utilizza il comando seguente:
router(config)# router bgp <numero-AS>
router(config-router)# address-family ...
router(config-router-af)# bgp nexthop trigger delay <valore-in-sec>
Nei router 3825 del nostro laboratorio (IOS 15.1(3)T), l'intervallo dei valori ammessi è [0, 100].
L'altro aspetto di configurazione interessante, riguarda un problema che abbiamo già incontrato nel Post precedente quando abbiamo parlato del comando "neighbor ... fall-over": l'aggregazione di prefissi o la presenza nella RIB di una default-route, rende la funzione BGP NHT priva di efficacia. Infatti, se ad esempio nella propria RIB un router ha una default-route, o un prefisso aggregato che contiene un BGP Next-Hop, un eventuale cambio di stato del BGP Next-Hop non viene riportato al processo BGP, poiché nulla cambia nella RIB circa la raggiungibilità.
La "via di fuga" è utilizzare la funzionalità NHT estesa "BGP Selective Address Tracking" (introdotta a partire dall'IOS 12.4(4)T), che consente di selezionare a quali prefissi IP debbano appartenere i BGP Next-Hop da monitorare. Il comando che consente di attivare questa funzionalità è il seguente:
router(config)# router bgp <numero-AS>
router(config-router)# address-family ...
router(config-router-af)# bgp nexthop route-map <nome-route-map>
dove la route-map consente di definire l'insieme dei BGP Next-Hop da monitorare. Se un BGP Next-Hop non appartiene a un prefisso permesso dalla route-map, questo viene considerato irraggiungibile. Di conseguenza, tutti i prefissi appresi via BGP che hanno questo BGP Next-Hop, non partecipano al processo di selezione BGP. Si noti che le uniche due condizioni "match" permesse nella route-map sono "match ip address ..." e "match source-protocol ...".
Vediamo ora con un esempio il funzionamento del "BGP Selective Address Tracking". Consideriamo lo scenario della figura seguente:
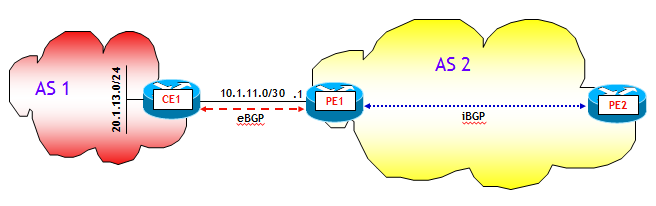
La sessione eBGP tra i router CE1 e PE1 è di tipo standard e utilizza come indirizzi IP gli indirizzi delle interfacce agli estremi del collegamento punto-punto. Inoltre, sul router PE1 non è stata configurata la funzione "next-hop-self", ne la subnet 10.1.11.0/30 è stata redistribuita nel protocollo IGP dell'AS 2. Ne consegue che su PE2, l'annuncio del prefisso 20.1.13.0/24 non è valido poiché per PE2 il BGP Next-Hop 10.1.11.2 non è raggiungibile:
PE2# show bgp ipv4 unicast 20.1.13.0 255.255.255.0
BGP routing table entry for 20.1.13.0/24, version 7
Paths: (1 available, no best path)
Flag: 0x820
Not advertised to any peer
1
10.1.11.2 (inaccessible) from 192.168.0.11 (192.168.0.11)
Origin IGP, metric 0, localpref 100, valid, internal
Ora, supponiamo di configurare su PE2 una route statica fittizia con Next-Hop = null0, verso un prefisso IP che sia supernet del prefisso 10.1.11.0/30:
PE2(config)# ip route 10.1.0.0 255.255.0.0 null0
Incredibile ma vero, l'annuncio del prefisso 20.1.13.0/24 diventa valido, anche se per PE2 il BGP Next-Hop 10.1.11.2 rimane ovviamente irraggiungibile:
PE2# show bgp ipv4 unicast 20.1.13.0 255.255.255.0
BGP routing table entry for 20.1.13.0/24, version 8
Paths: (1 available, best #1, table Default-IP-Routing-Table)
Flag: 0x820
Not advertised to any peer
1
10.1.11.2 from 192.168.0.11 (192.168.0.11)
Origin IGP, metric 0, localpref 100, valid, internal, best
Devo confessare che questo comportamento dell'IOS Cisco (e anche del JUNOS, come ho verificato con delle prove di laboratorio) ancora oggi mi lascia perplesso poiché si viola uno dei principi sacri del BGP: un annuncio può partecipare al processo di selezione BGP se e solo se il Next-Hop è raggiungibile (questo almeno recita RFC 4271). Non voglio entrare in una disputa accademica su questo comprtamento (ne ho avuta già una con il mio amico Ivan Pepelnjak, che asserisce che l'implementazione Cisco (e Juniper) è corretta, ma io non ne sono convinto). Vediamo però come con l'ausilio della funzione "BGP Selective Address Tracking" sia possibile rimettere le cose al loro posto. Spesso un BGP Next-Hop proviene da un prefisso /32 (tipico esempio quando si utilizzano per le sessioni BGP le interfacce di loopback) o da prefissi /30 o /31 (tipico esempio quando si utilizzano per le sessioni BGP gli indirizzi IP delle interfacce fisiche di collegamenti punto-punto). Con la funzione "BGP Selective Address Tracking" è possibile restringere l'insieme dei BGP Next-Hop validi, ad esempio consentendo validi solo i BGP Next-Hop che appartengono a prefissi nella RIB, che hanno lunghezza della maschera 30, 31 o 32. Questa è la configurazione da eseguire:
ip prefix-list GE-30 seq 5 permit 0.0.0.0/0 ge 30
!
route-map TEST permit 10
match ip address prefix-list GE-30
!
router bgp 2
bgp nexthop route-map TEST
L'annuncio BGP del prefisso 20.1.13.0/24, con questa configurazione non partecipa più al processo di selezione BGP, poiché l'unico prefisso nella RIB che lo contiene è il prefisso 10.1.0.0/16 (inserito con la route statica fittizia), che però non ha maschera superiore o al più uguale a 30, per cui non viene considerato per definire la raggiungibilità del BGP Next-Hop:
PE2# show bgp ipv4 unicast | i 20.1.13.0
* i20.1.13.0/24 10.1.11.2 0 100 0 1 i
LAB TEST
Della serie "se non vedo non credo", per verificare il funzionamento del BGP NHT ho effettuato una prova di laboratorio che mostra la differenza nei tempi di convergenza tra il BGP time-driven, ossia con la funzione NHT disabilitata, e il BGP event-driven. Lo scenario della prova è riportato nella figura seguente:
Le configurazioni base del BGP sui tre router sono le seguenti:
hostname PE1
!
router bgp 1
neighbor 10.1.99.11 remote-as 21
neighbor 10.1.99.11 ebgp-multihop 255
neighbor 10.1.99.11 update-source Loopback0
neighbor 192.168.0.12 remote-as 2
neighbor 192.168.0.12 ebgp-multihop 255
neighbor 192.168.0.12 update-source Loopback0
!
hostname PE2
!
router bgp 2
neighbor 10.1.12.6 remote-as 21
neighbor 192.168.0.11 remote-as 1
neighbor 192.168.0.11 ebgp-multihop 255
neighbor 192.168.0.11 update-source Loopback0
!
hostname CE1
!
router bgp 21
network 30.1.1.0 mask 255.255.255.0
neighbor 10.1.12.5 remote-as 2
neighbor 192.168.0.11 remote-as 1
neighbor 192.168.0.11 ebgp-multihop 255
neighbor 192.168.0.11 update-source Loopback0
Supponiamo inizialmente di disabilitare sul router PE1 la funzione BGP NHT:
router bgp 1
address-family ipv4
no bgp nexthop trigger enable
e di attivare il "debug ip routing":
PE1# debug ip routing
Come passo successivo, mettiamo in "shutdown" l'interfaccia Loopback 0 di CE1, che è quella utilizzata per la sessione eBGP multi-hop con PE1:
CE1(config)# interface loopback 0
CE1(config-if)# shutdown
Vediamo cosa accade su PE1. Innanzitutto, con i tempi di convergenza del protocollo IGP (che nel mio caso è l'OSPF base, con i timer non ottimizzati), PE1 cancella dalla propria RIB il prefisso 10.1.99.11/32 (indirizzo dell'interfaccia Loopback 0 di CE1):
*Oct 31 13:59:37.407: RT: del 10.1.99.11 via 10.1.11.2, ospf metric [110/65]
*Oct 31 13:59:37.407: RT: delete subnet route to 10.1.99.11/32
Ho verificato quindi immediatamente la Tabella BGP di PE1, dalla quale si vede che PE1 ancora crede che il suo BGP Next-Hop sia 10.1.99.11:
PE1# show bgp ipv4 unicast
(output omesso)
Network Next Hop Metric LocPrf Weight Path
* 30.1.1.0/24 192.168.0.12 0 2 21 i
*> 10.1.99.11 0 0 21 i
Ma ovviamente l'indirizzo 10.1.99.11 non è più raggiungibile:
PE1# ping 10.1.99.21
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 10.1.99.21, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
Cosa sta accadendo ? Semplice, il processo BGP scanner su PE1 (che ha un periodo di default di 60 sec, che ho lasciato inalterato) ancora non ha verificato la raggiungibilità del BGP Next-Hop, che rimane quindi quello iniziale. Dopo un po', il processo riprende la verifica di raggiungibilità del BGP Next-Hop, e poiché si accorge che questo non è più raggiungibile dalla RIB, riesegue il processo di selezione BGP e converge sul best-path alternativo 192.168.0.12.
*Oct 31 14:00:32.487: RT: updating bgp 30.1.1.0/24 (0x0): via 192.168.0.12
*Oct 31 14:00:32.487: RT: closer admin distance for 30.1.1.0, flushing 1 routes
*Oct 31 14:00:32.487: RT: add 30.1.1.0/24 via 192.168.0.12, bgp metric [20/0]
PE1# show bgp ipv4 unicast
(output omesso)
Network Next Hop Metric LocPrf Weight Path
*> 30.1.1.0/24 192.168.0.12 0 2 21 i
* 10.1.99.11 0 0 21 i
Quanto ha impiegato il BGP a convergere sul nuovo best-path ? Presto detto, dagli output dei debug si evince un tempo di poco più di 35 sec ! E mi è andata bene, il tempo poteva anche essere maggiore, visto che il periodo di scanning è 60 sec.
Abilitiamo ora il BGP NHT. Per corretteza dovrei dire "riabilitiamo" il BGP NHT, perché come già detto il BGP NHT è abilitato di default nelle versioni IOS recenti (per la cronaca, il router PE1 è un Cisco 3825 con IOS 15.1(3)T).
Abilitiamo ora il BGP NHT. Per corretteza dovrei dire "riabilitiamo" il BGP NHT, perché come già detto il BGP NHT è abilitato di default nelle versioni IOS recenti (per la cronaca, il router PE1 è un Cisco 3825 con IOS 15.1(3)T).
router bgp 1
address-family ipv4
bgp nexthop trigger enable
Ripetendo la procedura precedente, ecco cosa accade su PE1:
*Oct 31 14:10:32.843: RT: del 10.1.99.11 via 10.1.11.2, ospf metric [110/65]
*Oct 31 14:10:32.843: RT: delete subnet route to 10.1.99.11/32
*Oct 31 14:10:37.843: RT: updating bgp 30.1.1.0/24 (0x0): via 192.168.0.12
*Oct 31 14:10:37.843: RT: closer admin distance for 30.1.1.0, flushing 1 routes
*Oct 31 14:10:37.843: RT: add 30.1.1.0/24 via 192.168.0.12, bgp metric [20/0]
Come si può notare, adesso il BGP converge sul best-path alternativo 192.168.0.12, dopo soli 5 sec, che è il valore di default del BGP NHT "trigger delay". Ho rifatto la prova ponendo a zero questo valore:
router bgp 1
address-family ipv4
bgp nexthop trigger delay 0
Ecco il risultato:
*Oct 31 14:13:48.591: RT: del 10.1.99.11 via 10.1.11.2, ospf metric [110/65]
*Oct 31 14:13:48.591: RT: delete subnet route to 10.1.99.11/32
*Oct 31 14:13:48.595: RT: updating bgp 30.1.1.0/24 (0x0): via 192.168.0.12
*Oct 31 14:13:48.595: RT: closer admin distance for 30.1.1.0, flushing 1 routes
*Oct 31 14:13:48.595: RT: add 30.1.1.0/24 via 192.168.0.12, bgp metric [20/0]
Il tempo di convergenza è diventato 4 ms !!! Attenzione però, questo è solo il tempo impiegato dal router PE1 per convergere al nuovo best-path. Il tempo di convergenza complessivo dipende dal tempo impiegato dal protocollo IGP a comunicare a PE1 il fuori servizio dell'interfaccia Loopback 0 di CE1. E questo apre a una interessante considerazione, il tempo di convergenza del BGP dipende fortemente dal tempo di convergenza del protocollo IGP. Ma su questo avremo modo di ritornare nei prossimi Post.
