


Tiziano
Sabato, 03 Ottobre 2015 06:11
MPLS NEWS : LSP DI TIPO MULTIPOINT – PARTE I
Nel post precedente sul modello NG-MVPN ho detto che questo offre diverse opzioni per quanto riguarda il piano dati, sia in termini di segnalazione che di incapsulamento del traffico. Per quanto riguarda l’incapsulamento, due sono le opzioni previste:
I LSP MPLS di tipo multipoint trovano applicazioni anche in altri contesti, tra cui:
DEFINIZIONE DI LSP MULTIPOINT
Nella loro versione “classica”, i LSP MPLS possono essere stabiliti utilizzando come protocolli sia LDP (LSP di tipo Hop-by-Hop), che RSVP-TE (LSP di tipo Explicitly Routed). Nel primo caso i LSP MPLS sono di tipo MultiPoint-to-Point (MP2P), ossia trasportano traffico da più punti di ingresso a un punto di uscita. Per contro, nel secondo caso i LSP MPLS sono di tipo punto-punto, ossia partono da un LSR di ingresso e terminano su un ben preciso LSR di uscita.
Vi è una terza possibilità, quella di creare LSP di tipo punto-multipunto (Point-to-MultiPoint, P2MP), ossia LSP che trasportano traffico da un ben preciso LSR di ingresso a più LSR di uscita. In realtà vi è anche la possibilità di creare, ma solo attraverso mLDP, LSP di tipo MultiPoint-to-MultiPoint (MP2MP). Non li tratteremo in questo post, ma in un post successivo dedicato a mLDP.
Il concetto di LSP P2MP è molto simile al concetto di albero multicast, ossia un LSP P2MP permette di veicolare in modo efficiente traffico multicast, senza che il LSR di ingresso sia costretto a inviare più copie dello stesso traffico a più ricevitori. Come noto invece, un albero multicast ottimizza il trasporto del traffico verso più sorgenti, replicando i pacchetti solo in determinati punti (punti di diramazione dell’albero multicast).
I LSP P2MP possono essere realizzati sia attraverso RSVP-TE che LDP, opportunamente estesi. L’estensione di RSVP-TE per la realizzazione di LSP P2MP è specificata nello standard RFC 4875, Extensions to Resource Reservation Protocol - Traffic Engineering (RSVP-TE) for Point-to-Multipoint TE Label Switched Paths (LSPs), Maggio 2007.
L’estensione di LDP per la realizzazione di LSP P2MP è specificata nella RFC 6388 - Label Distribution Protocol Extensions for Point-to-Multipoint and Multipoint-to-Multipoint Label Switched Paths, Novembre 2011. Nella letteratura tecnica, questa estensione di LDP viene indicata, come ho detto nella premessa, mLDP (multipoint LDP).
L’utilizzo dell’uno o dell’altro protocollo è comunque legato agli stessi fattori per cui si preferisce utilizzare in pratica LDP o RSVP-TE. L’utilizzo di LDP rende la realizzazione di LSP più semplice e più “automatica”, ma non consente servizi aggiuntivi come la definizione di vincoli (di banda, di classi amministrative, di percorsi, ecc.) e il Fast Rerouting.
FORWARDINGDEL TRAFFICO
La figura seguente riporta un esempio come il traffico multicast potrebbe essere veicolato su una rete IP/MPLS, utilizzando LSP di tipo punto-punto.
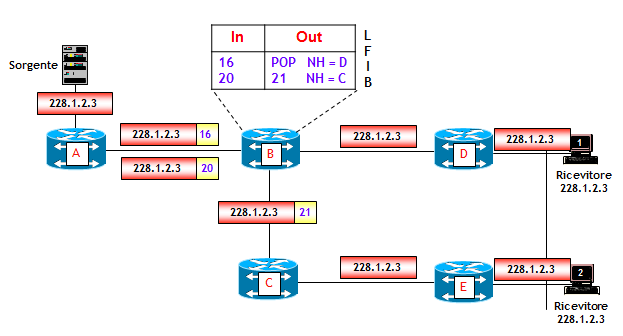
Il pacchetto IP multicast generato dalla sorgente, viene replicato dal LSR dove la sorgente è attestata (LSR A) due volte, un pacchetto con l’etichetta MPLS del LSP da LSR A a LSR D (etichetta 16), e un pacchetto con l’etichetta MPLS del LSP da LSR A a LSR E (etichetta 20). In particolare, il pacchetto iniziale viene veicolato verso i ricevitori utilizzando due LSP punto-punto, il primo dal LSR A al LSR D ed il secondo dal LSR A al LSR E.
Dal punto di vista della segnalazione RSVP-TE, il LSR A scambia messaggi PATH e RESV con i LSR D ed E in modo “ordinario” creando due LSP punto-punto.
Il punto chiave è nel LSR B, che genera messaggi RESV con etichette MPLS diverse per ciascun LSP (nella figura l’etichetta MPLS 16 per il LSP da A a D, e l’etichetta 20 per il LSP da a ad E).
Questa modalità di trasporto del traffico multicast, benché inefficiente dal punto di vista dell’utilizzo della banda, è comunque presente tra le 7 possibilità di piano dati del modello NG-MVPN (identificata dal tipo 6 (= Ingress Replication), vedi post precedente sul modello NG-MVPN). Ha il vantaggio che non richiede alcuna estensione di RSVP-TE (o LDP), ma è applicabile solamente a reti di piccole dimensioni.
Un LSP P2MP ha un singolo LSR di ingresso e più LSR di uscita. Nella rete della figura seguente, il LSR di ingresso è il LSR A e i due LSR di uscita sono i LSR D ed E.
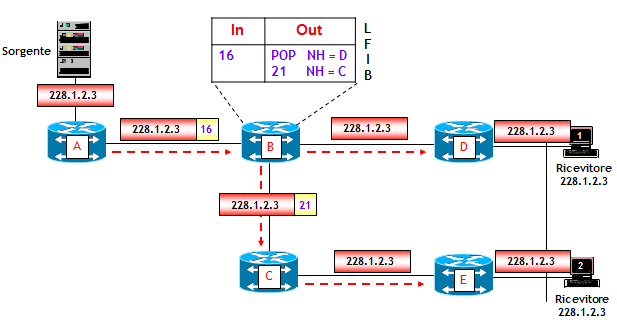
Come si può vedere nella figura, utilizzando un LSP P2MP con origine nel LSR A, il LSR di ingresso A crea una sola copia del pacchetto multicast destinato ai due ricevitori. A questa singola copia è associata l’etichetta MPLS 16. Il pacchetto viene inviato al LSR B, che lo replica verso C e D eseguendo rispettivamente le operazioni MPLS “swap 21” e “label pop” (NOTA: mostrerò nel seguito come l’operazione di “label pop”, nota in MPLS come Penultimate Hop Popping, non è appropriata nel modello NG-MVPN). Il LSR B è un punto di diramazione del traffico, ossia un punto dove un pacchetto in ingresso viene replicato su più punti di uscita.
