

MPLS è uno standard che mi ha intrigato sin dalla sua nascita (nel lontano 1997, anche se i primi standard ufficiali e le prime applicazioni sul campo si sono avute agli inizi del 2001). La ragione è che è un'idea molto semplice, già nota e utilizzata in altri standard (es. ATM, Frame Relay), ma che ha reso le reti IP molto più flessibili nel trasporto del traffico e nell'offerta dei servizi di rete.
Dopo tanti anni MPLS può essere considerato una realtà (molto spesso "amata", qualche volta "odiata") delle reti IP, utilizzato dalla quasi totalità dei grandi ISP (Internet Service Provider) e nelle grandi reti Enterprise. Chi conosce bene l'argomento sa però che MPLS ha bisogno di una "intelligenza" per funzionare, e questa nella quasi totalità dei servizi è offerta dal BGP e dalla incredibile flessibilità che questo offre. Tanto che si dovrebbe parlare più correttamente di servizi BGP/MPLS più che di servizi MPLS. Il BGP è la "mente", MPLS è il "braccio" operativo che trasporta il traffico. In altre parole, BGP gioca il ruolo chiave nel piano di controllo e MPLS nel piano dati.
Benché ormai consolidato, di tanto in tanto anche MPLS è soggetto a "restyling", che consentono di migliorare il suo funzionamento. In questo Post tratterò due nuovi standard, molto semplici, che consentono di migliorare i criteri con cui MPLS può essere utilizzato per una distribuzione più uniforme del traffico sulla rete, quando vi siano tra origine e destinazione dei LSP (Label Switched Path) MPLS, più percorsi (ottimi) "identici", ad esempio due o più percorsi IGP a costo minimo (tecnica nota come Load Balancing (da qui in poi abbreviata in LB) o anche ECMP, Equal-Cost Multi-Path).
Prima di parlare dei due nuovi standard, è bene però fare il "riassunto delle puntate precedenti", ossia ricordare come le attuali piattaforme effettuano il LB di pacchetti MPLS. In altre parole, forse più eleganti ma meno suggestive, come sia possibile con le attuali piattaforme, dividere il traffico di pacchetti MPLS tra una origine e destinazione, in due LSP differenti.
Ci sono due aspetti che caratterizzano il LB di pacchetti MPLS. Il primo riguarda i percorsi MPLS (LSP MPLS). Nel caso in cui questi siano determinati da un protocollo IGP (tipicamente nelle applicazioni pratiche OSPF o IS-IS, anche se in teoria è possibile utilizzare qualsiasi protocollo IGP), e le etichette MPLS associate ai percorsi IGP siano di conseguenza determinate dal protocollo LDP, il LB dei pacchetti MPLS è possibile solo in presenza di percorsi IGP multipli a minimo costo. Nei punti di diramazione dei percorsi, il traffico MPLS viene ripartito dai LSR (o Edge-LSR se un punto di diramazione coincide con l'origine del LSP) con qualche criterio su due o più Next-Hop IGP. Ad esempio, nella figura seguente, supponendo che tutte le interfacce abbiamo metrica identica (il valore è ininfluente), il router PE1, che è un Edge-LSR e P11, che è un LSR, sono dei punti di diramazione per il traffico. I pacchetti o trame L2 entranti, nella figura indicati con 1, 2 e 3, vengono quindi ripartiti con qualche criterio sui Next-Hop disponibili.

Quando invece i LSP MPLS sono costruiti attraverso il Traffic Engineering MPLS (LSP MPLS-TE), per effettuare una qualche forma di LB è necessario stabilire due o più LSP MPLS-TE tra lo stesso router origine e lo stesso router destinazione.