BGP FALLOVER E BGP NHT : DIFFERENZE
A volte sorge il sospetto (o il dubbio) che la funzionalità "BGP Fallover", introdotta nel Post precedente sulla convergenza del BGP, abbia lo stesso scopo della funzione BGP NHT, e che quindi una delle due sia inutile. Per evitare qualsiasi dubbio e confusione, voglio, per chiudere, mettere in evidenza le differenze tra queste due funzioni. Come visto nel precedente Post, la funzionalità "BGP Fallover" serve per chiudere una sessione i/eBGP, a fronte della perdita della raggiungibilità dell'indirizzo del BGP peer, ossia, quando non vi è più nella RIB un percorso per raggiungere l'indirizzo IP del BGP peer.
Come invece ampiamente visto in questo Post, il BGP NHT è un criterio event-driven che serve a verificare la raggiungibilità del BGP Next-Hop (che non necessariamente coincide con l'indirizzo del BGP peer; un esempio tipico si ha in presenza di Route Reflector, dove BGP Next-Hop e indirizzo del BGP peer non coincidono praticamente mai). Qualora il BGP Next-Hop non fosse più raggiungibile, la sessione BGP non verrebbe necessariamente chiusa (a meno che il BGP Next-Hop non coincida con l'indirizzo del BGP peer, come ad esempio quando si utilizza il comando "neighbor ... next-hop-self", o quando un router inserisce localmente nella Tabella BGP un prefisso da propagare), ma il processo BGP si limita a ritirare il prefisso, al ricalcolo del best-path e al riannuncio del nuovo best-path. Nel caso in cui non vi sia un nuovo best-path disponibile, il prefisso viene solo ritirato.
CONCLUSIONI
Con questo Post ho aggiunto un altro piccolo tassello per sfatare il mito della convergenza lenta del BGP. Vi avverto però, la strada da fare è ancora lunga, mancano all'appello concetti e funzionalità importanti come la PIC (Prefix Independent Convergence), Add-Path, BGP best-external, Diverse-Path e altro ancora. Prometto che alla fine raccoglierò tutti questi Post in un documento organico sulla convergenza del BGP, che sarà reso disponibile in download gratuito su questo Blog.
Volete saperne una più del diavolo sul BGP ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247 (nel qual caso il libro è parte della documentazione del corso).
Volete saperne una più del diavolo sul BGP ? Acquistate il mio libro "BGP: dalla teoria alla pratica" (al prezzo speciale di 30 Euro per gli utenti registrati al sito, spese di spedizione gratuite). Oppure seguite i nostro corsi IPN246 e IPN247 (nel qual caso il libro è parte della documentazione del corso).
Pubblicato in
ReissBlog
Etichettato sotto
Domenica, 16 Novembre 2014 08:19
BFD: DOCUMENTO RIASSUNTIVO
Ho raccolto in un piccolo documento di 37 pagine, il contenuto dei miei due post precedenti sul BFD. Ho inserito qualche dettaglio in più sull'autenticazione dei messaggi BFD e sulle configurazioni del BFD per IS-IS e BGP. Infine, ho inserito qualche cenno sul BFD over LAG (RFC 7130).
Può esservi utile per la vostra biblioteca tecnica.
Vi ricordo che per il download del documento dovete essere registrati al nostro sito.
Vi ricordo che per il download del documento dovete essere registrati al nostro sito.
Buona lettura !!!
Coming up next ... il capitolo 4 del libro su IS-IS.
{phocadownload view=file|id=14|text=BFD_TT|target=s}
{phocadownload view=file|id=14|text=BFD_TT|target=s}
Pubblicato in
ReissBlog
Etichettato sotto
Giovedì, 23 Ottobre 2014 20:16
IL BFD : QUESTO SCONOSCIUTO - PARTE II
Come promesso nel Post precedente sul BFD, in questo vedremo come implementarlo in pratica. Come al solito darò solo le idee fondamentali, tralasciando molti dettagli per i quali potete consultare la documentazione ufficiale dei costruttori. Illustrerò le configurazioni più importanti nelle piattaforme Cisco e Juniper, ed esporrò i risultati di prove reali di laboratorio, con i router che abbiamo a disposizione. Le prove riguarderanno la sola versione single-hop, che è quella utilizzata nella quasi totalità delle applicazioni pratiche.
NOTA: mentre stavo terminando di scrivere questo Post, è comparso sul blog del mio amico Ivan Pepelnjak un Post dal titolo "MICRO-BFD: BFD OVER LAG (PORT CHANNEL)", che tratta dell'applicazione del BFD su collegamenti "bundle", meglio noti tra i cultori delle reti Switched Ethernet (tra i quali non c'è il sottoscritto !) come "Port Channel", o Etherchannel, o LAG (Link Aggregation Group). L'argomento è interessante ed è stato oggetto della RFC 7130 "Bidirectional Forwarding Detection (BFD) on Link Aggregation Group (LAG) Interfaces", del Febbraio 2014. Il (semplice) meccanismo utilizzato, noto come Micro-BFD è già implementato nel JUNOS a partire dalla versione 13.3, e nelle versioni più recenti dei sistemi operativi Cisco NX-OS e IOS-XR. Mi riprometto in seguito di affrontare l'argomento in un Post dedicato.
IMPLEMENTAZIONE CISCO (IOS E IOS XR)
L'implementazione Cisco differisce abbastanza sia nello stile di configurazione che nei default utilizzati, tra IOS e IOS XR. Non ho l'opportunità di fare delle prove con il NX-OS dei Nexus, ma da quel poco che ho visto le configurazioni sono simili a quelle dell'IOS. Stesso discorso vale per l'IOS XE.
Prima di illustrare le prove effettuate, alcune considerazioni generali. L'implementazione Cisco supporta il BFD per tutti i principali protocolli di routing IPv4/IPv6 (EIGRP, OSPF, IS-IS, BGP, PIM), per le route statiche IPv4/IPv6, per i tunnel MPLS-TE e per protocolli di High Availability come HSRP e VRRP (per eventuali restrizioni è sempre comunque opportuno verificare la documentazione relativa alla versione IOS/IOS XR che si sta utilizzando).
I messaggi BFD HELLO vengono inviati utilizzando come indirizzi IP sorgente e destinazione:
- Nel caso di sessioni BFD IPv4, rispettivamente l'indirizzo dell'interfaccia da dove vengono trasmessi i messaggi, e indirizzo IP destinazione l'estremo remoto comunicato da un protocollo Client.
- Nel caso di sessioni BFD IPv6, gli indirizzi link-local associati alle interfacce locale e remota (NOTA: per chi non fosse familiare con IPv6, gli indirizzi link-local hanno come ambito di propagazione un segmento di rete, come ad esempio un link punto-punto, e sono parte del prefisso IPv6 fe80::/10. Tipicamente assumono la forma fe80::/64).
I messaggi BFD ECO, nell'IOS vengono inviati con indirizzo IP sorgente l'indirizzo dell'interfaccia da dove vengono trasmessi i messaggi; nell'IOS XR viene utilizzato il router-id globale, se configurato, altrimenti lo stesso indirizzo utilizzato nell'IOS. Nell'IOS XR è anche possibile sceglierlo con il comando "echo ipv4 source <indirizzo-IP>", eseguito a livello di protocollo BFD o a livello di interfaccia all'interno della configurazione del protocollo BFD. Ad esempio, se si volesse utilizzare l'indirizzo IP sorgente 1.1.1.1 per tutte le sessioni BFD, la configurazione da eseguire è la seguente:
RP/0/RP0/CPU0:router(config)# bfd
RP/0/RP0/CPU0:router(config-bfd)# echo ipv4 source 1.1.1.1
Qualore si volesse utilizzare l'indirizzo 2.2.2.2, ad esempio per l'interfaccia "Gigabitethernet 0/2/0/0", la configurazione da eseguire è la seguente:
RP/0/RP0/CPU0:router(config)# bfd
RP/0/RP0/CPU0:router(config-bfd)# interface gigabitethernet 0/2/0/0
RP/0/RP0/CPU0:router(config-bfd-if)# echo ipv4 source 2.2.2.2
Conformemente alla RFC 5881, i messaggi BFD vengono inviati con TTL IP pari a 255. Questo consente di evitare lo spoofing dei messaggi BFD, utilizzando la funzionalità Generalized TTL Security Mechanism (GTSM), standardizzata nella RFC 5082 (NOTA: la funzionalità GTSM non è peculiare del BFD, ma è molto generale e utilizzata anche da altri protocolli, come ad esempio il BGP).
Infine, le porte UDP utilizzate:
- Nei messaggi BFD HELLO: porta sorgente 49152, porta destinazione 3784.
- Nei messaggi BFD ECO: porta sorgente e porta destinazione 3785.
Passiamo ora alle prove di laboratorio. Nelle prove che ho effettuato mi sono avvalso di un router Cisco 3825 con IOS 15.1(3)T e del nostro vecchio glorioso GSR 12k, con IOS XR 4.2.4. Lo schema della rete di prova è riportato nella figura seguente:
Poiché la configurazione del BFD associato al protocollo BGP è già stata vista nel precedente Post sulla convergenza del BGP (Parte I), ho attivato sul collegamento un'adiacenza OSPFv2, una OSPFv3 e ho configurato due route statiche (IPv4) per mettere in comunicazione le due interfacce Loopback 0 tra i due router. Per cercare di rendere la prova più interessante ho utilizzato valori dei timer BFD e del Detect Mult diversi. Così, facendo queste prove ho scoperto molte cose interessanti. Innanzitutto le configurazioni rilevanti:
hostname PE1-1
!
interface GigabitEthernet0/1
ip address 172.16.1.111 255.255.255.0
ip ospf 1 area 0
ip ospf bfd
ipv6 enable
ipv6 ospf bfd
ipv6 ospf 1 area 0
bfd interval 150 min_rx 100 multiplier 3
!
ip route static bfd GigabitEthernet0/1 172.16.1.113
ip route 192.168.0.13 255.255.255.255 GigabitEthernet0/1 172.16.1.113
hostname PE1-3
!
router static
address-family ipv4 unicast
192.168.0.11/32 172.16.1.111 bfd fast-detect minimum-interval 150 multiplier 3
!
!
router ospf 1
area 0
interface GigabitEthernet0/2/0/0
bfd minimum-interval 100
bfd fast-detect
bfd multiplier 5
!
!
!
router ospfv3 1
area 0
interface GigabitEthernet0/2/0/0
bfd multiplier 4
bfd fast-detect
bfd minimum-interval 150
!
!
!
Prima di vedere i risultati della prova, una considerazione sulle configurazioni. Nell'IOS, l'abilitazione del BFD richiede due passi:
- La definizione all'interno della configurazione dell'interfaccia locale del collegamento da monitorare, dei due timer Desired Min TX Interval e Required Min RX Interval e del Detect Mult. I valori utilizzati nella configurazione di PE1-1 sono rispettivamente 150 ms, 100 ms e 3.
- Associare il BFD al protocollo. Nel caso dell'OSPFv2 questo può essere fatto in due modi: o con il comando "ip ospf bfd" a livello interfaccia. In alternativa, se tutte le interfacce abilitate OSPF utilizzano anche il BFD, si può eseguire il comando "bfd all-interfaces" a livello di processo OSPF:
PE1-1(config)#int GigabitEthernet0/1
PE1-1(config-if)#no ip ospf bfd
PE1-1(config)#router ospf 1
PE1-1(config-router)#bfd all-interfaces
Qualora si volesse disattivare il BFD su una particolare interfaccia (es. la GigabitEthernet0/2), è possibile farlo attraverso il seguentre comando:
PE1-1(config)#int GigabitEthernet0/2
PE1-1(config-if)#ip ospf bfd disable
Gli stessi identici comandi valgono per OSPFv3. E' sufficiente sostituire nei comandi "ip" con "ipv6".
Per contro nell'IOS XR, tutte le configurazioni del BFD vanno eseguite all'interno dei processi OSPFv2/v3. Inoltre, una cosa che salta subito all'occhio è che l'IOS XR non prevede la possibilità di differenziare i due timer Desired Min TX Interval e Required Min RX Interval, ma è possibile solo configurarli uguali, con il comando "bfd minimum-interval <valore-in-ms>". Il valore di Detect Mult potrebbe anche non essere configurato, nel qual caso l'IOS XR assegna il valore di default 3.