La differenza con il caso precedente, dove il traffico multicast viene veicolato su due LSP punto-punto separati, è nel LSR B. Nella tabella LFIB di B, in corrispondenza dell’etichetta 16 vi sono due uscite, una verso il LSR C con l’etichetta 21 e l’altra verso il LSR D senza etichetta (operazione di “label pop”). Questo indica al LSR B che quando riceve un pacchetto MPLS con etichetta 16, deve replicare il pacchetto verso i due LSR C e D eseguendo le operazioni sulla pila di etichette MPLS descritte nella tabella LFIB.
Il vantaggio dell’utilizzo di un LSP P2MP rispetto all’utilizzo di più LSP punto-punto è evidente: sul collegamento tra i LSR A e B viene utilizzata metà della banda. In ultima analisi, questa è la stessa differenza che esiste nel veicolare traffico multicast su una rete puramente IP, utilizzando protocolli routing multicast in luogo di protocolli di routing unicast.
DETERMINAZIONE DEI PERCORSI
La determinazione dei percorsi seguiti da un LSP P2MP è un argomento che in realtà esula dal tipo di segnalazione adottato. Ciononostante è un argomento di grande interesse, molto complesso, di cui daremo solo alcuni cenni.
L’obiettivo è quello di determinare il percorso del LSP P2MP tenendo conto di criteri che definiscono un percorso “ottimo” secondo i desiderata dell’utilizzatore. Ad esempio, se l’obiettivo fosse quello di minimizzare il ritardo end-to-end, un albero di cammini minimi (shortest-path tree) con metrica minimum-hop potrebbe essere sufficiente. Se d’altra parte l’obiettivo fosse quello di minimizzare l’utilizzo della banda, un albero a minimo costo in termini di utilizzo della banda (minimum-cost tree, detto anche Steiner tree) potrebbe essere più appropriato.
La figura seguente mette a confronto proprio questi due criteri, con l’ipotesi che ciascun link della rete abbia identica banda e ciascuna interfaccia identica metrica.
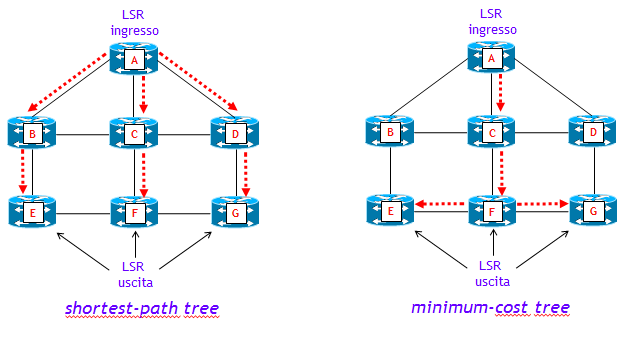
Nel caso di shortest-path tree vengono utilizzate sei unità di banda (ossia, un totale di 6 link), mentre nel caso di minimum-cost tree solo 4 unità di banda, ma con il rovescio della medaglia che alcuni percorsi sono distanti tre hop, e quindi il ritardo end-to-end è maggiore.
Questa libertà nella determinazione del percorso del LSP P2MP secondo i desiderata dell’utilizzatore, contrasta con quanto avviene nel tradizionale routing IP multicast, dove come risultato si ottengono solo shortest-path tree (con radice un Rendezvous-Point o un LSR dove è attestata una sorgente di traffico multicast). E non c’è modo di variare questo comportamento di base.
Come per i LSP punto-punto realizzati via MPLS-TE (con segnalazione RSVP-TE), sono possibili tre metodi per la determinazione del percorso:
SEGNALAZIONE RSVP-TE DI LSP MPLS P2MP
Come citato sopra, i LSP P2MP possono essere realizzati sia via RSVP-TE che LDP, opportunamente estesi. Con RSVP-TE, un LSP P2MP viene visto come un insieme di LSP, denominati Source-to-Leaf (S2L) sub-LSP, che partono tutti da un comune LSR di ingresso e ciascuno termina su un LSR di uscita (NOTA: per brevità nel seguito indicheremo i S2L sub-LSP semplicemente come sub-LSP). Nell’esempio visto sopra, vengono segnalati due sub-LSP, entrambi con LSR di ingresso A e ciascuno rispettivamente con LSR di uscita D ed E.
Per dare ai LSR uno strumento che permetta loro di capire che i sub-LSP sono associati ad uno stesso LSP P2MP, la segnalazione RSVP-TE utilizza un nuovo oggetto denominato “P2MP Session Object”, contenuto sia nei messaggi PATH che RESV. Un “P2MP Session Object” è costituito da una tripletta di elementi che identificano univocamente un LSP P2MP: <P2MP ID, Tunnel ID, Extended Tunnel ID>, per il cui significato rimandiamo alle RFC 2205 e RFC 4875.
Il meccanismo di segnalazione è analogo a quello per la realizzazione di LSP di tipo punto-punto, e verrà descritto nelle sue linee generali fra poco.
Un aspetto importante è che in qualche modo è necessario informare il LSR di ingresso su quali siano i LSR di uscita del LSP P2MP e sui percorsi da seguire. Una volta avute queste informazioni, vengono generati dal LSR di ingresso messaggi PATH e RESV per ciascun sub-LSP, con ciascun messaggio PATH contenente un oggetto ERO, determinato allo stesso modo dei LSP punto-punto.
Le figura seguente e la successiva riportano un esempio di segnalazione RSVP-TE di un LSP P2MP. In particolare questa diapositiva riporta il flusso dei messaggi PATH.
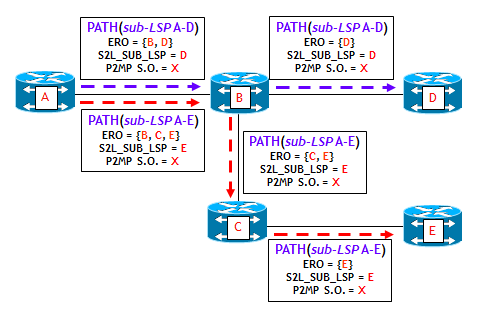
Il LSR di ingresso invia un messaggio PATH per ciascun sub-LSP. Ogni messaggio PATH contiene essenzialmente le stesse informazioni già citate per la realizzazione di LSP punto-punto, con in più il “P2MP Session Object” che identifica univocamente il LSP P2MP.
L’ERO (Explicit Route Object) contenuto nei messaggi PATH è funzione del metodo utilizzato nella determinazione del percorso (manuale, online, off-line) e del criterio utilizzato (shortest-path tree, minimum-cost tree, ecc.).
Nell’esempio della figura, ecco ciò che avviene:
La figura mostra il flusso di messaggi RESV inviati a ritroso dai due LSR di uscita D ed E. Si noti che come per i LSP punto-punto, si utilizza una allocazione di etichette di tipo downstream. Nell’esempio della figura, ecco ciò che avviene:
Un LSR che riceve messaggi RESV con identico “P2MP Session Object” diventa così automaticamente un punto di diramazione del LSP P2MP.