Il secondo aspetto è molto più importante ed è quello che ha dato origine ai due nuovi standard di cui parlerò in questo Post: con quali criteri i pacchetti MPLS vengono assegnati ai percorsi alternativi disponibili ? Ossia, quando un router ha a disposizione più Next-Hop per instradare un pacchetto MPLS, con quali criteri assegna il pacchetto a un determinato Next-Hop ? Questo è un aspetto che ha un impatto molto importante sulla qualità del servizio. Per vedere il perché, supponiamo per semplicità di avere due Next-Hop possibili. Il LSR che deve decidere come assegnare i pacchetti MPLS ai Next-Hop ha varie scelte a disposizione. Ad esempio, potrebbe assegnare i pacchetti sempre allo stesso Next-Hop. Ma questo, a parte il fatto che evita il LB "tout court", potrebbe portare alla congestione di un collegamento, quando l'altro disponibile è magari scarico. Una seconda alternativa è quella di effettuare un LB "per pacchetto", ossia inviare alternativamente un pacchetto verso un Next-Hop, e il successivo verso l'altro Next-Hop. Benché semplice, questo criterio, se da un lato consente di evitare il problema precedente e distribuire il traffico abbastanza equamente sui due collegamenti disponibili, ha però un grosso difetto: i pacchetti, che normalmente appartengono a un flusso di traffico ben definito (es. una conversazione VoIP, una connessione TCP Client-Server, ecc.), vengono consegnati a destinazione fuori sequenza, obbligando il protocollo di trasporto al riordino dei pacchetti. Inoltre, poiché i singoli pacchetti di un flusso possono seguire percorsi più o meno congestionati, aumentano ritardo e jitter. Agli inizi della storia, a causa della sua semplicità di implementazione, era comunque questa la strategia adottata dai maggiori costruttori.
L'ideale sarebbe di assegnare i pacchetti ai Next-Hop disponibili, mantenendo la sequenzialità all'interno dei singoli flussi di traffico. Ma qui ci si scontra con un problema chiave. MPLS nella sua intestazione, a volte chiamata shim header dove shim significa "snella", non ha un campo che gli consenta di dedurre a quale protocollo appartiene il pacchetto o trama L2 che sta trasportando (un pacchetto IPv4, IPv6, Apple-Talk, una trama Ethernet, PPP, ecc., chissa ?), e quindi non è in grado di determinare i pacchetti di uno stesso flusso, men che meno inferire alcunché sulla granularità del flusso.
A ben vedere, il problema sarebbe di banale soluzione nel caso in cui i LSP MPLS siano realizzati attraverso il Traffic Engineering MPLS. In questo caso infatti, il LSR origine dei LSP MPLS-TE, avendo a disposizione l'intero pacchetto o trama da trasportare nei LSP MPLS-TE disponibili, potrebbe guardare a particolari campi (di Livello2, 3 e/o 4) all'interno della trama o del pacchetto, individuare i singoli flussi con più o meno granularità, e assegnare i singoli flussi ai vari LSP MPLS-TE disponibili. Giusto per fare un esempio pratico, supponiamo che da un Edge-LSR origine vengano realizzati due LSP MPLS-TE verso la stessa destinazione. Come questi vengono realizzati, se staticamente o attraverso il Constraint-Based Routing con vincoli più o meno sofisticati (es. vincoli SRLG, classi amministrative, ecc.) è assolutamente indifferente. Supponiamo inoltre che sui due LSP MPLS-TE si debbano veicolare pacchetti IPv4. Per distribuire il traffico in modo "intelligente" sui due LSP MPLS-TE disponibili, l'Edge-LSR di ingresso potrebbe essere configurato con una sorta di Policy-Based Routing che funzioni in questo modo: se il pacchetto appartiene a un flusso X (individuato ad esempio guardando i soli indirizzi IP sorgente e destinazione) allora invia il pacchetto al primo LSP MPLS-TE; se il pacchetto appartiene a un flusso Y (sempre individuato guardando i soli indirizzi IP sorgente e destinazione), allora invia il pacchetto al secondo LSP MPLS-TE. Poiché i flussi con diverse coppie <IP sorgente; IP destinazione> sono in genere molti, la logica viene implementata attraverso un algoritmo di Hash, che (per semplificare) a fronte di una determinata coppia <IP sorgente; IP destinazione> determina un numero intero, nel nostro esempio 1 o 2; qualora il risultato fosse 1, il pacchetto verrebbe inviato al primo MPLS-TE; se, viceversa, il risultato fosse 2, il pacchetto verrebbe inviato al secondo MPLS-TE (NOTA: ribadisco che questa è solo una versione semplificata, ma esplicativa, del funzionamento dell'algoritmo di Hash).
Quando i LSP seguono invece i percorsi IGP e le etichette MPLS stabilite dal protocollo LDP, il problema è molto più sottile poiché, come detto sopra, i LSR di transito non conoscono esattamente cosa ci sia dietro un pacchetto MPLS, ma possono solo dedurlo con qualche trucco più o meno intelligente. Il problema è che questi trucchi, che sono per la maggior parte vendor-dependent, a volte non funzionano.
Prima di andare avanti, vediamo come i due maggiori costruttori di apparati, Cisco e Juniper, risolvono il problema.