Un discorso a parte merita l'abilitazione del BFD sulle route statiche, sia IPv4 che IPv6, poiché non vi è come in OSPF, BGP, ecc. un modo automatico per comunicare al BFD l'indirizzo IP estremo remoto della sessione, non essendoci nessuna adiacenza o sessione stabilite in modo automatico. E' necessario quindi comunicare manualmente al BFD quale è l'indirizzo IP del BFD peer. Nell'IOS questo avviene con il comando a livello globale "ip route static bfd <interfaccia> <next-hop>". Si noti che nel comando è obbligatorio specificare l'interfaccia all'estremo locale del collegamento da monitorare. Inoltre è obbligatorio specificare l'interfaccia anche nella route statica, altrimenti l'associazione BFD route statica non avviene (NOTA: nella route statica l'indirizzo IP del Next-Hop non è necessario, ma io lo metto sempre comunque).
Questo comando crea un'associazione tra BFD e la route statica che ha come interfaccia Next-Hop e indirizzo IP Next-Hop quelli specificati nel comando. Ma cosa accade se nel router non è configurata alcuna route statica, magari perché un percorso verso la destinazione è stato appreso attraverso un altro protocollo ? Nessun problema, è sufficente aggiungere in coda al comando la parola chiave "unassociate" e il gioco è fatto. Questa parola chiave indica al router di completare comunque le procedure per l'apertura della sessione BFD anche in assenza di una route statica configurata.
Nell'IOS XR è sufficiente specificare timer e Detect Mult dopo il Next-Hop, come mostrato nella configurazione sopra. Non ho trovato tra la documentazione un concetto simile alla parola chiave "unassociate".
Vediamo ora il risultato della configurazione. Per questo l'IOS ha il comando "show bfd neighbors [detail]" e l'IOS XR l'analogo comando "show bfd all session [detail]". (NOTA: per tutte le altre opzioni disponibili rimandiamo alla documentazione Cisco).
Vediamo l'esecuzione di entrambi i comandi con la parola chiave "detail" su entrambi i router.
PE1-1# show bfd neighbors detail
NeighAddr LD/RD RH/RS State Int
172.16.1.113 2/-2146959355 Up Up Gi0/1
Session state is UP and using echo function with 150 ms interval.
OurAddr: 172.16.1.111
Local Diag: 0, Demand mode: 0, Poll bit: 0
MinTxInt: 1000000, MinRxInt: 1000000, Multiplier: 3
Received MinRxInt: 2000000, Received Multiplier: 3
Holddown (hits): 0(0), Hello (hits): 2000(102)
Rx Count: 98, Rx Interval (ms) min/max/avg: 460/1984/1817 last: 180 ms ago
Tx Count: 104, Tx Interval (ms) min/max/avg: 1/2000/1711 last: 220 ms ago
Elapsed time watermarks: 0 0 (last: 0)
Registered protocols: IPv4 Static OSPF
Uptime: 00:02:54
Last packet: Version: 1 - Diagnostic: 0
State bit: Up - Demand bit: 0
Poll bit: 0 - Final bit: 0
Multiplier: 3 - Length: 24
My Discr.: -2146959355 - Your Discr.: 2
Min tx interval: 2000000 - Min rx interval: 2000000
Min Echo interval: 1000
NeighAddr LD/RD RH/RS State Int
FE80::204:DEFF:FE51:CC70 1/-2146959358 Up Up Gi0/1
Session state is UP and not using echo function.
OurAddr: FE80::FEFB:FBFF:FE35:DE71
Local Diag: 0, Demand mode: 0, Poll bit: 0
MinTxInt: 150000, MinRxInt: 100000, Multiplier: 3
Received MinRxInt: 250000, Received Multiplier: 4
Holddown (hits): 788(0), Hello (hits): 250(847)
Rx Count: 814, Rx Interval (ms) min/max/avg: 36/272/230 last: 212 ms ago
Tx Count: 846, Tx Interval (ms) min/max/avg: 192/252/221 last: 204 ms ago
Elapsed time watermarks: 0 0 (last: 0)
Registered protocols: OSPFv3
Uptime: 00:03:07
Last packet: Version: 1 - Diagnostic: 0
State bit: Up - Demand bit: 0
Poll bit: 0 - Final bit: 0
Multiplier: 4 - Length: 24
My Discr.: -2146959358 - Your Discr.: 1
Min tx interval: 250000 - Min rx interval: 250000
Min Echo interval: 0
RP/0/0/CPU0:PE1-3#show bfd all session detail
Mon Oct 20 18:15:21.316 UTC
IPv4:
-----
I/f: GigabitEthernet0/2/0/0, Location: 0/2/CPU0
Dest: 172.16.1.111
Src: 172.16.1.113
State: UP for 0d:0h:4m:3s, number of times UP: 1
Session type: PR/V4/SH
Received parameters:
Version: 1, desired tx interval: 1 s, required rx interval: 1 s
Required echo rx interval: 100 ms, multiplier: 3, diag: None
My discr: 2, your discr: 2148007941, state UP, D/F/P/C/A: 0/0/0/0/0
Transmitted parameters:
Version: 1, desired tx interval: 2 s, required rx interval: 2 s
Required echo rx interval: 1 ms, multiplier: 3, diag: None
My discr: 2148007941, your discr: 2, state UP, D/F/P/C/A: 0/0/0/1/0
Timer Values:
Local negotiated async tx interval: 2 s
Remote negotiated async tx interval: 2 s
Desired echo tx interval: 150 ms, local negotiated echo tx interval: 150 ms
Echo detection time: 450 ms(150 ms*3), async detection time: 6 s(2 s*3)
Local Stats:
Intervals between async packets:
Tx: Number of intervals=100, min=1665 ms, max=1991 ms, avg=1832 ms
Last packet transmitted 1573 ms ago
Rx: Number of intervals=100, min=1510 ms, max=1992 ms, avg=1748 ms
Last packet received 691 ms ago
Intervals between echo packets:
Tx: Number of intervals=50, min=7701 ms, max=7701 ms, avg=7701 ms
Last packet transmitted 69 ms ago
Rx: Number of intervals=50, min=7700 ms, max=7702 ms, avg=7700 ms
Last packet received 68 ms ago
Latency of echo packets (time between tx and rx):
Number of packets: 100, min=0 us, max=2 ms, avg=530 us
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ipv4_static 150 ms 3 2 s 3
ospf-1 100 ms 5 2 s 5
IPv6:
-----
I/f: GigabitEthernet0/2/0/0, Location: 0/2/CPU0
Dest: fe80::fefb:fbff:fe35:de71
Src: fe80::204:deff:fe51:cc70
State: UP for 0d:0h:4m:16s, number of times UP: 1
Session type: PR/V6/SH
Received parameters:
Version: 1, desired tx interval: 150 ms, required rx interval: 100 ms
Required echo rx interval: 0 us, multiplier: 3, diag: None
My discr: 1, your discr: 2148007938, state UP, D/F/P/C/A: 0/0/0/0/0
Transmitted parameters:
Version: 1, desired tx interval: 250 ms, required rx interval: 250 ms
Required echo rx interval: 0 us, multiplier: 4, diag: None
My discr: 2148007938, your discr: 1, state UP, D/F/P/C/A: 0/0/0/1/0
Timer Values:
Local negotiated async tx interval: 250 ms
Remote negotiated async tx interval: 250 ms
Desired echo tx interval: 0 s, local negotiated echo tx interval: 0 s
Echo detection time: 0 s(0 s*4), async detection time: 750 ms(250 ms*3)
Local Stats:
Intervals between async packets:
Tx: Number of intervals=100, min=211 ms, max=251 ms, avg=228 ms
Last packet transmitted 7 ms ago
Rx: Number of intervals=100, min=191 ms, max=252 ms, avg=221 ms
Last packet received 135 ms ago
Intervals between echo packets:
Tx: Number of intervals=0, min=0 s, max=0 s, avg=0 s
Last packet transmitted 0 s ago
Rx: Number of intervals=0, min=0 s, max=0 s, avg=0 s
Last packet received 0 s ago
Latency of echo packets (time between tx and rx):
Number of packets: 0, min=0 us, max=0 us, avg=0 us
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ospfv3-1 150 ms 4 250 ms 4
Label:
------
------
Sulla base della configurazione effettuata, i due router stabiliscono due sessioni BFD, una per IPv4 (protocolli Client OSPFv2 e Route Statica) e una per IPv6 (protocollo Client OSPFv3).
Vediamo dapprima le caratteristiche della sessione BFD per IPv4. Prima considerazione: l'IOS e IOS XR, per la sessione BFD IPv4, utilizzano di default la funzione eco. Ciò si evince ad esempio dal comando "show bfd neighbors detail" sul router PE1-1, dove alla terza riga si legge: "Session state is UP and using echo function with 150 ms interval.". Il periodo dei messaggi BFD ECO (= 150 ms) coincide con il valore di configurazione "bfd interval <valore-in-ms> ...", definito a livello interfaccia. L'Holdtime (non riportato nella visualizzazione IOS) è pari 150*3 = 450 ms, dove 3 è il valore di Detect Mult configurato nel comando "bfd ... multiplier <valore-Detect-Mult>".
La funzione eco può essere disabilitata sia per l'IOS, con il comando a livello interfaccia "no bfd echo", che per l'IOS XR con il comando "echo disable" all'interno della configurazione del protocollo BFD:
RP/0/0/CPU0:PE1-3#(config)# bfd
RP/0/0/CPU0:PE1-3#(config-bfd)# echo disable
Seconda considerazione: l'IOS e IOS XR utilizzano valori di default diversi per il periodo di trasmissione dei messaggi BFD HELLO (che, ricordiamo, vengono scambiati comunque, ma molto più lentamente). L'IOS utilizza il valore di default 1 sec, l'IOS XR il valore 2 sec. Questo si evince dalla sesta e settima riga del comando "show bfd neighbors detail" sul router PE1-1:
MinTxInt: 1000000, MinRxInt: 1000000, Multiplier: 3
Received MinRxInt: 2000000, Received Multiplier: 3
dove MinTxInt è il valore del Desired Min TX Interval (= 1000000 microsec = 1 sec), MinRxInt è il valore del Required Min RX Interval (= 1000000 microsec = 1 sec). Il valore di Detec Mult è pari a 3 (valore impostato su base configurazione). Il valore negoziato di periodo dei messaggi BFD HELLO è 2 sec (il valore massimo tra i due). Nell'IOS il valore del periodo dei messaggi BFD HELLO può essere variato con il comando globale "bfd slow timers <valore>". Non ho trovato un comando analogo nell'IOS XR.
Il comando IOS XR "show bfd all session detail" mette in evidenza sia i timer ricevuti che quelli inviati e i valori del periodo dei messaggi BFD HELLO negoziati sia locale che remoto.
Il comando IOS XR "show bfd all session detail" mette in evidenza sia i timer ricevuti che quelli inviati e i valori del periodo dei messaggi BFD HELLO negoziati sia locale che remoto.
Received parameters:
Version: 1, desired tx interval: 1 s, required rx interval: 1 s
Required echo rx interval: 100 ms, multiplier: 3, diag: None
My discr: 3, your discr: 2148007941, state UP, D/F/P/C/A: 0/0/0/0/0
Transmitted parameters:
Version: 1, desired tx interval: 2 s, required rx interval: 2 s
Required echo rx interval: 1 ms, multiplier: 3, diag: None
My discr: 2148007941, your discr: 3, state UP, D/F/P/C/A: 0/0/0/1/0
Timer Values:
Local negotiated async tx interval: 2 s
Remote negotiated async tx interval: 2 s
Si noti che nei parametri ricevuti e inviati sono specificati tutti i campi dei messaggi BFD HELLO, incluso lo stato della sessione BFD (= UP) e le varie flag presenti (D/F/P/C/A). E' interessante il valore della flag C, posto a 1 dal GSR12k e a 0 dal 3825. Questo indica che il GSR 12k elabora i messaggi BFD a livello di linecard, mentre il 3825 li elabora a livello di CPU.
Vediamo infine come viene determinato il valore del periodo dei messaggi BFD ECO. Abbiamo già visto quello su PE1-1, pari a 150 ms.