Solo per fare un esempio pratico, i due comandi di tipo “show” seguenti, eseguiti su un router Juniper, mostrano le caratteristiche di un LSP MPLS P2MP realizzato via RSVP-TE, sul LSR di ingresso (PE1) e sul LSR di transito successivo (P1):
tt@PE1> show rsvp session p2mp ingress
Ingress RSVP: 2 sessions
P2MP name: 1:1:mvpn:VPN-A, P2MP branch count: 2
To From State Rt Style Labelin Labelout LSPname
192.168.0.3 192.168.0.1 Up 0 1 SE - 299840 192.168.0.3:1:1:mvpn:VPN-A
192.168.0.2 192.168.0.1 Up 0 1 SE - 299840 192.168.0.2:1:1:mvpn:VPN-A
Total 2 displayed, Up 2, Down 0
tt@P1> show rsvp session p2mp transit
Transit RSVP: 2 sessions
P2MP name: 1:1:mvpn:VPN-A, P2MP branch count: 2
To From State Rt Style Labelin Labelout LSPname
192.168.0.3 192.168.0.1 Up 0 1 SE 299840 299856 192.168.0.3:1:1:mvpn:VPN-A
192.168.0.2 192.168.0.1 Up 0 1 SE 299840 299840 192.168.0.2:1:1:mvpn:VPN-A
Total 2 displayed, Up 2, Down 0
Il LSP MPLS P2MP ha due sub-LSP (P2MP branch count: 2), entrambi con sorgente PE1 (RID 192.168.0.1) e destinazione due LSR: PE2 (RID 192.168.0.2) e PE3 (RID 192.168.0.3).
La visualizzazione riporta anche le etichette MPLS utilizzate. Sul LSR di ingresso, l’etichetta entrante ovviamente non esiste (Labelin – ), mentre l’etichetta uscente è per entrambi i sub-LSP pari a 299840 (Labelout 299840).
Sul primo LSR di transito incontrato (P1) l’etichetta entrante per entrambi i sub-LSP è 299840, mentre le etichette uscenti sono rispettivamente 299856 (per il sub-LSP con destinazione PE3) e 299840 (per il sub-LSP con destinazione PE2). Tutto ciò significa che P1 è un punto di diramazione del LSP P2MP.
L’esempio è tratto dalla configurazione di un servizio NG-MVPN. Si noti che il JUNOS assegna automaticamente dei nomi sia al LSP P2MP che ai singoli sub-LSP:
• Nome LSP P2MP = RD : mvpn : nome-VRF.
• Nome sub-LSP = RID LSR di uscita : RD : mvpn : nome-VRF.
RSVP-TE P2MP LSP NEL MODELLO NG-MVPN
Un aspetto molto importante, che differenzia il trasporto via MPLS del traffico VPN multicast da quello VPN unicast è che, mentre quest’ultimo viene trasportato utilizzando due etichette MPLS, il traffico VPN multicast viene trasportato utilizzando una sola etichetta MPLS.
Per indirizzare la VRF (o spesso, l’interfaccia) di uscita, il traffico VPN unicast utilizza come noto la seconda etichetta (interna), annunciata via MP-iBGP dal PE destinazione del traffico. Per contro, per indirizzare la mVRF di uscita, il traffico VPN multicast utilizza l’etichetta generata dal PE destinazione durante la fase di segnalazione del sub-LSP. Ciò significa che in questo contesto non viene applicato il Penultimate Hop Popping.
La figura seguente, tratta da un esempio reale in ambiente Juniper, riporta un esempio.
Il LSR PE1 è radice di un albero multicast (di tipo Selective o Inclusive, non fa differenza) e i LSR PE2 e PE3 sono due foglie. Tra PE1, PE2 e PE3 viene realizzato un LSP MPLS P2MP, costituito da due sub-LSP:
Il LSR PE1 incapsula il traffico multicast con l’etichetta MPLS 299.792, generata dal LSR P1, che è un punto di diramazione del LSP MPLS P2MP. Il LSR P1 genera due pacchetti MPLS, uno verso PE2 con etichetta 16 (generata da PE2 e associata al sub-LSP 1) e l’altro verso P2 con etichetta 299.792 (generata da P2 e associata al sub-LSP 2). Infine, P2 esegue la commutazione di etichetta da 299.792 a 299.850 (generata da PE3 e associata al sub-LSP 2) e inoltra il pacchetto MPLS verso PE3.
Ora, PE2 e PE3 utilizzano rispettivamente le etichette 16 e 299.850 per effettuare il lookup sulla tabella di routing multicast associata alla MVPN (ossia, sulla mVRF corretta).
CONCLUSIONI
In questo post ho illustrato il concetto di LSP MPLS multipoint di tipo P2MP, trattando in particolare la realizzazione di LSP MPLS P2MP tramite la segnalazione RSVP-TE. In un prossimo post sull’argomento illustrerò come sia invece possibile realizzare LSP P2MP e MP2MP via mLDP, mettendo a confronto i due tipi di segnalazione. Per motivi di spazio ho dovuto saltare alcuni aspetti, sui quali magari mi riprometto di tornare in seguito.
Ricordo che per chi volesse approfondire queste tematiche, abbiamo nel catalogo corsi della Reiss Romoli, un corso ad hoc di due giorni sul modello NG-MVPN (IPN269, Next Generation Multicast VPN), dove l’argomento dei LSP MPLS multipoint viene trattato con dovizia di particolari e dove sono previste esercitazioni con piattaforme Juniper.
- Tunnel GRE.
- LSP MPLS Point-to-Multipoint (P2MP) o Multipoint-to-Multipoint (MP2MP).
I LSP MPLS di tipo multipoint trovano applicazioni anche in altri contesti, tra cui:
- Il trasporto del traffico BUM nelle VPLS (Virtual Private LAN Service), vedi a questo proposito la recente RFC 7117 Multicast in Virtual Private LAN Service (VPLS) del Febbraio 2014. Questa applicazione è già stata implementata sia da Cisco negli ASR9k a partire dalla versione 5.1.0 dell’IOS XR, con segnalazione RSVP-TE, che da Juniper a partire addirittura dalla versione 9.3 del JUNOS.
- Il trasporto del traffico BUM nel modello EVPN (Ethernet VPN), un modello molto sofisticato che eventualmente rimpiazzerà il servizio VPLS, definito nella RFC 7432 BGP MPLS-Based Ethernet VPN del Febbraio 2015. Su questo modello EVPN scriverò in seguito qualche post poiché lo ritengo molto importante (anche se io ho una certa idiosincrasia per le reti Switched Ethernet !).
DEFINIZIONE DI LSP MULTIPOINT
Nella loro versione “classica”, i LSP MPLS possono essere stabiliti utilizzando come protocolli sia LDP (LSP di tipo Hop-by-Hop), che RSVP-TE (LSP di tipo Explicitly Routed). Nel primo caso i LSP MPLS sono di tipo MultiPoint-to-Point (MP2P), ossia trasportano traffico da più punti di ingresso a un punto di uscita. Per contro, nel secondo caso i LSP MPLS sono di tipo punto-punto, ossia partono da un LSR di ingresso e terminano su un ben preciso LSR di uscita.