LOAD BALANCING DI PACCHETTI MPLS NEI ROUTER CISCO
I router Cisco, in presenza di Next-Hop IGP multipli, effettuano di default il LB dei pacchetti MPLS. Ho fatto una prova sui nostri Lab, utilizzando OSPF come protocollo IGP, e abilitando LDP. Automaticamente, come noto, questo è sufficiente a stabilire LSP MPLS end-to-end tra due qualsiasi router. Consideriamo il caso di uno di questi LSP, originato in un router che ho chiamato PE11, e terminato su un router PE21, che ha indirizzo IP dell'interfaccia Loopback 0 pari a 192.168.1.21. Il percorso MPLS attraversa il LSR di transito CS11, che ha due percorsi OSPF verso il prefisso IP 192.168.1.21:
CS11# show ip route 192.168.1.21
Routing entry for 192.168.1.21/32
Known via "ospf 11", distance 110, metric 21, type intra area
Last update from 172.30.13.21 on Serial1/3, 00:08:33 ago
Routing Descriptor Blocks:
* 172.30.14.22, from 192.168.1.21, 00:08:33 ago, via Serial1/4
Route metric is 21, traffic share count is 1
172.30.13.21, from 192.168.1.21, 00:08:33 ago, via Serial1/3
Route metric is 21, traffic share count is 1
Il dettaglio della tabella di forwarding MPLS, per quanto riguarda la terminazione del LSP è il seguente:
CS11# show mpls forwarding-table 192.168.1.21 detail
Local Outgoing Prefix Bytes tag Outgoing Next Hop
tag tag or VC or Tunnel Id switched interface
25 27 192.168.1.21/32 0 Se1/4 point2point
MAC/Encaps=4/8, MRU=1500, Tag Stack{27}
0F008847 0001B000
No output feature configured
Per-destination load-sharing, slots: 0 2 4 6 8 10 12 14
23 192.168.1.21/32 0 Se1/3 point2point
MAC/Encaps=4/8, MRU=1500, Tag Stack{23}
0F008847 00017000
No output feature configured
Per-destination load-sharing, slots: 1 3 5 7 9 11 13 15
Come si può notare, i pacchetti MPLS che arrivano a CS11 con etichetta MPLS 25, vengono inviati o al Next-Hop "interfaccia Se1/4" (punto-punto !) con etichetta 27, o al Next-Hop "interfaccia Se1/3" con etichetta 23. Dalla visualizzazione si evince inoltre che CS11 utilizza di default, per assegnare i pacchetti MPLS ai Next-Hop, un algoritmo di tipo "per-flusso" (Per-destination load-sharing ...) (NOTA: l'IOS Cisco consente di abilitare comunque il LB per pacchetto con il comando a livello interfaccia "ip load-sharing per-packet", ma è sconsigliato).
I numeri che seguono la parola "slots" indicano i cosiddetti Hash Bucket, e sono determinati dall'algoritmo CEF attraverso un algoritmo di Hash. Gli Hash Bucket sono in totale 16 e vengono utilizzati nel seguente modo: se il risultato dell'algoritmo di Hash è un numero pari (0, 2, 4, ...) invia il pacchetto attraverso l'interfaccia Se1/4 con etichetta MPLS 27. Viceversa, se il risultato è un numero dispari, invia il pacchetto attraverso l'interfaccia Se1/3 con etichetta MPLS 23 (NOTA: il numero di Hash Bucket varia in funzione della piattaforma, e rappresenta il numero massimo di percorsi su cui è possibile fare LB).
Rimane il problema chiave: quali variabili utilizza in input l'algoritmo di Hash (spesso indicate in letteratura come keys) ? Cisco utilizza di default questa strategia (NOTA: questa strategia potrebbe variare leggermente in funzione della piattaforma, ma la sostanza non cambia):
- Se il pacchetto trasportato da MPLS è un pacchetto IPv4, l'algoritmo di Hash utilizza come variabili in input gli indirizzi IPv4 sorgente e destinazione.
- Se il pacchetto trasportato da MPLS è un pacchetto IPv6, l'algoritmo di Hash utilizza come variabili in input gli indirizzi IPv5 sorgente e destinazione.
- Se il pacchetto trasportato da MPLS non è né un pacchetto IPv4 né un pacchetto IPv6, l'algoritmo di Hash utilizza come unica variabile in input il valore dell'etichetta MPLS più interna, ossia l'ultima nella pila di etichette MPLS (in altre parole, per i più esperti di MPLS, quella che ha il bit S=1).