Prima di vedere come viene determinato su PE1-3, dobbiamo innanzitutto porci una domanda. Poiché la sessione BFD IPv4 è unica e ha due protocolli Client (OSPFv2 e route statica), che utilizzano timer e Detect Mult diversi, quali valori vengono utilizzati per determinare il periodo dei messaggi BFD ECO ? Si noti che questo problema per l'IOS non si pone poiché tutti i protocolli Client che utilizzano la stessa interfaccia utilizzano gli stessi timer e Detect Mult. Bene, l'IOS XR adotta un approccio secondo il quale vengono utilizzati i timer più aggressivi. La frase è un po' sibillina, ma questo è quanto riporta la documentazione Cisco dell'IOS XR versione 4.3: "When multiple applications share the same BFD session, the application with the most aggressive timer wins locally".
Ho fatto molte prove per capire il senso di questa affermazione, e quello che ho dedotto è l'IOS XR fa un conticino molto semplice: per ciascun protocollo Client determina il valore (Local min TX interval)*(Local Detect Mult). L'IOS XR prende quindi il valore minore e utilizza per la determinazione del valore del periodo dei messaggi BFD ECO e il calcolo dell'Holdtime i timer e Detect Mult relativi. Ad esempio, applicando su PE1-3 questo metodo si ha:
- Client Route Statica : (Local min TX interval)*(Local Detect Mult) = 150*3 = 450 ms
- Client OSPFv2 : (Local min TX interval)*(Local Detect Mult) = 100*5 = 500 ms
Poiché 450 < 500, PE1-3 utilizza un periodo di 150 ms per il periodo dei messaggi BFD ECO e di 450 ms per l'Holdtime. Ciò può essere verificato dalla visualizzazione riportata sopra (NOTA: l'Holdtime dei messaggi BFD HELLO è invece 2*3 = 6 sec):
Desired echo tx interval: 150 ms, local negotiated echo tx interval: 150 ms
Echo detection time: 450 ms(150 ms*3), async detection time: 6 s(2 s*3)
Al di la di questa disquisizione, ritengo opportuno utilizzare per tutti i protocolli Client gli stessi timer e Detect Mult, lasciando l'utilizzo di valori diversi solo a casi molto particolari.
Infine, l'ultima parte della visualizzazione del comando "show bfd all session detail" su PE1-3 mostra i protocolli Client della sessione BFD per IPv4: OSPFv2 e la route statica IPv4.
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ipv4_static 150 ms 3 2 s 3
ospf-1 100 ms 5 2 s 5
La stessa informazione sul router PE1-1 si ha nella riga "Registered protocols: IPv4 Static OSPF".
Mi sono divertito ad un certo punto ad abilitare la funzionalità di sicurezza unicast RPF sull'interfaccia Gi0/1 del router PE1-1, con il comando:
PE1-1(config)#interface GigabitEthernet0/1
PE1-1(config-if)#ip verify unicast source reachable-via rx
Ecco quello che è successo:
PE1-1(config-if)#
*Oct 16 10:22:35.407: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from FULL to DOWN, Neighbor Down: BFD node down
*Oct 16 10:22:39.459: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from LOADING to FULL, Loading Done
PE1-1(config-if)#
*Oct 16 10:22:42.499: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from FULL to DOWN, Neighbor Down: BFD node down
*Oct 16 10:22:48.987: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from LOADING to FULL, Loading Done
*Oct 16 10:22:55.835: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from FULL to DOWN, Neighbor Down: BFD node down
*Oct 16 10:22:58.159: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from LOADING to FULL, Loading Done
ossia un continuo up/down dell'adiacenza OSPF e della sessione BFD. Questo accade perché, come detto nel Post precedente sul BFD, la funzione eco è incompatibile con la funzionalità uRPF.
Vediamo ora le caratteristiche della sessione BFD per IPv6. La prima cosa da notare è che IOS e IOS XR per le sessioni BFD IPv6 non utilizzano la funzione eco, ma la semplice modalità asincrona. Si noti che i messaggi BFD HELLO utilizzano come indirizzi IPv6 sorgente e destinazione degli indirizzi link-local:
IPv6:
-----
I/f: GigabitEthernet0/2/0/0, Location: 0/2/CPU0
Dest: fe80::fefb:fbff:fe35:de71
Src: fe80::204:deff:fe51:cc70
Vediamo ora, dal punto di vista di PE1-3, la negoziazione dei timer e la determinazione dell'Holdtime (= detection time). I risultati si evincono dalla visualizzazione del comando "show bfd all session detail":
Timer Values:
Local negotiated async tx interval: 250 ms
Remote negotiated async tx interval: 250 ms
Desired echo tx interval: 0 s, local negotiated echo tx interval: 0 s
Echo detection time: 0 s(0 s*4), async detection time: 750 ms(250 ms*3)
Anche qui, ho scoperto una curiosità. Mi aspettavo infatti, su PE1-3, un valore del periodo negoziato dei messaggi BFD HELLO di 150 ms, ossia il valore massimo tra il Desired Min TX Interval (= 150 ms) locale e Required Min RX Interval ricevuto da PE1-1 (= 100 ms). Invece mi sono ritrovato come valore negoziato 250 ms. Dopo un po' di prove ho scoperto che l'IOS XR, per valori di "minimum interval" configurati, inferiori a 250 ms, aggiusta comunque il valore a 250 ms. Questo si evince dalla parte finale della visualizzazione del comando "show bfd all session detail":
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ospfv3-1 150 ms 4 250 ms 4
Il valore di Holdtime è quindi 250*3 = 750 ms (ricordiamo che nel calcolo viene utilizzato il valore di Detect Mult ricevuto, pari a 3, vedi Post precedente). Per contro, lasciamo al lettore verificare che il valore del periodo dei messaggi BFD HELLO e di Holdtime determinati da PE1-1 sono rispettivamente 250 ms e 250*4 = 1000 ms.
Questo completa le mie considerazioni sull'implementazione Cisco del BFD. Vi sarebbero molte altre cose da dire, ma il Post diventerebbe chilometrico. Quanto riportato sopra si concentra sugli aspetti più importanti e più utili per le applicazioni pratiche. Argomenti come l'autenticazione dei messaggi, il BFD damping (molto simile al BGP Route Flap damping), il BFD nei collegamenti bundle, ecc. sono stati volutamente tralasciati. Eventualmente ci tornerò in futuro con qualche altro Post. Chi invece vorrà cimentarsi con l'esame di certificazione CCIE dovrà necessariamente approfondire tutti gli aspetti di configurazione (nell'IOS o IOS XR, in funzione del tipo di certificazione).
IMPLEMENTAZIONE JUNIPER
Fortunatamente tutte le piattaforme Juniper sono basate sullo stesso sistema operativo, il JUNOS, e quindi questo renderà la trattazione più breve (NOTA: non considererò piattaforme basate sul JUNOSe, che comunque ha una CLI simile a quella Cisco).
La prima considerazione da fare circa l'implementazione BFD del JUNOS, è che non supporta la funzione eco (almeno fino alla release 14.1), ma solo la modalità asincrona. Il BFD è supportato per tutti i principali protocolli di routing IPv4/IPv6 (RIP, OSPF, IS-IS, BGP, PIM), per le route statiche IPv4/IPv6, per i tunnel MPLS-TE, ecc.(anche qui, per eventuali restrizioni è sempre comunque opportuno verificare la documentazione relativa alla versione JUNOS che si sta utilizzando).
Un aspetto interessante del JUNOS riguarda la gestione dei timer. Dopo la negoziazione iniziale, che segue le regole esposte nel Post precedente, i timer vengono gestiti in modo adattativo, ossia il JUNOS varia i timer in funzione delle condizioni del collegamento. Il meccanismo è assolutamente automatico e non ha bisogno di alcuna configurazione, e può essere solo disabilitato (ma è sconsigliato !). Ad esempio, quando vi sono più di tre passaggi up/down in 15 secondi della sessione BFD, i timer associati ai messaggi BFD HELLO aumentano automaticamente.
Le considerazioni fatte sugli indirizzi IP sorgente/destinazione dei messaggi BFD HELLO e le porte utilizzate nei router Cisco valgono anche per i router Juniper.
La configurazione del BFD avviene all'interno del protocollo Client con il comando seguente (di cui riportiamo le sole opzioni più importanti):
bfd-liveness-detection {
minimum-interval <valore-in-msec>;
minimum-receive-interval <valore-in-msec>;
multiplier <numero-intero>;
no-adaptation;
version (1 | automatic);
}
Il valore di Required Min RX Interval definito con il comando "minimum-receive-interval <valore-in-msec>", se non specificato esplicitamente viene preso identico al valore configurato nel comando "minimum-interval <valore-in-msec>". Il comando "no-adaptation" disabilita la gestione adattativa dei timer (ma, come detto sopra, è bene lasciarla attiva). Infine, il comando "version (1 | automatic)" consente di specificare la versione del BFD (tipicamente la 1), o lasciarne la determinazione automatica.
Passiamo ora alle prove di laboratorio. Nelle prove che ho effettuato mi sono avvalso di due router J2350 con il JUNOS 10.4R9.2.
Lo schema della rete di prova è analogo a quello utilizzato sopra per l'ambiente Cisco ed è riportato nella figura seguente:
Anche qui, poiché la configurazione del BFD associato al protocollo BGP è già stata vista nel precedente Post sulla convergenza del BGP (Parte I), ho attivato sul collegamento un'adiacenza OSPFv2, una OSPFv3 e ho configurato due route statiche (IPv4) per mettere in comunicazione le due interfacce Loopback 0 tra i due router. Per cercare di rendere la prova più interessante ho utilizzato valori dei timer BFD e del Detect Mult diversi. Queste sono le configurazioni rilevanti utilizzate:
[edit]
tt@P1# show routing-options
static {
route 192.168.1.2/32 {
next-hop 172.30.1.2;
bfd-liveness-detection {
minimum-interval 250;
multiplier 5;
local-address 172.30.1.1;
}
}
}
[edit]
tt@P1# show protocols
ospf {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 150;
minimum-receive-interval 100;
multiplier 3;
}
}
}
}
ospf3 {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 100;
minimum-receive-interval 200;
multiplier 5;
}
}
}
}
[edit]
tt@P2# show routing-options
static {
route 192.168.1.1/32 {
next-hop 172.30.1.1;
bfd-liveness-detection {
minimum-interval 250;
multiplier 3;
local-address 172.30.1.2;
}
}
}
tt@P2# show protocols
ospf {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 100;
minimum-receive-interval 200;
multiplier 5;
}
}
}
}
ospf3 {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 150;
minimum-receive-interval 100;
multiplier 3;
}
}
}
}
Vediamo ora il risultato della configurazione. Per questo il JUNOS ha il comando "show bfd session [detail | extensive]". (NOTA: per tutte le altre opzioni disponibili rimandiamo alla documentazione JUNOS).
Vediamo l'esecuzione del comando con l'opzione "extensive" dapprima sul router P1.
tt@P1> show bfd session extensive
Detect Transmit
Address State Interface Time Interval Multiplier
172.30.1.2 Up ge-0/0/0.0 0.500 0.200 3
Client Static, TX interval 0.250, RX interval 0.250
Client OSPF realm ospf-v2 Area 0.0.0.0, TX interval 0.150, RX interval 0.100
Session up time 00:00:05, previous down time 00:00:01
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.150, min slow interval 1.000
Adaptive async TX interval 0.150, RX interval 0.100
Local min TX interval 0.150, minimum RX interval 0.100, multiplier 3
Remote min TX interval 0.100, min RX interval 0.200, multiplier 5
Local discriminator 1, remote discriminator 1
Echo mode disabled/inactive
Detect Transmit
Address State Interface Time Interval Multiplier
fe80::226:88ff:fefa:8a80 Up ge-0/0/0.0 0.600 0.100 5
Client OSPF realm ipv6-unicast Area 0.0.0.0, TX interval 0.100, RX interval 0.200
Session up time 00:00:05, previous down time 00:00:01
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.100, min slow interval 1.000
Adaptive async TX interval 0.100, RX interval 0.200
Local min TX interval 0.100, minimum RX interval 0.200, multiplier 5
Remote min TX interval 0.150, min RX interval 0.100, multiplier 3
Local discriminator 3, remote discriminator 3
Echo mode disabled/inactive
2 sessions, 3 clients
Cumulative transmit rate 15.0 pps, cumulative receive rate 15.0 pps
Dalla visualizzazione si vede che la sessione BFD IPv4 è regolarmente nello stato "up", che l'indirizzo del BFD peer è 172.30.1.2 (che P1 rileva dall'indirizzo IP sorgente dei messaggi BFD HELLO ricevuti), l'interfacia locale che riceve i messaggi BFD HELLO è la ge-0/0/0 e infine vi sono i timer negoziati (di cui darò conto a breve). Lo stesso dicasi per la sessione BFD IPv6, dove però l'indirizzo del BFD peer è l'indirizzo IPv6 link-local fe80::2a8a:1cff:fe46:5940.