Vi è una terza possibilità, quella di creare LSP di tipo punto-multipunto (Point-to-MultiPoint, P2MP), ossia LSP che trasportano traffico da un ben preciso LSR di ingresso a più LSR di uscita. In realtà vi è anche la possibilità di creare, ma solo attraverso mLDP, LSP di tipo MultiPoint-to-MultiPoint (MP2MP). Non li tratteremo in questo post, ma in un post successivo dedicato a mLDP.
Il concetto di LSP P2MP è molto simile al concetto di albero multicast, ossia un LSP P2MP permette di veicolare in modo efficiente traffico multicast, senza che il LSR di ingresso sia costretto a inviare più copie dello stesso traffico a più ricevitori. Come noto invece, un albero multicast ottimizza il trasporto del traffico verso più sorgenti, replicando i pacchetti solo in determinati punti (punti di diramazione dell’albero multicast).
I LSP P2MP possono essere realizzati sia attraverso RSVP-TE che LDP, opportunamente estesi. L’estensione di RSVP-TE per la realizzazione di LSP P2MP è specificata nello standard RFC 4875, Extensions to Resource Reservation Protocol - Traffic Engineering (RSVP-TE) for Point-to-Multipoint TE Label Switched Paths (LSPs), Maggio 2007.
L’estensione di LDP per la realizzazione di LSP P2MP è specificata nella RFC 6388 - Label Distribution Protocol Extensions for Point-to-Multipoint and Multipoint-to-Multipoint Label Switched Paths, Novembre 2011. Nella letteratura tecnica, questa estensione di LDP viene indicata, come ho detto nella premessa, mLDP (multipoint LDP).
L’utilizzo dell’uno o dell’altro protocollo è comunque legato agli stessi fattori per cui si preferisce utilizzare in pratica LDP o RSVP-TE. L’utilizzo di LDP rende la realizzazione di LSP più semplice e più “automatica”, ma non consente servizi aggiuntivi come la definizione di vincoli (di banda, di classi amministrative, di percorsi, ecc.) e il Fast Rerouting.
FORWARDINGDEL TRAFFICO
La figura seguente riporta un esempio come il traffico multicast potrebbe essere veicolato su una rete IP/MPLS, utilizzando LSP di tipo punto-punto.
Il pacchetto IP multicast generato dalla sorgente, viene replicato dal LSR dove la sorgente è attestata (LSR A) due volte, un pacchetto con l’etichetta MPLS del LSP da LSR A a LSR D (etichetta 16), e un pacchetto con l’etichetta MPLS del LSP da LSR A a LSR E (etichetta 20). In particolare, il pacchetto iniziale viene veicolato verso i ricevitori utilizzando due LSP punto-punto, il primo dal LSR A al LSR D ed il secondo dal LSR A al LSR E.
Dal punto di vista della segnalazione RSVP-TE, il LSR A scambia messaggi PATH e RESV con i LSR D ed E in modo “ordinario” creando due LSP punto-punto.
Il punto chiave è nel LSR B, che genera messaggi RESV con etichette MPLS diverse per ciascun LSP (nella figura l’etichetta MPLS 16 per il LSP da A a D, e l’etichetta 20 per il LSP da a ad E).
Questa modalità di trasporto del traffico multicast, benché inefficiente dal punto di vista dell’utilizzo della banda, è comunque presente tra le 7 possibilità di piano dati del modello NG-MVPN (identificata dal tipo 6 (= Ingress Replication), vedi post precedente sul modello NG-MVPN). Ha il vantaggio che non richiede alcuna estensione di RSVP-TE (o LDP), ma è applicabile solamente a reti di piccole dimensioni.
Un LSP P2MP ha un singolo LSR di ingresso e più LSR di uscita. Nella rete della figura seguente, il LSR di ingresso è il LSR A e i due LSR di uscita sono i LSR D ed E.
Come si può vedere nella figura, utilizzando un LSP P2MP con origine nel LSR A, il LSR di ingresso A crea una sola copia del pacchetto multicast destinato ai due ricevitori. A questa singola copia è associata l’etichetta MPLS 16. Il pacchetto viene inviato al LSR B, che lo replica verso C e D eseguendo rispettivamente le operazioni MPLS “swap 21” e “label pop” (NOTA: mostrerò nel seguito come l’operazione di “label pop”, nota in MPLS come Penultimate Hop Popping, non è appropriata nel modello NG-MVPN). Il LSR B è un punto di diramazione del traffico, ossia un punto dove un pacchetto in ingresso viene replicato su più punti di uscita.
La differenza con il caso precedente, dove il traffico multicast viene veicolato su due LSP punto-punto separati, è nel LSR B. Nella tabella LFIB di B, in corrispondenza dell’etichetta 16 vi sono due uscite, una verso il LSR C con l’etichetta 21 e l’altra verso il LSR D senza etichetta (operazione di “label pop”). Questo indica al LSR B che quando riceve un pacchetto MPLS con etichetta 16, deve replicare il pacchetto verso i due LSR C e D eseguendo le operazioni sulla pila di etichette MPLS descritte nella tabella LFIB.
Il vantaggio dell’utilizzo di un LSP P2MP rispetto all’utilizzo di più LSP punto-punto è evidente: sul collegamento tra i LSR A e B viene utilizzata metà della banda. In ultima analisi, questa è la stessa differenza che esiste nel veicolare traffico multicast su una rete puramente IP, utilizzando protocolli routing multicast in luogo di protocolli di routing unicast.
DETERMINAZIONE DEI PERCORSI
La determinazione dei percorsi seguiti da un LSP P2MP è un argomento che in realtà esula dal tipo di segnalazione adottato. Ciononostante è un argomento di grande interesse, molto complesso, di cui daremo solo alcuni cenni.
L’obiettivo è quello di determinare il percorso del LSP P2MP tenendo conto di criteri che definiscono un percorso “ottimo” secondo i desiderata dell’utilizzatore. Ad esempio, se l’obiettivo fosse quello di minimizzare il ritardo end-to-end, un albero di cammini minimi (shortest-path tree) con metrica minimum-hop potrebbe essere sufficiente. Se d’altra parte l’obiettivo fosse quello di minimizzare l’utilizzo della banda, un albero a minimo costo in termini di utilizzo della banda (minimum-cost tree, detto anche Steiner tree) potrebbe essere più appropriato.
La figura seguente mette a confronto proprio questi due criteri, con l’ipotesi che ciascun link della rete abbia identica banda e ciascuna interfaccia identica metrica.
Nel caso di shortest-path tree vengono utilizzate sei unità di banda (ossia, un totale di 6 link), mentre nel caso di minimum-cost tree solo 4 unità di banda, ma con il rovescio della medaglia che alcuni percorsi sono distanti tre hop, e quindi il ritardo end-to-end è maggiore.
Questa libertà nella determinazione del percorso del LSP P2MP secondo i desiderata dell’utilizzatore, contrasta con quanto avviene nel tradizionale routing IP multicast, dove come risultato si ottengono solo shortest-path tree (con radice un Rendezvous-Point o un LSR dove è attestata una sorgente di traffico multicast). E non c’è modo di variare questo comportamento di base.