Questo sembrerebbe chiudere il cerchio e quindi terminare la storia. Purtroppo non è così. Questo trucco fallisce miseramente in presenza di trasporto di trame di Livello 2, come ad esempio nei servizi VPWS (Virtual Private Wire Service) e VPLS (Virtual Private LAN Service). Supponiamo ad esempio che il LSP del nostro esempio trasporti delle trame Ethernet, perché magari abbiamo realizzato un servizio VPLS per collegare dei router CE collegati ai due PE origine e destinazione del LSP MPLS (PE11 e PE21). In questo caso sorgono due problemi:
- Se l'indirizzo MAC destinazione ha i primi 4 bit che coincidono con 4 o 6, il LSR considera l'intera trama Ethernet come un pacchetto IPv4 o IPv6, sbagliando clamorosamente. Per evitare questo, la documentazione Cisco consiglia di aggiungere sempre i 4 byte della Control Word, che, secondo la RFC 4385, ha sempre i primi 4 bit nulli (e quindi mai pari a 4 o 6).
- Viceversa, se i primi 4 bit non coincidono con 4 o 6, è vero che il router non sbaglia, ma il LB, che è basato in questo caso sull'etichetta MPLS più interna (che in questo caso coincide con la VC Label che caratterizza lo pseudowire), non è molto efficiente poiché non consente di distribuire il traffico su più Next-Hop.
Entrambi questi problemi sarebbero di facile soluzione se un LSR avesse accesso all'intero payload MPLS, come ad esempio l'Edge-LSR di ingresso. Vedremo che i due nuovi standard che saranno illustrati in seguito, sono proprio basati su questa considerazione.
LOAD BALANCING DI PACCHETTI MPLS NEI ROUTER JUNIPER
Gli esperti di router Juniper sanno che a differenza dei router Cisco, il LB non viene effettuato di default ma va abilitato con la seguente sequenza di comandi:
policy-options {
policy-statement LB {
then {
load-balance per-packet;
}
}
routing-options {
forwarding-table {
export LB;
}
}
dove però, attenzione, il comando "load-balance per-packet" è molto ambiguo, perché non abilita il LB per pacchetto, ma il LB "per flusso". Purtroppo però il comando è questo e così bisogna tenerselo.
Nel caso di un LSR di transito, se questo ha due o più Next-Hop "ottimi" disponibili, l'abilitazione del LB comporta per ciascun pacchetto MPLS entrante, come nei router Cisco, la possibilità di utilizzarli tutti, come nel seguente esempio con due Next-Hop disponibili:
tt@CE1> show route forwarding-table family mpls label 299824
Routing table: default.mpls
MPLS:
Destination Type RtRef Next hop Type Index NhRef Netif
299824 user 0 ulst 131070 2
10.1.11.1 Swap 299792 562 1 fe-0/0/0.0
10.1.21.1 Swap 299776 563 1 fe-0/0/1.0
Con quale criterio di default i router Juniper utilizzano i due Next-Hop disponibili ? Non ho trovato nella documentazione Juniper informazioni precise in merito, però in ogni caso c'è la possibilità di scegliere le variabili da utilizzare in input all'algoritmo di Hash per la scelta del Next-Hop. Le variabili possono essere molteplici e vanno dalle etichette MPLS ai campi di livello 3 e/o 4. Ogni piattaforma poi ha più o meno variabili configurabili. La scelta va eseguita nella gerarchia di configurazione [edit forwarding-options hash-key family mpls]. Ad esempio, qualora si volessero utilizzare come input, la prima etichetta MPLS (la più esterna), quella successiva e gli indirizzi IP sorgente e destinazione, la configurazione da eseguire è la seguente:
[edit forwarding-options hash-key family mpls]
tt@router# show
label-1;
label-2;
payload {
ip;
}
In realtà, piuttosto che tutti i 64 bit delle prime intestazioni MPLS contenenti le prime due etichette, vengono utilizzati tutti i 32 bit della prima intestazione e i primi 16 bit della seconda. Un elenco di tutte le variabili configurabili disponibili nelle varie piattaforme, può essere trovato in questo documento:
LOAD BALANCING VIA FAT LABELS (RFC 6391)
Da quanto detto sopra, l'elemento chiave per eseguire un LB efficiente è l'Edge-LSR di ingresso, che è l'unico in grado di effettuare una deep inspection sul pacchetto o trama L2 entrante prima dell'incapsulamento MPLS. In teoria anche i router intermedi potrebbero effettuare questa deep inspection, ma al prezzo di un serio degrado delle prestazioni. L'ideale sarebbe di effettuare questa deep inspection solo sull'Edge-LSR di ingresso e quindi aggiungere al pacchetto MPLS una nuova variabile da utilizzare come input all'algoritmo di Hash. Su questa idea si basa la soluzione introdotta nella RFC 6391 "Flow-Aware Transport of Pseudowires over an MPLS Packet Switched Network" del Novembre 2011, che si basa sull'aggiunta di una nuova etichetta MPLS (FAT Label), da utilizzare esclusivamente come input all'algoritmo di Hash (NOTA: FAT in questo caso non significa "grasso" , ma è un acronimo che sta per Flow-Aware Transport; dico questo perché magari qualcuno potrebbe pensare che poiché l'intestazione MPLS viene anche chiamata shim header, ossia "intestazione snella", viene aggiunta una FAT Label, ossia "etichetta grassa", per riportarla al giusto peso (ovviamente sto solo scherzando ) !).