Altre informazioni che è possibile dedurre dalla visualizzazione sono che la sessione BFD IPv4 ha due protocolli Client, la route statica e OSPFv2:
Client Static, TX interval 0.250, RX interval 0.250
Client OSPF realm ospf-v2 Area 0.0.0.0, TX interval 0.150, RX interval 0.100
e che la versione di protocollo utilizzata è la 1.
Remote state Up, version 1
La sessione BFD IPv6 ha invece un solo protocollo Client, OSPFv3:
Client OSPF realm ipv6-unicast Area 0.0.0.0, TX interval 0.100, RX interval 0.200
Lo stesso comando eseguito sul router P2 da i seguenti risultati:
tt@P2> show bfd session extensive
Detect Transmit
Address State Interface Time Interval Multiplier
172.30.1.1 Up ge-0/0/0.0 0.600 0.100 5
Client Static, TX interval 0.250, RX interval 0.250
Client OSPF realm ospf-v2 Area 0.0.0.0, TX interval 0.100, RX interval 0.200
Session up time 00:04:28, previous down time 00:00:00
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.100, min slow interval 1.000
Adaptive async TX interval 0.100, RX interval 0.200
Local min TX interval 0.100, minimum RX interval 0.200, multiplier 5
Remote min TX interval 0.150, min RX interval 0.100, multiplier 3
Local discriminator 1, remote discriminator 1
Echo mode disabled/inactive
Detect Transmit
Address State Interface Time Interval Multiplier
fe80::2a8a:1cff:fe46:5940 Up ge-0/0/0.0 0.500 0.200 3
Client OSPF realm ipv6-unicast Area 0.0.0.0, TX interval 0.150, RX interval 0.100
Session up time 00:04:27, previous down time 00:00:01
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.150, min slow interval 1.000
Adaptive async TX interval 0.150, RX interval 0.100
Local min TX interval 0.150, minimum RX interval 0.100, multiplier 3
Remote min TX interval 0.100, min RX interval 0.200, multiplier 5
Local discriminator 3, remote discriminator 3
Echo mode disabled/inactive
2 sessions, 3 clients
Cumulative transmit rate 15.0 pps, cumulative receive rate 15.0 pps
Vediamo ora come sono stati negoziati su P1 i timer per la sessione BFD IPv4 (le analoghe considerazioni su P2 sono lasciate come esercizio !).
Analogamente a quanto fatto per l'IOS XR, innanzitutto dobbiamo porci una domanda. Poiché la sessione BFD IPv4 è unica e ha due protocolli Client, che utilizzano timer e Detect Mult diversi, quali valori vengono comunicati al BFD peer con i messaggi BFD HELLO ? Bene, il JUNOS adotta un approccio secondo il quale vengono comunicati i timer più aggressivi. Ma come si determinano i timer più aggressivi ? Il JUNOS fa lo stesso conticino già visto per l'IOS XR: per ciascun protocollo Client determina il valore (Local min TX interval)*(Local Detect Mult). Il JUNOS prende quindi il valore minore e comunica al BFD peer i timer e Detect Mult relativi. Ad esempio, applicando su P1 questo metodo si ha:
Client OSPFv2 : (Local min TX interval)*(Local Detect Mult) = 150*3 = 450 ms
Client Route Statica : (Local min TX interval)*(Local Detect Mult) = 250*5 = 1250 ms
Poiché 450 < 1250, P1 comunica al BFD peer P2 i seguenti timer e Detect Mult:
Desired min TX interval = 150 ms
Required min RX interval = 100 ms
Detect Mult = 3
Ciò può essere verificato dal risultato del comando "show bfd session extensive" su P1 e P2:
Su P1 : Local min TX interval 0.150, minimum RX interval 0.100, multiplier 3
Su P2 : Remote min TX interval 0.150, min RX interval 0.100, multiplier 3
Lo stesso identico ragionamento eseguito su P2 porta a concludere che i timer e Detect Mult comunicati da P2 a P1 attraverso i messaggi BFD HELLO sono (i dettagli sono lasciati al lettore):
Desired min TX interval = 100 ms
Required min RX interval = 200 ms
Detect Mult = 5
Ciò può essere verificato dal risultato del comando "show bfd session extensive" su P1 e P2:
Su P1 : Remote min TX interval 0.100, min RX interval 0.200, multiplier 5
Su P2 : Local min TX interval 0.100, minimum RX interval 0.200, multiplier 5
Ora, la determinazione del periodo di trasmissione dei messaggi BFD HELLO (indicato nelle visualizzazioni sopra come "Transmit Interval") segue le regole già ampiamente esposte:
Su P1: Transmit Interval = max[Desired min TX interval locale, Required min RX interval remoto] = max[150,200] = 200 ms
Su P2: Transmit Interval = max[Desired min TX interval locale, Required min RX interval remoto] = max[100,100] = 100 ms
Anche la determinazione dell'Holdtime (indicato nelle visualizzazioni sopra come "Detect Time"), segue le regole già ampiamente esposte:
Su P1: Detect Time = Transmit Interval di P2 * Detect Mult di P2 = 100*5 = 500 ms = 0.500 sec
Su P2: Detect Time = Transmit Interval di P1 * Detect Mult di P1 = 200*3 = 600 ms = 0.600 sec
Per la sessione BFD IPv6 i timer sono di più facile determinazione poiché il protocollo Client è unico (OSPFv3). Il periodo negoziato dei messaggi BFD HELLO su P1 è 100 ms (= max[100, 100]) mentre su P2 è 200 ms (= max[150, 200]).
I valori di Holdtime sono quindi rispettivamente:
Su P1: 200*3 = 600 ms (= Trasmit Interval di P2 * Detec Mult di P2).
Su P2: 100*5 = 500 ms (= Trasmit Interval di P1 * Detec Mult di P1).
E qui concludo questo Post. Le cose da dire sarebbero ancora molte ma non vorrei essere troppo noioso. Magari in seguito tornerò su qualche altra applicazione del BFD, se ne varrà la pena.
CONCLUSIONI
Le implementazioni Cisco e Juniper del BFD, benché conformi alle RFC, utilizzano default diversi e di questo è necessario tener conto in caso di interlavoro tra piattaforme eterogenee.
L'implementazione Cisco è fortemente dipendente dal sistema operativo utilizzato, sia nello stile di configurazione che nei valori di default. Tra l'altro vi sono default diversi per il BFD IPv4 e quello IPv6.
L'implementazione Juniper, grazie al fatto che tutte le piattaforme Juniper sono basate sul JUNOS (a parte quelle che utilizzano il JUNOSe, ma sono una minoranza), è molto più omogenea.
Pubblicato in
ReissBlog
Etichettato sotto
Mercoledì, 15 Ottobre 2014 18:47
IL BFD : QUESTO SCONOSCIUTO - PARTE I
Come promesso nel Post precedente sul BFD, in questo vedremo come implementarlo in pratica. Come al solito darò solo le idee fondamentali, tralasciando molti dettagli per i quali potete consultare la documentazione ufficiale dei costruttori. Illustrerò le configurazioni più importanti nelle piattaforme Cisco e Juniper, ed esporrò i risultati di prove reali di laboratorio, con i router che abbiamo a disposizione. Le prove riguarderanno la sola versione single-hop, che è quella utilizzata nella quasi totalità delle applicazioni pratiche.
NOTA: mentre stavo terminando di scrivere questo Post, è comparso sul blog del mio amico Ivan Pepelnjak un Post dal titolo "MICRO-BFD: BFD OVER LAG (PORT CHANNEL)", che tratta dell'applicazione del BFD su collegamenti "bundle", meglio noti tra i cultori delle reti Switched Ethernet (tra i quali non c'è il sottoscritto !) come "Port Channel", o Etherchannel, o LAG (Link Aggregation Group). L'argomento è interessante ed è stato oggetto della RFC 7130 "Bidirectional Forwarding Detection (BFD) on Link Aggregation Group (LAG) Interfaces", del Febbraio 2014. Il (semplice) meccanismo utilizzato, noto come Micro-BFD è già implementato nel JUNOS a partire dalla versione 13.3, e nelle versioni più recenti dei sistemi operativi Cisco NX-OS e IOS-XR. Mi riprometto in seguito di affrontare l'argomento in un Post dedicato.
IMPLEMENTAZIONE CISCO (IOS E IOS XR)
L'implementazione Cisco differisce abbastanza sia nello stile di configurazione che nei default utilizzati, tra IOS e IOS XR. Non ho l'opportunità di fare delle prove con il NX-OS dei Nexus, ma da quel poco che ho visto le configurazioni sono simili a quelle dell'IOS. Stesso discorso vale per l'IOS XE.
Prima di illustrare le prove effettuate, alcune considerazioni generali. L'implementazione Cisco supporta il BFD per tutti i principali protocolli di routing IPv4/IPv6 (EIGRP, OSPF, IS-IS, BGP, PIM), per le route statiche IPv4/IPv6, per i tunnel MPLS-TE e per protocolli di High Availability come HSRP e VRRP (per eventuali restrizioni è sempre comunque opportuno verificare la documentazione relativa alla versione IOS/IOS XR che si sta utilizzando).
I messaggi BFD HELLO vengono inviati utilizzando come indirizzi IP sorgente e destinazione:
- Nel caso di sessioni BFD IPv4, rispettivamente l'indirizzo dell'interfaccia da dove vengono trasmessi i messaggi, e indirizzo IP destinazione l'estremo remoto comunicato da un protocollo Client.
- Nel caso di sessioni BFD IPv6, gli indirizzi link-local associati alle interfacce locale e remota (NOTA: per chi non fosse familiare con IPv6, gli indirizzi link-local hanno come ambito di propagazione un segmento di rete, come ad esempio un link punto-punto, e sono parte del prefisso IPv6 fe80::/10. Tipicamente assumono la forma fe80::/64).
I messaggi BFD ECO, nell'IOS vengono inviati con indirizzo IP sorgente l'indirizzo dell'interfaccia da dove vengono trasmessi i messaggi; nell'IOS XR viene utilizzato il router-id globale, se configurato, altrimenti lo stesso indirizzo utilizzato nell'IOS. Nell'IOS XR è anche possibile sceglierlo con il comando "echo ipv4 source <indirizzo-IP>", eseguito a livello di protocollo BFD o a livello di interfaccia all'interno della configurazione del protocollo BFD. Ad esempio, se si volesse utilizzare l'indirizzo IP sorgente 1.1.1.1 per tutte le sessioni BFD, la configurazione da eseguire è la seguente:
RP/0/RP0/CPU0:router(config)# bfd
RP/0/RP0/CPU0:router(config-bfd)# echo ipv4 source 1.1.1.1
Qualore si volesse utilizzare l'indirizzo 2.2.2.2, ad esempio per l'interfaccia "Gigabitethernet 0/2/0/0", la configurazione da eseguire è la seguente:
RP/0/RP0/CPU0:router(config)# bfd
RP/0/RP0/CPU0:router(config-bfd)# interface gigabitethernet 0/2/0/0
RP/0/RP0/CPU0:router(config-bfd-if)# echo ipv4 source 2.2.2.2
Conformemente alla RFC 5881, i messaggi BFD vengono inviati con TTL IP pari a 255. Questo consente di evitare lo spoofing dei messaggi BFD, utilizzando la funzionalità Generalized TTL Security Mechanism (GTSM), standardizzata nella RFC 5082 (NOTA: la funzionalità GTSM non è peculiare del BFD, ma è molto generale e utilizzata anche da altri protocolli, come ad esempio il BGP).
Infine, le porte UDP utilizzate:
- Nei messaggi BFD HELLO: porta sorgente 49152, porta destinazione 3784.
- Nei messaggi BFD ECO: porta sorgente e porta destinazione 3785.