Come per i LSP punto-punto realizzati via MPLS-TE (con segnalazione RSVP-TE), sono possibili tre metodi per la determinazione del percorso:
- Manuale, attraverso una attenta analisi della topologia della rete.
- Online, utilizzando l’algoritmo CSPF (previa definizione di eventuali vincoli).
- Off-line, utilizzando appropriati programmi di calcolo ottimo di percorsi.
SEGNALAZIONE RSVP-TE DI LSP MPLS P2MP
Come citato sopra, i LSP P2MP possono essere realizzati sia via RSVP-TE che LDP, opportunamente estesi. Con RSVP-TE, un LSP P2MP viene visto come un insieme di LSP, denominati Source-to-Leaf (S2L) sub-LSP, che partono tutti da un comune LSR di ingresso e ciascuno termina su un LSR di uscita (NOTA: per brevità nel seguito indicheremo i S2L sub-LSP semplicemente come sub-LSP). Nell’esempio visto sopra, vengono segnalati due sub-LSP, entrambi con LSR di ingresso A e ciascuno rispettivamente con LSR di uscita D ed E.
Per dare ai LSR uno strumento che permetta loro di capire che i sub-LSP sono associati ad uno stesso LSP P2MP, la segnalazione RSVP-TE utilizza un nuovo oggetto denominato “P2MP Session Object”, contenuto sia nei messaggi PATH che RESV. Un “P2MP Session Object” è costituito da una tripletta di elementi che identificano univocamente un LSP P2MP: <P2MP ID, Tunnel ID, Extended Tunnel ID>, per il cui significato rimandiamo alle RFC 2205 e RFC 4875.
Il meccanismo di segnalazione è analogo a quello per la realizzazione di LSP di tipo punto-punto, e verrà descritto nelle sue linee generali fra poco.
Un aspetto importante è che in qualche modo è necessario informare il LSR di ingresso su quali siano i LSR di uscita del LSP P2MP e sui percorsi da seguire. Una volta avute queste informazioni, vengono generati dal LSR di ingresso messaggi PATH e RESV per ciascun sub-LSP, con ciascun messaggio PATH contenente un oggetto ERO, determinato allo stesso modo dei LSP punto-punto.
Le figura seguente e la successiva riportano un esempio di segnalazione RSVP-TE di un LSP P2MP. In particolare questa diapositiva riporta il flusso dei messaggi PATH.
Il LSR di ingresso invia un messaggio PATH per ciascun sub-LSP. Ogni messaggio PATH contiene essenzialmente le stesse informazioni già citate per la realizzazione di LSP punto-punto, con in più il “P2MP Session Object” che identifica univocamente il LSP P2MP.
L’ERO (Explicit Route Object) contenuto nei messaggi PATH è funzione del metodo utilizzato nella determinazione del percorso (manuale, online, off-line) e del criterio utilizzato (shortest-path tree, minimum-cost tree, ecc.).
Nell’esempio della figura, ecco ciò che avviene:
- A fronte di una configurazione sul LSR di ingresso A, che permette di identificare i due LSR di uscita e i percorsi verso ciascuno di questi (segnalazione out-of-band), oppure attraverso una procedura di segnalazione automatica originato dai LSR di uscita (segnalazione in-band) vengono generati due messaggi PATH, uno per il sub-LSP da A ad E e uno per il sub-LSP da A a D. Ciascun messaggio PATH contiene un ERO che specifica il percorso e un identico “P2MP Session Object” (esemplificato con X nella figura, ma in realtà costituito da una tripletta di elementi). I due messaggi PATH vengono inviati al primo LSR presente negli ERO, che per entrambi i sub-LSP è il LSR B.
- Il LSR B, alla ricezione dei due messaggi PATH, esegue le stesse identiche operazioni come se i due sub-LSP fossero di tipo punto-punto. Crea così due nuovi messaggi PATH con gli ERO aggiornati e li invia rispettivamente ai LSR C e D.
- I LSR C e D ricevono i messaggi PATH e di nuovo li elaborano come se i due sub-LSP fossero di tipo punto-punto.
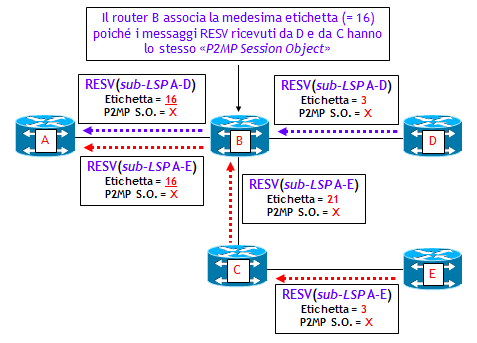
La figura mostra il flusso di messaggi RESV inviati a ritroso dai due LSR di uscita D ed E. Si noti che come per i LSP punto-punto, si utilizza una allocazione di etichette di tipo downstream. Nell’esempio della figura, ecco ciò che avviene:
- I LSR di uscita inviano ai due LSR da cui hanno ricevuto i messaggi PATH, due messaggi RESV ciascuno contenente una etichetta MPLS (inserita nel “Label Object”), e il comune “P2MP Session Object”. Nell’esempio, entrambi i LSR di uscita associano l’etichetta speciale 3 ai due sub-LSP (Penultimate Hop Popping), ma non è sempre questo il caso.
- Il LSR C riceve il messaggio RESV e a sua volta ne genera un altro, allocando la sua etichetta al sub-LSP da A ad E (etichetta 21).
- A questo punto il LSR B riceve due messaggi RESV con identico “P2MP Session Object”. E qui sta l’aspetto chiave della segnalazione: il LSR B associa ad entrambi i sub-LSP con identico “P2MP Session Object” la stessa etichetta MPLS (etichetta 16 nella figura). In conseguenza di ciò, il LSR B invia al LSR di ingresso A due messaggi RESV con identico “Label Object” contenente la stessa etichetta MPLS, e identico “P2MP Session Object” (NOTA: la RFC 4875 non obbliga l’invio di due messaggi RESV separati, ma contempla la possibilità di inviarne solo uno. Alcuni costruttori inviano inizialmente due messaggi RESV separati, e successivamente come rinfresco inviano un solo messaggio RESV).
Un LSR che riceve messaggi RESV con identico “P2MP Session Object” diventa così automaticamente un punto di diramazione del LSP P2MP.