La soluzione è molto semplice, ma vale solo per gli pseudowire, e quindi utilizzabile in servizi MPLS come VPWS e VPLS (solo con segnalazione LDP).
Come dicevo sopra l'idea è molto semplice. Poiché l'Edge-LSR di ingresso ha a disposizione la trama L2 da trasportare negli pseudowire, può eseguire una deep inspection ed individuare i flussi "divisibili" presenti all'interno di tutto il traffico trasportato dallo pseudowire. Per ciascun flusso viene quindi generata una FAT Label, che viene aggiunta nella posizione più interna della pila delle due etichette MPLS utilizzate dallo pseudowire, ossia, tra la VC Label e la Control Word (vedi figura seguente).
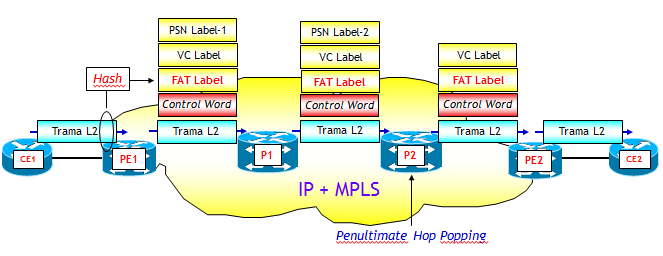
La FAT Label viene generata attraverso un algoritmo di Hash, che ha come variabili in input vari campi di Livello 2, 3 e/o 4. La FAT Label viene quindi utilizzata dai LSR di transito come sola variabile di input all'algoritmo di Hash che esegue il LB. I campi di Livello 2, 3 e/o 4 utilizzati per determinare la FAT Label sono i campi che individuano, con più o meno granularità, i flussi "divisibili" all'interno di tutto il traffico trasportato dallo pseudowire. La FAT Label non viene utilizzata per l'instradamento, ma solo ed esclusivamente per il LB, e viene tolta dall'Edge-LSR di uscita prima di consegnare la trama L2 al router destinazione.
Poiché non tutti i router potrebbero supportare l'utilizzo della FAT Label, questa funzionalità va negoziata attraverso una opportuna segnalazione. La RFC 6391 specifica la segnalazione via LDP (multi-hop) e nulla dice riguardo alla segnalazione BGP. La segnalazione avviene attraverso il nuovo modulo Flow Label sub-TLV, inserito nel modulo Interface Parameter sub-TLV. Per chi non fosse familiare con la segnalazione LDP multi-hop degli pseudowire, l'Interface Parameter sub-TLV è un modulo TLV (Type-Length-Value) aggiunto alla fine del modulo TLV PW ID FEC TLV, parte di un messaggio LDP LABEL MAPPING (vedi figura seguente), che viene utilizzato per definire alcuni parametri specifici di una interfaccia lato CE (es. MTU, stringa di descrizione, VLAN ID).

Per una spiegazione dettagliata dei vari campi, il lettore interessato può consultare la RFC 4447. A sua volta il campo Interface Parameter sub-TLV è composto da tanti moduli TLV, di cui uno di questi potrebbe essere il nuovo modulo Flow Label sub-TLV, che ha il formato riportato nella figura seguente:

I due campi significativi sono i due bit T e R, il cui significato indica il supporto delle FAT Label rispettivamente in trasmissione e in ricezione. Un router che supporta le FAT Label può quindi segnalarlo ponendo i due bit T e R entrambi a 1.
La figura seguente mostra uno scenario di utilizzo delle FAT Label.