Passiamo ora alle prove di laboratorio. Nelle prove che ho effettuato mi sono avvalso di un router Cisco 3825 con IOS 15.1(3)T e del nostro vecchio glorioso GSR 12k, con IOS XR 4.2.4. Lo schema della rete di prova è riportato nella figura seguente:
Poiché la configurazione del BFD associato al protocollo BGP è già stata vista nel precedente Post sulla convergenza del BGP (Parte I), ho attivato sul collegamento un'adiacenza OSPFv2, una OSPFv3 e ho configurato due route statiche (IPv4) per mettere in comunicazione le due interfacce Loopback 0 tra i due router. Per cercare di rendere la prova più interessante ho utilizzato valori dei timer BFD e del Detect Mult diversi. Così, facendo queste prove ho scoperto molte cose interessanti. Innanzitutto le configurazioni rilevanti:
hostname PE1-1
!
interface GigabitEthernet0/1
ip address 172.16.1.111 255.255.255.0
ip ospf 1 area 0
ip ospf bfd
ipv6 enable
ipv6 ospf bfd
ipv6 ospf 1 area 0
bfd interval 150 min_rx 100 multiplier 3
!
ip route static bfd GigabitEthernet0/1 172.16.1.113
ip route 192.168.0.13 255.255.255.255 GigabitEthernet0/1 172.16.1.113
hostname PE1-3
!
router static
address-family ipv4 unicast
192.168.0.11/32 172.16.1.111 bfd fast-detect minimum-interval 150 multiplier 3
!
!
router ospf 1
area 0
interface GigabitEthernet0/2/0/0
bfd minimum-interval 100
bfd fast-detect
bfd multiplier 5
!
!
!
router ospfv3 1
area 0
interface GigabitEthernet0/2/0/0
bfd multiplier 4
bfd fast-detect
bfd minimum-interval 150
!
!
!
Prima di vedere i risultati della prova, una considerazione sulle configurazioni. Nell'IOS, l'abilitazione del BFD richiede due passi:
- La definizione all'interno della configurazione dell'interfaccia locale del collegamento da monitorare, dei due timer Desired Min TX Interval e Required Min RX Interval e del Detect Mult. I valori utilizzati nella configurazione di PE1-1 sono rispettivamente 150 ms, 100 ms e 3.
- Associare il BFD al protocollo. Nel caso dell'OSPFv2 questo può essere fatto in due modi: o con il comando "ip ospf bfd" a livello interfaccia. In alternativa, se tutte le interfacce abilitate OSPF utilizzano anche il BFD, si può eseguire il comando "bfd all-interfaces" a livello di processo OSPF:
PE1-1(config)#int GigabitEthernet0/1
PE1-1(config-if)#no ip ospf bfd
PE1-1(config)#router ospf 1
PE1-1(config-router)#bfd all-interfaces
Qualora si volesse disattivare il BFD su una particolare interfaccia (es. la GigabitEthernet0/2), è possibile farlo attraverso il seguentre comando:
PE1-1(config)#int GigabitEthernet0/2
PE1-1(config-if)#ip ospf bfd disable
Gli stessi identici comandi valgono per OSPFv3. E' sufficiente sostituire nei comandi "ip" con "ipv6".
Per contro nell'IOS XR, tutte le configurazioni del BFD vanno eseguite all'interno dei processi OSPFv2/v3. Inoltre, una cosa che salta subito all'occhio è che l'IOS XR non prevede la possibilità di differenziare i due timer Desired Min TX Interval e Required Min RX Interval, ma è possibile solo configurarli uguali, con il comando "bfd minimum-interval <valore-in-ms>". Il valore di Detect Mult potrebbe anche non essere configurato, nel qual caso l'IOS XR assegna il valore di default 3.
Un discorso a parte merita l'abilitazione del BFD sulle route statiche, sia IPv4 che IPv6, poiché non vi è come in OSPF, BGP, ecc. un modo automatico per comunicare al BFD l'indirizzo IP estremo remoto della sessione, non essendoci nessuna adiacenza o sessione stabilite in modo automatico. E' necessario quindi comunicare manualmente al BFD quale è l'indirizzo IP del BFD peer. Nell'IOS questo avviene con il comando a livello globale "ip route static bfd <interfaccia> <next-hop>". Si noti che nel comando è obbligatorio specificare l'interfaccia all'estremo locale del collegamento da monitorare. Inoltre è obbligatorio specificare l'interfaccia anche nella route statica, altrimenti l'associazione BFD route statica non avviene (NOTA: nella route statica l'indirizzo IP del Next-Hop non è necessario, ma io lo metto sempre comunque).
Questo comando crea un'associazione tra BFD e la route statica che ha come interfaccia Next-Hop e indirizzo IP Next-Hop quelli specificati nel comando. Ma cosa accade se nel router non è configurata alcuna route statica, magari perché un percorso verso la destinazione è stato appreso attraverso un altro protocollo ? Nessun problema, è sufficente aggiungere in coda al comando la parola chiave "unassociate" e il gioco è fatto. Questa parola chiave indica al router di completare comunque le procedure per l'apertura della sessione BFD anche in assenza di una route statica configurata.
Nell'IOS XR è sufficiente specificare timer e Detect Mult dopo il Next-Hop, come mostrato nella configurazione sopra. Non ho trovato tra la documentazione un concetto simile alla parola chiave "unassociate".
Vediamo ora il risultato della configurazione. Per questo l'IOS ha il comando "show bfd neighbors [detail]" e l'IOS XR l'analogo comando "show bfd all session [detail]". (NOTA: per tutte le altre opzioni disponibili rimandiamo alla documentazione Cisco).
Vediamo l'esecuzione di entrambi i comandi con la parola chiave "detail" su entrambi i router.
PE1-1# show bfd neighbors detail
NeighAddr LD/RD RH/RS State Int
172.16.1.113 2/-2146959355 Up Up Gi0/1
Session state is UP and using echo function with 150 ms interval.
OurAddr: 172.16.1.111
Local Diag: 0, Demand mode: 0, Poll bit: 0
MinTxInt: 1000000, MinRxInt: 1000000, Multiplier: 3
Received MinRxInt: 2000000, Received Multiplier: 3
Holddown (hits): 0(0), Hello (hits): 2000(102)
Rx Count: 98, Rx Interval (ms) min/max/avg: 460/1984/1817 last: 180 ms ago
Tx Count: 104, Tx Interval (ms) min/max/avg: 1/2000/1711 last: 220 ms ago
Elapsed time watermarks: 0 0 (last: 0)
Registered protocols: IPv4 Static OSPF
Uptime: 00:02:54
Last packet: Version: 1 - Diagnostic: 0
State bit: Up - Demand bit: 0
Poll bit: 0 - Final bit: 0
Multiplier: 3 - Length: 24
My Discr.: -2146959355 - Your Discr.: 2
Min tx interval: 2000000 - Min rx interval: 2000000
Min Echo interval: 1000
NeighAddr LD/RD RH/RS State Int
FE80::204:DEFF:FE51:CC70 1/-2146959358 Up Up Gi0/1
Session state is UP and not using echo function.
OurAddr: FE80::FEFB:FBFF:FE35:DE71
Local Diag: 0, Demand mode: 0, Poll bit: 0
MinTxInt: 150000, MinRxInt: 100000, Multiplier: 3
Received MinRxInt: 250000, Received Multiplier: 4
Holddown (hits): 788(0), Hello (hits): 250(847)
Rx Count: 814, Rx Interval (ms) min/max/avg: 36/272/230 last: 212 ms ago
Tx Count: 846, Tx Interval (ms) min/max/avg: 192/252/221 last: 204 ms ago
Elapsed time watermarks: 0 0 (last: 0)
Registered protocols: OSPFv3
Uptime: 00:03:07
Last packet: Version: 1 - Diagnostic: 0
State bit: Up - Demand bit: 0
Poll bit: 0 - Final bit: 0
Multiplier: 4 - Length: 24
My Discr.: -2146959358 - Your Discr.: 1
Min tx interval: 250000 - Min rx interval: 250000
Min Echo interval: 0
RP/0/0/CPU0:PE1-3#show bfd all session detail
Mon Oct 20 18:15:21.316 UTC
IPv4:
-----
I/f: GigabitEthernet0/2/0/0, Location: 0/2/CPU0
Dest: 172.16.1.111
Src: 172.16.1.113
State: UP for 0d:0h:4m:3s, number of times UP: 1
Session type: PR/V4/SH
Received parameters:
Version: 1, desired tx interval: 1 s, required rx interval: 1 s
Required echo rx interval: 100 ms, multiplier: 3, diag: None
My discr: 2, your discr: 2148007941, state UP, D/F/P/C/A: 0/0/0/0/0
Transmitted parameters:
Version: 1, desired tx interval: 2 s, required rx interval: 2 s
Required echo rx interval: 1 ms, multiplier: 3, diag: None
My discr: 2148007941, your discr: 2, state UP, D/F/P/C/A: 0/0/0/1/0
Timer Values:
Local negotiated async tx interval: 2 s
Remote negotiated async tx interval: 2 s
Desired echo tx interval: 150 ms, local negotiated echo tx interval: 150 ms
Echo detection time: 450 ms(150 ms*3), async detection time: 6 s(2 s*3)
Local Stats:
Intervals between async packets:
Tx: Number of intervals=100, min=1665 ms, max=1991 ms, avg=1832 ms
Last packet transmitted 1573 ms ago
Rx: Number of intervals=100, min=1510 ms, max=1992 ms, avg=1748 ms
Last packet received 691 ms ago
Intervals between echo packets:
Tx: Number of intervals=50, min=7701 ms, max=7701 ms, avg=7701 ms
Last packet transmitted 69 ms ago
Rx: Number of intervals=50, min=7700 ms, max=7702 ms, avg=7700 ms
Last packet received 68 ms ago
Latency of echo packets (time between tx and rx):
Number of packets: 100, min=0 us, max=2 ms, avg=530 us
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ipv4_static 150 ms 3 2 s 3
ospf-1 100 ms 5 2 s 5
IPv6:
-----
I/f: GigabitEthernet0/2/0/0, Location: 0/2/CPU0
Dest: fe80::fefb:fbff:fe35:de71
Src: fe80::204:deff:fe51:cc70
State: UP for 0d:0h:4m:16s, number of times UP: 1
Session type: PR/V6/SH
Received parameters:
Version: 1, desired tx interval: 150 ms, required rx interval: 100 ms
Required echo rx interval: 0 us, multiplier: 3, diag: None
My discr: 1, your discr: 2148007938, state UP, D/F/P/C/A: 0/0/0/0/0
Transmitted parameters:
Version: 1, desired tx interval: 250 ms, required rx interval: 250 ms
Required echo rx interval: 0 us, multiplier: 4, diag: None
My discr: 2148007938, your discr: 1, state UP, D/F/P/C/A: 0/0/0/1/0
Timer Values:
Local negotiated async tx interval: 250 ms
Remote negotiated async tx interval: 250 ms
Desired echo tx interval: 0 s, local negotiated echo tx interval: 0 s
Echo detection time: 0 s(0 s*4), async detection time: 750 ms(250 ms*3)
Local Stats:
Intervals between async packets:
Tx: Number of intervals=100, min=211 ms, max=251 ms, avg=228 ms
Last packet transmitted 7 ms ago
Rx: Number of intervals=100, min=191 ms, max=252 ms, avg=221 ms
Last packet received 135 ms ago
Intervals between echo packets:
Tx: Number of intervals=0, min=0 s, max=0 s, avg=0 s
Last packet transmitted 0 s ago
Rx: Number of intervals=0, min=0 s, max=0 s, avg=0 s
Last packet received 0 s ago
Latency of echo packets (time between tx and rx):
Number of packets: 0, min=0 us, max=0 us, avg=0 us
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ospfv3-1 150 ms 4 250 ms 4
Label:
------
------
Sulla base della configurazione effettuata, i due router stabiliscono due sessioni BFD, una per IPv4 (protocolli Client OSPFv2 e Route Statica) e una per IPv6 (protocollo Client OSPFv3).
Vediamo dapprima le caratteristiche della sessione BFD per IPv4. Prima considerazione: l'IOS e IOS XR, per la sessione BFD IPv4, utilizzano di default la funzione eco. Ciò si evince ad esempio dal comando "show bfd neighbors detail" sul router PE1-1, dove alla terza riga si legge: "Session state is UP and using echo function with 150 ms interval.". Il periodo dei messaggi BFD ECO (= 150 ms) coincide con il valore di configurazione "bfd interval <valore-in-ms> ...", definito a livello interfaccia. L'Holdtime (non riportato nella visualizzazione IOS) è pari 150*3 = 450 ms, dove 3 è il valore di Detect Mult configurato nel comando "bfd ... multiplier <valore-Detect-Mult>".