Solo per fare un esempio pratico, i due comandi di tipo “show” seguenti, eseguiti su un router Juniper, mostrano le caratteristiche di un LSP MPLS P2MP realizzato via RSVP-TE, sul LSR di ingresso (PE1) e sul LSR di transito successivo (P1):
tt@PE1> show rsvp session p2mp ingress
Ingress RSVP: 2 sessions
P2MP name: 1:1:mvpn:VPN-A, P2MP branch count: 2
To From State Rt Style Labelin Labelout LSPname
192.168.0.3 192.168.0.1 Up 0 1 SE - 299840 192.168.0.3:1:1:mvpn:VPN-A
192.168.0.2 192.168.0.1 Up 0 1 SE - 299840 192.168.0.2:1:1:mvpn:VPN-A
Total 2 displayed, Up 2, Down 0
tt@P1> show rsvp session p2mp transit
Transit RSVP: 2 sessions
P2MP name: 1:1:mvpn:VPN-A, P2MP branch count: 2
To From State Rt Style Labelin Labelout LSPname
192.168.0.3 192.168.0.1 Up 0 1 SE 299840 299856 192.168.0.3:1:1:mvpn:VPN-A
192.168.0.2 192.168.0.1 Up 0 1 SE 299840 299840 192.168.0.2:1:1:mvpn:VPN-A
Total 2 displayed, Up 2, Down 0
Il LSP MPLS P2MP ha due sub-LSP (P2MP branch count: 2), entrambi con sorgente PE1 (RID 192.168.0.1) e destinazione due LSR: PE2 (RID 192.168.0.2) e PE3 (RID 192.168.0.3).
La visualizzazione riporta anche le etichette MPLS utilizzate. Sul LSR di ingresso, l’etichetta entrante ovviamente non esiste (Labelin – ), mentre l’etichetta uscente è per entrambi i sub-LSP pari a 299840 (Labelout 299840).
Sul primo LSR di transito incontrato (P1) l’etichetta entrante per entrambi i sub-LSP è 299840, mentre le etichette uscenti sono rispettivamente 299856 (per il sub-LSP con destinazione PE3) e 299840 (per il sub-LSP con destinazione PE2). Tutto ciò significa che P1 è un punto di diramazione del LSP P2MP.
L’esempio è tratto dalla configurazione di un servizio NG-MVPN. Si noti che il JUNOS assegna automaticamente dei nomi sia al LSP P2MP che ai singoli sub-LSP:
• Nome LSP P2MP = RD : mvpn : nome-VRF.
• Nome sub-LSP = RID LSR di uscita : RD : mvpn : nome-VRF.
RSVP-TE P2MP LSP NEL MODELLO NG-MVPN
Un aspetto molto importante, che differenzia il trasporto via MPLS del traffico VPN multicast da quello VPN unicast è che, mentre quest’ultimo viene trasportato utilizzando due etichette MPLS, il traffico VPN multicast viene trasportato utilizzando una sola etichetta MPLS.
Per indirizzare la VRF (o spesso, l’interfaccia) di uscita, il traffico VPN unicast utilizza come noto la seconda etichetta (interna), annunciata via MP-iBGP dal PE destinazione del traffico. Per contro, per indirizzare la mVRF di uscita, il traffico VPN multicast utilizza l’etichetta generata dal PE destinazione durante la fase di segnalazione del sub-LSP. Ciò significa che in questo contesto non viene applicato il Penultimate Hop Popping.
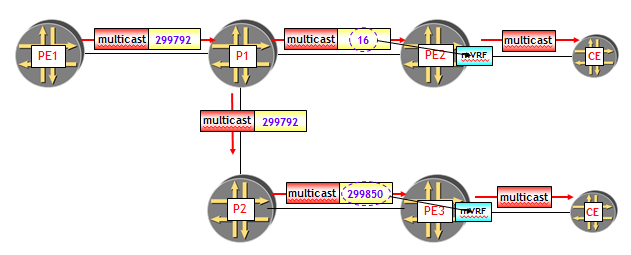
La figura seguente, tratta da un esempio reale in ambiente Juniper, riporta un esempio.
Il LSR PE1 è radice di un albero multicast (di tipo Selective o Inclusive, non fa differenza) e i LSR PE2 e PE3 sono due foglie. Tra PE1, PE2 e PE3 viene realizzato un LSP MPLS P2MP, costituito da due sub-LSP:
- sub-LSP1 : origine PE1, destinazione PE2.
- sub-LSP2 : origine PE1, destinazione PE3.
Il LSR PE1 incapsula il traffico multicast con l’etichetta MPLS 299.792, generata dal LSR P1, che è un punto di diramazione del LSP MPLS P2MP. Il LSR P1 genera due pacchetti MPLS, uno verso PE2 con etichetta 16 (generata da PE2 e associata al sub-LSP 1) e l’altro verso P2 con etichetta 299.792 (generata da P2 e associata al sub-LSP 2). Infine, P2 esegue la commutazione di etichetta da 299.792 a 299.850 (generata da PE3 e associata al sub-LSP 2) e inoltra il pacchetto MPLS verso PE3.
Ora, PE2 e PE3 utilizzano rispettivamente le etichette 16 e 299.850 per effettuare il lookup sulla tabella di routing multicast associata alla MVPN (ossia, sulla mVRF corretta).
CONCLUSIONI
In questo post ho illustrato il concetto di LSP MPLS multipoint di tipo P2MP, trattando in particolare la realizzazione di LSP MPLS P2MP tramite la segnalazione RSVP-TE. In un prossimo post sull’argomento illustrerò come sia invece possibile realizzare LSP P2MP e MP2MP via mLDP, mettendo a confronto i due tipi di segnalazione. Per motivi di spazio ho dovuto saltare alcuni aspetti, sui quali magari mi riprometto di tornare in seguito.
Ricordo che per chi volesse approfondire queste tematiche, abbiamo nel catalogo corsi della Reiss Romoli, un corso ad hoc di due giorni sul modello NG-MVPN (IPN269, Next Generation Multicast VPN), dove l’argomento dei LSP MPLS multipoint viene trattato con dovizia di particolari e dove sono previste esercitazioni con piattaforme Juniper.
Pubblicato in
ReissBlog
Etichettato sotto
Mercoledì, 16 Settembre 2015 15:11
LIBRO "IS-IS: DALLA TEORIA ALLA PRATICA" : CAP. 8
Dopo i primi 6 capitoli di "poesia", con la pubblicazione del capitolo 7 ho iniziato la "prosa". Con questo capitolo 8 la prosa continua.
Infatti, questo capitolo illustra le configurazioni di base per implementare IS-IS nelle piattaforme Juniper. Fortunatamente le piattaforme Juniper, a differenza di quelle Cisco, utilizzano una unica tipologia del loro sistema operativo, il JUNOS e quindi la trattazione sarà un po' più semplice.
Come per l'implementazione Cisco illustrata nel capitolo precedente, questo capitolo illustra l’implementazione base di IS-IS nel JUNOS. Altre configurazioni di aspetti avanzati saranno viste nei capitoli 9, 10 e 11. Ulteriori dettagli si trovano nella documentazione ufficiale Juniper delle varie piattaforme, reperibile facilmente sul web.
A grandi linee, il capitolo illustra:
- I comandi di configurazione di base (assegnazione del NET, abilitazione delle interfacce a IS-IS, scelta del tipo di IS, elezione del DIS, definizione delle metriche, ecc.).
- I comandi per configurare l’aggregazione dei prefissi e le modalità di configurazione.
- La procedura di configurazione del Route Leaking.
- I comandi di tipo “show …” e “traceoptions …” per la verifica della configurazione e la soluzione di problemi di troubleshooting.
Buona lettura !!!
Coming up next ... un post sugli LSP MPLS di tipo multipoint.