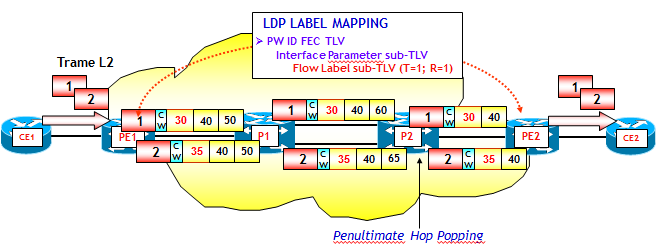
Per ipotesi, entrambi gli Edge-LSR PE1 e PE2 supportano le FAT Label. Il supporto viene comunicato in fase di segnalazione attraverso il modulo Flow Label sub-TLV con i bit T=R=1. Supponiamo che l'Edge-LSR di ingresso, per ipotesi il router PE1, riceva due flussi IPv4 da trasportare all'interno dello stesso pseudowire. Per ciascun flusso, PE1 determina una FAT Label, che viene interposta tra la VC Label e la Control Word. Le due FAT Label (30 e 35 nella figura), vengono utilizzate dal router P come input all'algoritmo di Hash che consente di effettuare il LB sui due collegamenti disponibili. L'Edge-LSR di uscita, il router PE2, a causa del Penultimate Hop Popping, riceve quindi le trame con due etichette MPLS, la VC Label e la FAT Label. La VC Label come noto serve ad individuare lo pseudowire, e la FAT Label a questo punto non viene utilizzata poiché il pacchetto MPLS è giunto al "capolinea". PE2 esegue infine una operazione di Label Pop su entrambe le etichette, e invia le trame L2 a destinazione.
Circa il supporto delle FAT Label nei router Cisco e Juniper, ho appurato che nei router Cisco sono supportate nei router della serie 76xx e negli ASR 9k, a partire dall'IOS XR 4.2.1. Negli ASR 9k la configurazione da eseguire per abilitare il supporto delle FAT Label è la seguente:
RP/0/RP0/CPU0:router(config)#l2vpn
RP/0/RP0/CPU0:router(config-l2vpn)#pw-class NOME-PW-CLASS
RP/0/RP0/CPU0:router(config-l2vpn-pwc)#encapsulation mpls
RP/0/RP0/CPU0:router(config-l2vpn-pwc-mpls)#load-balancing flow-label { both | receive | transmit }
E' possibile inoltre scegliere le variabili in input dell'algoritmo di Hash che consente di determinare le FAT Label, anche se la scelta è limitata. Ad esempio, nel caso di pacchetti IP, con il comando:
RP/0/RP0/CPU0:router(config)#l2vpn
RP/0/RP0/CPU0:router(config-l2vpn)# load-balancing flow src-dst-ip
è possibile utilizzare come variabili di input gli indirizzi IP sorgente e destinazione. In alternativa, con il comando "load-balancing flow src-dst-mac" è possibile utilizzare come variabili gli indirizzi MAC sorgente e destinazione (solo nel caso di trame Ethernet, ovviamente).
Il JUNOS supporta le FAT Label sia per i servizi VPWS e VPLS con segnalazione LDP e auto-discovery sia manuale che via BGP. Per semplicità, illustrerò le configurazioni solo per il caso di auto-discovery manuale. La configurazione da eseguire per abilitare il supporto delle FAT Label è la seguente:
[edit protocols l2circuit neighbor neighbor-id interface interfaccia]
tt@Edge-LSR-Ingresso# show
flow-label-transmit;
flow-label-receive;
Un esempio completo di configurazione è il seguente:
[edit protocols l2circuit]
tt@PE1# show
neighbor 192.168.0.2 {
interface ge-0/0/0.0 { # Attachment Circuit lato CE
virtual-circuit-id 100;
flow-label-transmit;
flow-label-receive;
}
}
La scelta delle variabili in input dell'algoritmo di Hash che consente di determinare le FAT Label, può essere eseguita con i comandi illustrati in precedenza all'interno della gerarchia di configurazione [edit forwarding-options hash-key family mpls], dove però, faccio notare, non ha senso inserire nelle variabili le etichette MPLS perché le trame L2 arrivano all'Edge-LSR di ingresso senza etichette MPLS.
LOAD BALANCING VIA ENTROPY LABELS (RFC 6790)
Il trucco delle FAT Label, come visto nella sezione precedente, si applica solo al caso degli pseudowire, e funziona perché l'Edge-LSR di uscita conosce esattamente il valore numerico della VC Label, dietro la quale si "nasconde" la FAT Label. Lo stesso trucco non funzionerebbe ad esempio, nel caso di semplice trasporto con singola etichetta. Questo perché in tal caso, a causa del Penultimate Hop Popping (PHP), il pacchetto MPLS arriverebbe all'Edge-LSR di uscita con la sola FAT Label, e questo non saprebbe come gestirla, non avendola scelta.