La funzione eco può essere disabilitata sia per l'IOS, con il comando a livello interfaccia "no bfd echo", che per l'IOS XR con il comando "echo disable" all'interno della configurazione del protocollo BFD:
RP/0/0/CPU0:PE1-3#(config)# bfd
RP/0/0/CPU0:PE1-3#(config-bfd)# echo disable
Seconda considerazione: l'IOS e IOS XR utilizzano valori di default diversi per il periodo di trasmissione dei messaggi BFD HELLO (che, ricordiamo, vengono scambiati comunque, ma molto più lentamente). L'IOS utilizza il valore di default 1 sec, l'IOS XR il valore 2 sec. Questo si evince dalla sesta e settima riga del comando "show bfd neighbors detail" sul router PE1-1:
MinTxInt: 1000000, MinRxInt: 1000000, Multiplier: 3
Received MinRxInt: 2000000, Received Multiplier: 3
dove MinTxInt è il valore del Desired Min TX Interval (= 1000000 microsec = 1 sec), MinRxInt è il valore del Required Min RX Interval (= 1000000 microsec = 1 sec). Il valore di Detec Mult è pari a 3 (valore impostato su base configurazione). Il valore negoziato di periodo dei messaggi BFD HELLO è 2 sec (il valore massimo tra i due). Nell'IOS il valore del periodo dei messaggi BFD HELLO può essere variato con il comando globale "bfd slow timers <valore>". Non ho trovato un comando analogo nell'IOS XR.
Il comando IOS XR "show bfd all session detail" mette in evidenza sia i timer ricevuti che quelli inviati e i valori del periodo dei messaggi BFD HELLO negoziati sia locale che remoto.
Il comando IOS XR "show bfd all session detail" mette in evidenza sia i timer ricevuti che quelli inviati e i valori del periodo dei messaggi BFD HELLO negoziati sia locale che remoto.
Received parameters:
Version: 1, desired tx interval: 1 s, required rx interval: 1 s
Required echo rx interval: 100 ms, multiplier: 3, diag: None
My discr: 3, your discr: 2148007941, state UP, D/F/P/C/A: 0/0/0/0/0
Transmitted parameters:
Version: 1, desired tx interval: 2 s, required rx interval: 2 s
Required echo rx interval: 1 ms, multiplier: 3, diag: None
My discr: 2148007941, your discr: 3, state UP, D/F/P/C/A: 0/0/0/1/0
Timer Values:
Local negotiated async tx interval: 2 s
Remote negotiated async tx interval: 2 s
Si noti che nei parametri ricevuti e inviati sono specificati tutti i campi dei messaggi BFD HELLO, incluso lo stato della sessione BFD (= UP) e le varie flag presenti (D/F/P/C/A). E' interessante il valore della flag C, posto a 1 dal GSR12k e a 0 dal 3825. Questo indica che il GSR 12k elabora i messaggi BFD a livello di linecard, mentre il 3825 li elabora a livello di CPU.
Vediamo infine come viene determinato il valore del periodo dei messaggi BFD ECO. Abbiamo già visto quello su PE1-1, pari a 150 ms.
Prima di vedere come viene determinato su PE1-3, dobbiamo innanzitutto porci una domanda. Poiché la sessione BFD IPv4 è unica e ha due protocolli Client (OSPFv2 e route statica), che utilizzano timer e Detect Mult diversi, quali valori vengono utilizzati per determinare il periodo dei messaggi BFD ECO ? Si noti che questo problema per l'IOS non si pone poiché tutti i protocolli Client che utilizzano la stessa interfaccia utilizzano gli stessi timer e Detect Mult. Bene, l'IOS XR adotta un approccio secondo il quale vengono utilizzati i timer più aggressivi. La frase è un po' sibillina, ma questo è quanto riporta la documentazione Cisco dell'IOS XR versione 4.3: "When multiple applications share the same BFD session, the application with the most aggressive timer wins locally".
Ho fatto molte prove per capire il senso di questa affermazione, e quello che ho dedotto è l'IOS XR fa un conticino molto semplice: per ciascun protocollo Client determina il valore (Local min TX interval)*(Local Detect Mult). L'IOS XR prende quindi il valore minore e utilizza per la determinazione del valore del periodo dei messaggi BFD ECO e il calcolo dell'Holdtime i timer e Detect Mult relativi. Ad esempio, applicando su PE1-3 questo metodo si ha:
- Client Route Statica : (Local min TX interval)*(Local Detect Mult) = 150*3 = 450 ms
- Client OSPFv2 : (Local min TX interval)*(Local Detect Mult) = 100*5 = 500 ms
Poiché 450 < 500, PE1-3 utilizza un periodo di 150 ms per il periodo dei messaggi BFD ECO e di 450 ms per l'Holdtime. Ciò può essere verificato dalla visualizzazione riportata sopra (NOTA: l'Holdtime dei messaggi BFD HELLO è invece 2*3 = 6 sec):
Desired echo tx interval: 150 ms, local negotiated echo tx interval: 150 ms
Echo detection time: 450 ms(150 ms*3), async detection time: 6 s(2 s*3)
Al di la di questa disquisizione, ritengo opportuno utilizzare per tutti i protocolli Client gli stessi timer e Detect Mult, lasciando l'utilizzo di valori diversi solo a casi molto particolari.
Infine, l'ultima parte della visualizzazione del comando "show bfd all session detail" su PE1-3 mostra i protocolli Client della sessione BFD per IPv4: OSPFv2 e la route statica IPv4.
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ipv4_static 150 ms 3 2 s 3
ospf-1 100 ms 5 2 s 5
La stessa informazione sul router PE1-1 si ha nella riga "Registered protocols: IPv4 Static OSPF".
Mi sono divertito ad un certo punto ad abilitare la funzionalità di sicurezza unicast RPF sull'interfaccia Gi0/1 del router PE1-1, con il comando:
PE1-1(config)#interface GigabitEthernet0/1
PE1-1(config-if)#ip verify unicast source reachable-via rx
Ecco quello che è successo:
PE1-1(config-if)#
*Oct 16 10:22:35.407: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from FULL to DOWN, Neighbor Down: BFD node down
*Oct 16 10:22:39.459: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from LOADING to FULL, Loading Done
PE1-1(config-if)#
*Oct 16 10:22:42.499: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from FULL to DOWN, Neighbor Down: BFD node down
*Oct 16 10:22:48.987: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from LOADING to FULL, Loading Done
*Oct 16 10:22:55.835: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from FULL to DOWN, Neighbor Down: BFD node down
*Oct 16 10:22:58.159: %OSPF-5-ADJCHG: Process 1, Nbr 192.168.0.13 on GigabitEthernet0/1 from LOADING to FULL, Loading Done
ossia un continuo up/down dell'adiacenza OSPF e della sessione BFD. Questo accade perché, come detto nel Post precedente sul BFD, la funzione eco è incompatibile con la funzionalità uRPF.
Vediamo ora le caratteristiche della sessione BFD per IPv6. La prima cosa da notare è che IOS e IOS XR per le sessioni BFD IPv6 non utilizzano la funzione eco, ma la semplice modalità asincrona. Si noti che i messaggi BFD HELLO utilizzano come indirizzi IPv6 sorgente e destinazione degli indirizzi link-local:
IPv6:
-----
I/f: GigabitEthernet0/2/0/0, Location: 0/2/CPU0
Dest: fe80::fefb:fbff:fe35:de71
Src: fe80::204:deff:fe51:cc70
Vediamo ora, dal punto di vista di PE1-3, la negoziazione dei timer e la determinazione dell'Holdtime (= detection time). I risultati si evincono dalla visualizzazione del comando "show bfd all session detail":
Timer Values:
Local negotiated async tx interval: 250 ms
Remote negotiated async tx interval: 250 ms
Desired echo tx interval: 0 s, local negotiated echo tx interval: 0 s
Echo detection time: 0 s(0 s*4), async detection time: 750 ms(250 ms*3)
Anche qui, ho scoperto una curiosità. Mi aspettavo infatti, su PE1-3, un valore del periodo negoziato dei messaggi BFD HELLO di 150 ms, ossia il valore massimo tra il Desired Min TX Interval (= 150 ms) locale e Required Min RX Interval ricevuto da PE1-1 (= 100 ms). Invece mi sono ritrovato come valore negoziato 250 ms. Dopo un po' di prove ho scoperto che l'IOS XR, per valori di "minimum interval" configurati, inferiori a 250 ms, aggiusta comunque il valore a 250 ms. Questo si evince dalla parte finale della visualizzazione del comando "show bfd all session detail":
Session owner information:
Desired Adjusted
Client Interval Multiplier Interval Multiplier
-------------------- --------------------- ---------------------
ospfv3-1 150 ms 4 250 ms 4
Il valore di Holdtime è quindi 250*3 = 750 ms (ricordiamo che nel calcolo viene utilizzato il valore di Detect Mult ricevuto, pari a 3, vedi Post precedente). Per contro, lasciamo al lettore verificare che il valore del periodo dei messaggi BFD HELLO e di Holdtime determinati da PE1-1 sono rispettivamente 250 ms e 250*4 = 1000 ms.
Questo completa le mie considerazioni sull'implementazione Cisco del BFD. Vi sarebbero molte altre cose da dire, ma il Post diventerebbe chilometrico. Quanto riportato sopra si concentra sugli aspetti più importanti e più utili per le applicazioni pratiche. Argomenti come l'autenticazione dei messaggi, il BFD damping (molto simile al BGP Route Flap damping), il BFD nei collegamenti bundle, ecc. sono stati volutamente tralasciati. Eventualmente ci tornerò in futuro con qualche altro Post. Chi invece vorrà cimentarsi con l'esame di certificazione CCIE dovrà necessariamente approfondire tutti gli aspetti di configurazione (nell'IOS o IOS XR, in funzione del tipo di certificazione).
IMPLEMENTAZIONE JUNIPER
Fortunatamente tutte le piattaforme Juniper sono basate sullo stesso sistema operativo, il JUNOS, e quindi questo renderà la trattazione più breve (NOTA: non considererò piattaforme basate sul JUNOSe, che comunque ha una CLI simile a quella Cisco).
La prima considerazione da fare circa l'implementazione BFD del JUNOS, è che non supporta la funzione eco (almeno fino alla release 14.1), ma solo la modalità asincrona. Il BFD è supportato per tutti i principali protocolli di routing IPv4/IPv6 (RIP, OSPF, IS-IS, BGP, PIM), per le route statiche IPv4/IPv6, per i tunnel MPLS-TE, ecc.(anche qui, per eventuali restrizioni è sempre comunque opportuno verificare la documentazione relativa alla versione JUNOS che si sta utilizzando).
Un aspetto interessante del JUNOS riguarda la gestione dei timer. Dopo la negoziazione iniziale, che segue le regole esposte nel Post precedente, i timer vengono gestiti in modo adattativo, ossia il JUNOS varia i timer in funzione delle condizioni del collegamento. Il meccanismo è assolutamente automatico e non ha bisogno di alcuna configurazione, e può essere solo disabilitato (ma è sconsigliato !). Ad esempio, quando vi sono più di tre passaggi up/down in 15 secondi della sessione BFD, i timer associati ai messaggi BFD HELLO aumentano automaticamente.
Le considerazioni fatte sugli indirizzi IP sorgente/destinazione dei messaggi BFD HELLO e le porte utilizzate nei router Cisco valgono anche per i router Juniper.
La configurazione del BFD avviene all'interno del protocollo Client con il comando seguente (di cui riportiamo le sole opzioni più importanti):
bfd-liveness-detection {
minimum-interval <valore-in-msec>;
minimum-receive-interval <valore-in-msec>;
multiplier <numero-intero>;
no-adaptation;
version (1 | automatic);
}
Il valore di Required Min RX Interval definito con il comando "minimum-receive-interval <valore-in-msec>", se non specificato esplicitamente viene preso identico al valore configurato nel comando "minimum-interval <valore-in-msec>". Il comando "no-adaptation" disabilita la gestione adattativa dei timer (ma, come detto sopra, è bene lasciarla attiva). Infine, il comando "version (1 | automatic)" consente di specificare la versione del BFD (tipicamente la 1), o lasciarne la determinazione automatica.
Passiamo ora alle prove di laboratorio. Nelle prove che ho effettuato mi sono avvalso di due router J2350 con il JUNOS 10.4R9.2.