Pubblicato in
ReissBlog
Etichettato sotto
Martedì, 01 Settembre 2015 16:39
NEXT GENERATION MULTICAST VPN : ASPETTI GENERALI
PREMESSA
“Finita la festa, gabbato lo Santo” recita un vecchio detto. Finite le vacanze riprendo a scrivere su questo blog. Ho iniziato questa attività circa un anno fa (il primo post è datato 18 Settembre 2014) e in questo anno il blog si è arricchito di 30 post (31 con questo), ed ha avuto più di 10.000 visite totali.
Ho prodotto vari documenti che sono stati scaricati gratuitamente da centinaia di lettori, a riprova dell’interesse che questa iniziativa ha suscitato. Spero che la comunità si allarghi sempre di più e che questo blog divenga sempre più un punto d’incontro della comunità Italiana del Networking IP.
FINE DELLA PREMESSA
Con questo post voglio introdurre un argomento avanzato che ritengo di interesse. Come è noto, il servizio L3VPN (unicast) è stata la killer application che ha fatto decollare l’introduzione di MPLS nelle reti IP. Questo servizio è oggi offerto da (praticamente) tutti gli ISP mondiali, ed è anche utilizzato internamente da molte grandi reti Enterprise.
Poco più di 10 anni fa, questo servizio è stato esteso al traffico multicast, ossia alla possibilità per i Clienti VPN di veicolare traffico multicast sulla propria VPN. Si parla in questo caso di servizio MVPN (Multicast VPN).
Il primo modello di MVPN, supportato soprattutto da Cisco, ma implementato anche nei router Juniper, è il modello basato sul draft-rosen-vpn-mcast, anche noto come Draft-Rosen. Benché oggi è classificato come historical, è ancora quasi sempre quello implementato nelle applicazioni pratiche. Faccio notare però, che nonostante ciò, il Draft-Rosen non è mai diventato RFC !
L’idea alla base del modello Draft-Rosen è abbastanza intuitiva: rendere il backbone IP/MPLS, agli occhi dei router CE, simile ad una LAN. Nel paragrafo successivo ne illustrerò le idee fondamentali.
Il modello Draft-Rosen si è però dimostrato poco scalabile e soprattutto non conforme al modello generale di VPN BGP/MPLS, non utilizzando il BGP sul piano di controllo, né MPLS sul piano dati (anche se alcuni concetti del modello L3VPN unicast BGP/MPLS sono comunque utilizzati, come ad esempio il concetto di VRF). Per questo motivo è stato sviluppato un nuovo modello, denominato NG-MVPN (Next Generation-MVPN), che si integra perfettamente con il modello di L3VPN unicast BGP/MPLS. Il nuovo modello, supportato soprattutto da Juniper, ma anche da Cisco nell’IOS XR, utilizza il BGP nel piano di controllo, mentre sul piano dati può utilizzare varie alternative, tra cui la più importante è costituita da LSP MPLS Point-to-Multipoint (LSP MPLS P2MP) realizzati via mLDP (= multipoint LDP) o RSVP-TE (NOTA: affronterò in un post successivo la realizzazione di LSP MPLS P2MP).
Il modello NG-MPVN è definito dalle seguenti due RFC, entrambe pubblicate nel Febbraio 2012:
L’idea base del modello di MVPN basato sul Draft-Rosen, è quella di costruire all’interno del backbone BGP/MPLS, un albero multicast dedicato al trasporto del traffico multicast di ciascun Cliente (Multicast Distribution Tree, MDT) .
Anche i router P partecipano alla realizzazione dell’albero multicast interno, e quindi su questi router è richiesta la configurazione di protocolli di routing multicast (cosa che, si vedrà, non è necessaria nel modello NG-MVPN).
Altro aspetto fondamentale di questo modello è che il traffico multicast dei Clienti viene trasportato utilizzando Tunnel GRE, dove l’indirizzo IP destinazione è un indirizzo multicast che identifica l’albero interno.
È interessante notare che né il piano di controllo utilizza il BGP (utilizza invece un protocollo di routing multicast per costruire l’albero interno), né il piano dati utilizza MPLS.
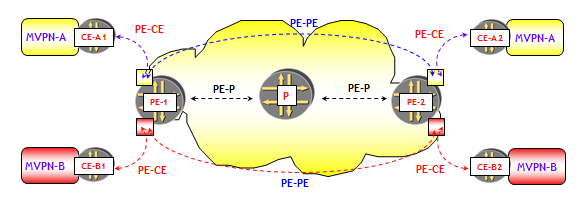
Nell’architettura del servizio MVPN basato sul modello Draft-Rosen, possono essere evidenziate diverse tipologie di adiacenze; in primo luogo, non appena viene costruita una VRF relativa ad una particolare MVPN all’interno di un router PE, questa dà origine ad una adiacenza fra lo stesso router PE ed il router CE al quale è attestato il cliente appartenente alla VPN (previa configurazione dei protocolli di routing multicast, ovviamente).
Il router PE inoltre costruisce altri due tipi di adiacenze: la prima con i router PE all’interno dei quali è stata configurata una VRF relativa alla stessa MVPN, la seconda a livello globale con gli altri router P e PE suoi vicini.
Le adiacenze costruite fra PE relativi alla stessa MVPN servono a distribuire tra i PE, le informazioni di routing multicast scambiate con i CE della stessa MVPN (ruolo che nel modello L3VPN unicast BGP/MPLS è demandato al BGP). Poiché lo scambio di queste informazioni di routing multicast tra PE è relativo a ciascuna singola MVPN, il numero delle adiacenze tra PE dipende dal numero delle MVPN configurate su quel PE. La figura seguente mostra ad esempio, che tra PE-1 e PE-2 sono stabilite due diverse adiacenze PIM, una per ciascuna MVPN.
Si noti che ciò è profondamente diverso (e meno scalabile !) da quanto avviene nel modello L3VPN unicast BGP/MPLS, dove tra PE, per lo scambio delle informazioni di routing di tutte le MVPN, viene utilizzata una singola sessione BGP.
Le adiacenze PIM costruite fra i router PE e i router P (e tra i router P) sono invece utilizzate per realizzare la costruzione dei Multicast Distribution Tree (MDT) che collegano le varie VRF di ciascuna MVPN. Si noti che è necessario un MDT per ciascuna MVPN, anche se l’istanza PIM utilizzata per la costruzione degli MDT è unica (in altre parole, gli stati (*, G) e (S, G) degli MDT, utilizzano tutti la tabella di routing multicast globale).
Il modello su cui si basa la rete di un ISP che offre servizi MVPN è simile a quello presente nelle L3VPN BGP/MPLS unicast :
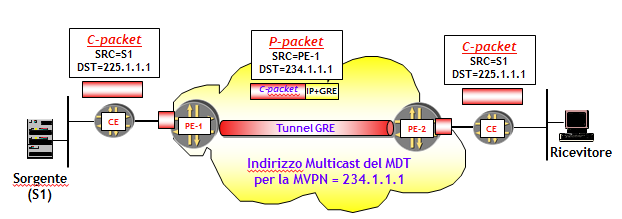
I pacchetti multicast generati dai router CE (C-packet) sono trasportati all’interno della rete dell’ISP utilizzando Tunnel GRE. L’intestazione IP dei pacchetti inseriti nei Tunnel GRE (P-Packet), ha come indirizzo IP destinazione l’indirizzo del gruppo multicast che l’ISP ha assegnato alla MVPN, e indirizzo IP sorgente l’indirizzo di una interfaccia (tipicamente di Loopback) del PE che inserisce il pacchetto nel Tunnel.