Successivamente alla RFC 6391, è uscita un nuovo standard, che specifica un metodo più generale, valido non solo nel caso di pseudowire, ma in generale per ogni tipo di trasporto MPLS. Lo standard in questione è definito nella RFC 6790 "The Use of Entropy Labels in MPLS Forwarding", del Novembre 2012. L'idea di fondo è la stessa della RFC 6391, ma la modalità di applicazione è diversa e, come detto, più generale. Al pari delle FAT Label, le Entropy Label non sono segnalate e non sono utilizzate per il forwarding, ma solo per il LB. Come valore può essere utilizzato un qualsiasi numero, purché non appartenente a quelli riservati (valori 0-15).
++++++++++ BREVE FUORI TEMA ++++++++++
L'utilizzo del termine Entropy (entropia) per indicare queste etichette è molto suggestivo e richiama un noto concetto della fisica che si applica a vari campi, tra cui la termodinamica, la meccanica statistica, la teoria dei segnali, la teoria dell'informazione, ecc. . L'entropia (dal greco antico ?ν en, "dentro", e τροπ? tropé, "trasformazione") è una grandezza (più in particolare una coordinata generalizzata) che viene interpretata come una misura del disordine presente in un sistema fisico qualsiasi, incluso, come caso limite, l'universo.
++++++++++ FINE FUORI TEMA ++++++++++
Dopo questa breve digressione, ritornando al nostro caso, è possibile pensare a un flusso di pacchetti come un insieme disordinato di elementi, e all'aumentare del disordine (ossia, del numero di flussi) cresce il numero di etichette MPLS necessario a "ordinarli". Le Entropy Label possono quindi essere pensate come delle etichette che cercano di mettere ordine in un sistema altamente disordinato. Non so se sia questa l'interpretazione che hanno dato gli autori della RFC all'utilizzo del termine Entropy, ma a me suona suggestivo così.
Si noti che per servizi come L2VPN, L3VPN, 6PE, 6VPE, ecc., a causa della presenza di una VC Label, o VPN Label, ecc., in funzione del servizio, (talvolta anche chiamata, in generale, Application Label), vi è minore ambiguità per gli Edge-LSR di uscita nel riconoscere una Entropy Label (in modo identico a quanto avviene per le FAT Label). Però per il semplice forwarding di pacchetti IP, come detto sopra, a causa del PHP un Edge-LSR di uscita non è in grado di sapere che l'etichetta ricevuta appartiene a una Entropy Label piuttosto a una normale Application Label. Ad esempio, pensate ad un router PE (che gioca in questo caso il ruolo di Edge-LSR di uscita) che per un servizio L3VPN annunci (via MP-iBGP) la VPN Label 1954, associata a un prefisso VPN-IPv4. Nel momento in cui riceverà successivamente un pacchetto MPLS con la sola etichetta MPLS 1954, come farà a sapere se quella è una Entropy Label o una VPN Label ? Chiaramente, una decisione sbagliata porta il payload MPLS trasportato in una direzione sbagliata.
Per evitare qualsiasi ambiguità, la RFC 6790 ha definito l'etichetta speciale con valore 7, denominata Entropy Label Indicator (ELI). Questa etichetta va sempre anteposta a una Entropy Label, in modo tale che chi riceve un pacchetto MPLS, sa con certezza che dopo la ELI vi è una Entropy Label. Sia la ELI che la Entropy Label sono imposte tramite una operazione di Label Push dall'Edge-LSR di ingresso.
Come avviene per le FAT Label, il supporto delle Entropy Label va negoziato. La RFC 6790 stabilisce come va effettuata la negoziazione sia per il protocollo LDP, che per i protocolli BGP e RSVP-TE.