Lo schema della rete di prova è analogo a quello utilizzato sopra per l'ambiente Cisco ed è riportato nella figura seguente:
Anche qui, poiché la configurazione del BFD associato al protocollo BGP è già stata vista nel precedente Post sulla convergenza del BGP (Parte I), ho attivato sul collegamento un'adiacenza OSPFv2, una OSPFv3 e ho configurato due route statiche (IPv4) per mettere in comunicazione le due interfacce Loopback 0 tra i due router. Per cercare di rendere la prova più interessante ho utilizzato valori dei timer BFD e del Detect Mult diversi. Queste sono le configurazioni rilevanti utilizzate:
[edit]
tt@P1# show routing-options
static {
route 192.168.1.2/32 {
next-hop 172.30.1.2;
bfd-liveness-detection {
minimum-interval 250;
multiplier 5;
local-address 172.30.1.1;
}
}
}
[edit]
tt@P1# show protocols
ospf {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 150;
minimum-receive-interval 100;
multiplier 3;
}
}
}
}
ospf3 {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 100;
minimum-receive-interval 200;
multiplier 5;
}
}
}
}
[edit]
tt@P2# show routing-options
static {
route 192.168.1.1/32 {
next-hop 172.30.1.1;
bfd-liveness-detection {
minimum-interval 250;
multiplier 3;
local-address 172.30.1.2;
}
}
}
tt@P2# show protocols
ospf {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 100;
minimum-receive-interval 200;
multiplier 5;
}
}
}
}
ospf3 {
area 0.0.0.0 {
interface ge-0/0/0.0 {
bfd-liveness-detection {
minimum-interval 150;
minimum-receive-interval 100;
multiplier 3;
}
}
}
}
Vediamo ora il risultato della configurazione. Per questo il JUNOS ha il comando "show bfd session [detail | extensive]". (NOTA: per tutte le altre opzioni disponibili rimandiamo alla documentazione JUNOS).
Vediamo l'esecuzione del comando con l'opzione "extensive" dapprima sul router P1.
tt@P1> show bfd session extensive
Detect Transmit
Address State Interface Time Interval Multiplier
172.30.1.2 Up ge-0/0/0.0 0.500 0.200 3
Client Static, TX interval 0.250, RX interval 0.250
Client OSPF realm ospf-v2 Area 0.0.0.0, TX interval 0.150, RX interval 0.100
Session up time 00:00:05, previous down time 00:00:01
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.150, min slow interval 1.000
Adaptive async TX interval 0.150, RX interval 0.100
Local min TX interval 0.150, minimum RX interval 0.100, multiplier 3
Remote min TX interval 0.100, min RX interval 0.200, multiplier 5
Local discriminator 1, remote discriminator 1
Echo mode disabled/inactive
Detect Transmit
Address State Interface Time Interval Multiplier
fe80::226:88ff:fefa:8a80 Up ge-0/0/0.0 0.600 0.100 5
Client OSPF realm ipv6-unicast Area 0.0.0.0, TX interval 0.100, RX interval 0.200
Session up time 00:00:05, previous down time 00:00:01
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.100, min slow interval 1.000
Adaptive async TX interval 0.100, RX interval 0.200
Local min TX interval 0.100, minimum RX interval 0.200, multiplier 5
Remote min TX interval 0.150, min RX interval 0.100, multiplier 3
Local discriminator 3, remote discriminator 3
Echo mode disabled/inactive
2 sessions, 3 clients
Cumulative transmit rate 15.0 pps, cumulative receive rate 15.0 pps
Dalla visualizzazione si vede che la sessione BFD IPv4 è regolarmente nello stato "up", che l'indirizzo del BFD peer è 172.30.1.2 (che P1 rileva dall'indirizzo IP sorgente dei messaggi BFD HELLO ricevuti), l'interfacia locale che riceve i messaggi BFD HELLO è la ge-0/0/0 e infine vi sono i timer negoziati (di cui darò conto a breve). Lo stesso dicasi per la sessione BFD IPv6, dove però l'indirizzo del BFD peer è l'indirizzo IPv6 link-local fe80::2a8a:1cff:fe46:5940.
Altre informazioni che è possibile dedurre dalla visualizzazione sono che la sessione BFD IPv4 ha due protocolli Client, la route statica e OSPFv2:
Client Static, TX interval 0.250, RX interval 0.250
Client OSPF realm ospf-v2 Area 0.0.0.0, TX interval 0.150, RX interval 0.100
e che la versione di protocollo utilizzata è la 1.
Remote state Up, version 1
La sessione BFD IPv6 ha invece un solo protocollo Client, OSPFv3:
Client OSPF realm ipv6-unicast Area 0.0.0.0, TX interval 0.100, RX interval 0.200
Lo stesso comando eseguito sul router P2 da i seguenti risultati:
tt@P2> show bfd session extensive
Detect Transmit
Address State Interface Time Interval Multiplier
172.30.1.1 Up ge-0/0/0.0 0.600 0.100 5
Client Static, TX interval 0.250, RX interval 0.250
Client OSPF realm ospf-v2 Area 0.0.0.0, TX interval 0.100, RX interval 0.200
Session up time 00:04:28, previous down time 00:00:00
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.100, min slow interval 1.000
Adaptive async TX interval 0.100, RX interval 0.200
Local min TX interval 0.100, minimum RX interval 0.200, multiplier 5
Remote min TX interval 0.150, min RX interval 0.100, multiplier 3
Local discriminator 1, remote discriminator 1
Echo mode disabled/inactive
Detect Transmit
Address State Interface Time Interval Multiplier
fe80::2a8a:1cff:fe46:5940 Up ge-0/0/0.0 0.500 0.200 3
Client OSPF realm ipv6-unicast Area 0.0.0.0, TX interval 0.150, RX interval 0.100
Session up time 00:04:27, previous down time 00:00:01
Local diagnostic CtlExpire, remote diagnostic CtlExpire
Remote state Up, version 1
Min async interval 0.150, min slow interval 1.000
Adaptive async TX interval 0.150, RX interval 0.100
Local min TX interval 0.150, minimum RX interval 0.100, multiplier 3
Remote min TX interval 0.100, min RX interval 0.200, multiplier 5
Local discriminator 3, remote discriminator 3
Echo mode disabled/inactive
2 sessions, 3 clients
Cumulative transmit rate 15.0 pps, cumulative receive rate 15.0 pps
Vediamo ora come sono stati negoziati su P1 i timer per la sessione BFD IPv4 (le analoghe considerazioni su P2 sono lasciate come esercizio !).
Analogamente a quanto fatto per l'IOS XR, innanzitutto dobbiamo porci una domanda. Poiché la sessione BFD IPv4 è unica e ha due protocolli Client, che utilizzano timer e Detect Mult diversi, quali valori vengono comunicati al BFD peer con i messaggi BFD HELLO ? Bene, il JUNOS adotta un approccio secondo il quale vengono comunicati i timer più aggressivi. Ma come si determinano i timer più aggressivi ? Il JUNOS fa lo stesso conticino già visto per l'IOS XR: per ciascun protocollo Client determina il valore (Local min TX interval)*(Local Detect Mult). Il JUNOS prende quindi il valore minore e comunica al BFD peer i timer e Detect Mult relativi. Ad esempio, applicando su P1 questo metodo si ha:
Client OSPFv2 : (Local min TX interval)*(Local Detect Mult) = 150*3 = 450 ms
Client Route Statica : (Local min TX interval)*(Local Detect Mult) = 250*5 = 1250 ms
Poiché 450 < 1250, P1 comunica al BFD peer P2 i seguenti timer e Detect Mult:
Desired min TX interval = 150 ms
Required min RX interval = 100 ms
Detect Mult = 3
Ciò può essere verificato dal risultato del comando "show bfd session extensive" su P1 e P2:
Su P1 : Local min TX interval 0.150, minimum RX interval 0.100, multiplier 3
Su P2 : Remote min TX interval 0.150, min RX interval 0.100, multiplier 3
Lo stesso identico ragionamento eseguito su P2 porta a concludere che i timer e Detect Mult comunicati da P2 a P1 attraverso i messaggi BFD HELLO sono (i dettagli sono lasciati al lettore):
Desired min TX interval = 100 ms
Required min RX interval = 200 ms
Detect Mult = 5
Ciò può essere verificato dal risultato del comando "show bfd session extensive" su P1 e P2:
Su P1 : Remote min TX interval 0.100, min RX interval 0.200, multiplier 5
Su P2 : Local min TX interval 0.100, minimum RX interval 0.200, multiplier 5
Ora, la determinazione del periodo di trasmissione dei messaggi BFD HELLO (indicato nelle visualizzazioni sopra come "Transmit Interval") segue le regole già ampiamente esposte:
Su P1: Transmit Interval = max[Desired min TX interval locale, Required min RX interval remoto] = max[150,200] = 200 ms
Su P2: Transmit Interval = max[Desired min TX interval locale, Required min RX interval remoto] = max[100,100] = 100 ms
Anche la determinazione dell'Holdtime (indicato nelle visualizzazioni sopra come "Detect Time"), segue le regole già ampiamente esposte:
Su P1: Detect Time = Transmit Interval di P2 * Detect Mult di P2 = 100*5 = 500 ms = 0.500 sec
Su P2: Detect Time = Transmit Interval di P1 * Detect Mult di P1 = 200*3 = 600 ms = 0.600 sec
Per la sessione BFD IPv6 i timer sono di più facile determinazione poiché il protocollo Client è unico (OSPFv3). Il periodo negoziato dei messaggi BFD HELLO su P1 è 100 ms (= max[100, 100]) mentre su P2 è 200 ms (= max[150, 200]).
I valori di Holdtime sono quindi rispettivamente:
Su P1: 200*3 = 600 ms (= Trasmit Interval di P2 * Detec Mult di P2).
Su P2: 100*5 = 500 ms (= Trasmit Interval di P1 * Detec Mult di P1).
E qui concludo questo Post. Le cose da dire sarebbero ancora molte ma non vorrei essere troppo noioso. Magari in seguito tornerò su qualche altra applicazione del BFD, se ne varrà la pena.
CONCLUSIONI
Le implementazioni Cisco e Juniper del BFD, benché conformi alle RFC, utilizzano default diversi e di questo è necessario tener conto in caso di interlavoro tra piattaforme eterogenee.
L'implementazione Cisco è fortemente dipendente dal sistema operativo utilizzato, sia nello stile di configurazione che nei valori di default. Tra l'altro vi sono default diversi per il BFD IPv4 e quello IPv6.
L'implementazione Juniper, grazie al fatto che tutte le piattaforme Juniper sono basate sul JUNOS (a parte quelle che utilizzano il JUNOSe, ma sono una minoranza), è molto più omogenea.
Pubblicato in
ReissBlog
Etichettato sotto
Giovedì, 09 Ottobre 2014 19:31
LIBRO "IS-IS:DALLA TEORIA ALLA PRATICA" : CAPP. 2 E 3
Questa settimana due nuovi capitoli del libro su IS-IS.
Nel Capitolo 2 vengono illustrati i concetti fondamentali del modello ISO/OSI. La ragione per cui
ho inserito questo capitolo è che il protocollo IS-IS è stato sviluppato in questo ambito, e si porta dietro
una terminologia mutuata proprio dal modello di riferimento ISO/OSI. Inoltre, serve per inquadrare
correttamente la funzione del protocollo.
Con il Capitolo 3 inizia il nostro viaggio all’interno del protocollo IS-IS, illustrando alcuni
concetti chiave come i Livelli di routing, i tipi di adiacenze, di IS e di LSBD, la partizione in aree e la
definizione di Backbone IS-IS. Inoltre, viene illustrato come IS-IS determina i percorsi ottimi e come sia
possibile risolvere alcune non ottimalità utilizzando il meccanismo del Route Leaking. Infine, verrà
svelato il mistero degli indirizzi OSI da assegnare agli IS, argomento psicologicamente ostico, ma
abbastanza elementare.
Buona lettura !!!
Coming up next ... un post sul BFD, questo sconosciuto.
{phocadownload view=file|id=8|text=LIbro IS-IS Cap. 2|target=b}
{phocadownload view=file|id=9|text=LIbro IS-IS Cap. 3|target=b}
{phocadownload view=file|id=8|text=LIbro IS-IS Cap. 2|target=b}
{phocadownload view=file|id=9|text=LIbro IS-IS Cap. 3|target=b}
Pubblicato in
ReissBlog
Etichettato sotto
Giovedì, 02 Ottobre 2014 17:19
LA (LENTA) CONVERGENZA DEL BGP: UN MITO DA SFATARE - PARTE I
Ho raccolto in un documento di più di 70 pagine il contenuto dei miei post precedenti sulla Convergenza del BGP. Ho inserito qualche dettaglio in più e, per completezza, una Appendice che tratta di aspetti già noti.
Può esservi utile per la vostra biblioteca tecnica.
Potete scaricare il documento a questo link.
Buona lettura !!!
Con questo mini-post, concludo il primo ciclo del blog. E' ora di prendersi una pausa. Nei mesi di Luglio e Agosto non pubblicherò ulteriore materiale, per cui auguro a tutti i lettori Buone Vacanze, e arrivederci a Settembre.
Pubblicato in
ReissBlog
Etichettato sotto
Il tuo IPv4: 216.73.217.33
Newsletter