Nel caso del protocollo LDP, la negoziazione avviene attraverso il nuovo modulo ELC TLV (Entropy Label Capability TLV), che viene aggiunto ai parametri opzionali dei messaggi LDP LABEL MAPPING. La struttura del modulo ELC TLV è riportata nella figura seguente:
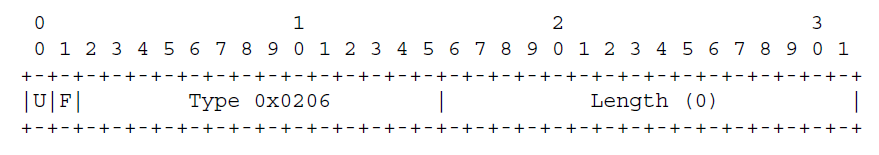
dove il significato dei bit U e F è specificato dal protocollo LDP classico (RFC 5036). Per il modulo ELC TLV, entrambi questi bit sono posti a 1. Ricordo che il bit U, quando pari a 1 indica che un LDP peer che riceve il messaggio LDP LABEL MAPPING con un modulo ELC TLV, qualora non sia in grado di elaborarlo deve ignorarlo. Il bit F invece, quando posto a 1 indica che un modulo ELC TLV in ogni caso deve essere propagato hop-by-hop nella direzione downstream agli altri LDP peer. La presenza di un modulo ELC TLV in un messaggio LDP LABEL MAPPING, indica all'Edge-LSR di ingresso, che l'Edge-LSR di uscita supporta l'elaborazione delle Entropy Label.
Solo per fare un esempio, la figura seguente mostra come avviene la segnalazione nel caso di un LSP MPLS realizzato via LDP+IGP, che trasporta pacchetti del servizio L3VPN, e cosa avviene nel piano dati. In funzione dell'implementazione, i router P, che sono LSR, possono utilizzare come variabili di input all'algoritmo di Hash per il LB o l'intera pila di etichette MPLS (ad esclusione dell'etichetta ELI), o la sola Entropy Label (NOTA: la RFC 6790 non impone regole precise al riguardo).

Circa il supporto delle Entropy Label nei router Cisco e Juniper, non mi risulta al momento che la RFC 6790 sia ancora supportata dai router Cisco, mentre è già supportata nel JUNOS a partire dalla versione 14.1 (solo in alcune piattaforme, della serie MX, T e PTX). Per LSP MPLS realizzati via IGP+LDP, la configurazione da eseguire sugli Edge-LSR è la seguente
(vedi http://www.juniper.net/techpubs/en_US/junos14.1/topics/reference/configuration-statement/entropy-label-edit-protocols-mpls.html):
[edit protocols ldp]
tt@router# show
entropy-label {
ingress-policy nome routing-policy;
}
dove attraverso la routing policy vengono individuate le FEC (Forwarding Equivalence Class) a cui appartengono i pacchetti a cui aggiungere l'Entropy Label.
La documentazione JUNOS (http://www.juniper.net/techpubs/en_US/junos14.1/topics/task/configuration/mpls-entopy-label-configuring.html), dice inoltre che i LSR di transito non richiedono alcuna configurazione.
CONCLUSIONI
MPLS è uno standard ormai ben consolidato, che richiede però di tanto in tanto qualche manutenzione. In questo Post ho illustrato due nuovi standard, che consentono di migliorare le prestazioni di Load Balancing. Cercherò eventualmente di tornarci su non appena le implementazioni dei maggiori costruttori saranno più stabili. Purtroppo i router che ho a disposizione nei nostri Lab, non mi consentono di effettuare delle prove. Le funzionalità esposte in questo Post sono appannaggio di router di fascia alta, e al momento la nostra "cassa" non ci permette di acquistarli.
Siete nuovi a MPLS, oppure avete bisogno di ulteriori approfondimenti ? Tanti anni fa (nel lontano 2003) ho scritto un libro sull'argomento "MPLS: fondamenti e applicazioni alle reti IP", Ed. Hoepli. Purtroppo non è più in commercio per manifesti "limiti di età". Se siete interessati a una copia scrivetemi una e-mail (Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.) e vedrò come fare. Oppure seguite i nostro corsi IPN272 "MPLS: dalla teoria alla pratica", IPN273 "MPLS: servizi avanzati", IPN276 "MPLS nell'IOS XR Cisco", IPN258 "MPLS nel JUNOS Juniper".
Siete nuovi a MPLS, oppure avete bisogno di ulteriori approfondimenti ? Tanti anni fa (nel lontano 2003) ho scritto un libro sull'argomento "MPLS: fondamenti e applicazioni alle reti IP", Ed. Hoepli. Purtroppo non è più in commercio per manifesti "limiti di età". Se siete interessati a una copia scrivetemi una e-mail (Questo indirizzo email è protetto dagli spambots. È necessario abilitare JavaScript per vederlo.) e vedrò come fare. Oppure seguite i nostro corsi IPN272 "MPLS: dalla teoria alla pratica", IPN273 "MPLS: servizi avanzati", IPN276 "MPLS nell'IOS XR Cisco", IPN258 "MPLS nel JUNOS Juniper".