I LIMITI DEL MODELLO DRAFT-ROSEN
Il modello Draft-Rosen ha varie limitazioni, che hanno portato IETF a definire un nuovo modello di MVPN:
NOTA (CULTURALE): il modello Virtual Router, definito nella RFC 4110 - A Framework for Layer 3 Provider-Provisioned Virtual Private Networks (PPVPNs), Luglio 2005, prevede che lo scambio di informazioni di routing tra PE avvenga realizzando istanze separate di routing, una per ciascuna VPN. Inoltre, lo scambio di traffico dati tra PE avviene realizzando tunnel separati per ciascuna VPN, dove logicamente questi tunnel sono tra VRF della stessa istanza VPN. I tunnel vengono utilizzati come fossero normali link tra router (virtuali), e quindi trasportano anche le informazioni del piano di controllo, creando un forte accoppiamento tra piano dati e piano di controllo.
Il Draft-Rosen si basa proprio un modello di tipo Virtual Router, poiché una data VRF su un dato PE, deve mantenere adiacenze PIM con ogni altra VRF appartenente a quella MVPN su ogni altro PE. Inoltre, queste adiacenze devono essere mantenute non per PE, ma per MVPN. Un PE inoltre deve anche mantenere adiacenze PIM con tutti i CE collegati localmente.
Fino a che il numero medio di siti MVPN collegati ad un dato PE è inferiore rispetto al numero medio di PE che hanno siti di tale MVPN, per un dato PE il sovraccarico di mantenere adiacenze PIM con altri PE dominerà il sovraccarico di adiacenze PIM PE-CE. Si noti che questo sovraccarico cresce con il numero di PE di una istanza MVPN, nonché con il numero di MVPN. Ad esempio, consideriamo il caso di un PE con 1.000 VRF, e ciascuna di queste VRF corrisponda a una MVPN che in media è presente su 100 PE. Il numero medio di adiacenze PIM PE-PE che il PE dovrebbe mantenere è 100.000 e, considerando il periodo di default dei messaggi PIM Hello (= 30 sec), il numero medio di PIM Hello che il PE dovrebbe elaborare è 3.300 al secondo.
IL NUOVO MODELLO NG-MVPN
Per ovviare agli inconvenienti del modello Draft-Rosen, in particolare alla sua scarsa scalabilità, IETF ha definito un nuovo modello di MVPN (Next Generation-MVPN, NG-MVPN), che include comunque come caso particolare, il modello Draft-Rosen. Il nuovo modello si basa sui seguenti principi:
NOTA (CULTURALE): facendo un paragone con il modello Draft-Rosen, mentre questo, come detto nel paragragfo precedente, utilizza un modello Virtual Router, NG-MVPN utilizza un modello Aggregated Router (sempre secondo la definizione della già citata RFC 4110).
Il modello Aggregated Router utilizza, per lo scambio delle informazioni di routing VPN, una singola istanza di un protocollo di routing (che nel modello NG-MVPN è il MP-iBGP). Le informazioni di routing di più VPN sono quindi «aggregate» e trasportate dalla medesima istanza di routing (il processo MP-iBGP).
Come nel modello Virtual Router, anche il modello Aggregated Router trasporta il traffico dati su tunnel separati per ciascuna VPN. Ma a differenza del modello Virtual Router, il modello Aggregated Router utilizza questi tunnel esclusivamente per il trasporto dei dati e non delle informazioni del piano di controllo. Il risultato è una netta separazione del piano di controllo dal piano dati. Questo aspetto facilita l’utilizzo di diverse tecniche sul piano dati, cosa che non avviene ad esempio nel modello Draft-Rosen, che basandosi sul modello Virtual Router ha bisogno di un protocollo sul piano dati in grado di trasportare anche informazioni di routing, come ad esempio i tunnel GRE.
NG-MVPN: IL PIANO DI CONTROLLO
Nelle L3VPN unicast, le informazioni di routing dei siti VPN, costituite dai prefissi IP locali dei siti, vengono propagate:
Si potrebbe pensare a questo approccio come a un modo di redistribuire informazioni di routing da un protocollo (PIM) ad un altro (BGP). Il concetto di redistribuzione è ben noto in un ambiente unicast, dove ad esempio è possibile redistribuire route apprese via OSPF in BGP. Quello che accade nel modello NG-MVPN è una estensione di questo concetto alle route multicast, che apprese via PIM dai router CE, vengono propagate via MP-iBGP e quindi ripropagate da MP-iBGP in PIM: una sorta di redistribuzione PIM →BGP →PIM.
La figura seguente riporta schematicamente la logica del piano di controllo.
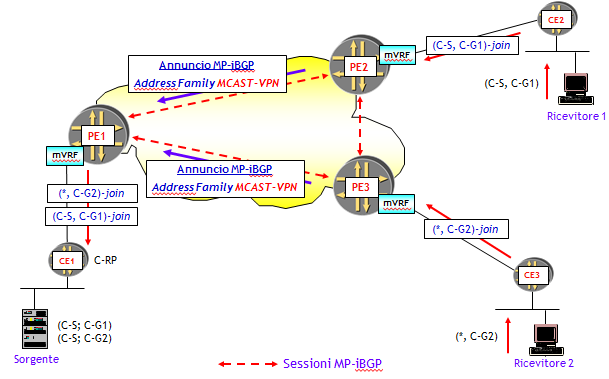
Le informazioni di routing multicast, ossia, le C-multicast route, vengono propagate da CE a PE attraverso il protocollo PIM. Il trasporto all’interno della rete del Service Provider avviene "codificando" in modo opportuno le informazioni di routing multicast in annunci MP-iBGP. A destinazione, il router PE "decodifica" gli annunci BGP e quindi invia i messaggi PIM al CE di destinazione. Si noti che i router CE sono completamente ignari del meccanismo utilizzato dai PE per propagare le C-multicast route. Dal loro punto di vista, può essere utilizzato qualsiasi protocollo. Questa è comunque una caratteristica di tutti i servizi VPN basati sul modello BGP/MPLS.
L’aspetto chiave del piano di controllo è la definizione di come le C-multicast route apprese dai PE via PIM, vengono "codificate" in annunci BGP. Questo è un aspetto molto complesso, di cui darò solo qualche cenno.
La maggiore novità (non l'unica) del modello NG-MVPN è quindi che il piano di controllo, così come avviene per i servizi L3VPN unicast, è basato sul BGP. In particolare, è necessaria una maglia completa di sessioni MP-iBGP tra i router PE, che può essere realizzata per maggiore scalabilità, utilizzando dei Route Reflector.
Per lo scambio delle informazioni di routing (multicast) necessarie al funzionamento del modello NG-MVPN, è stata definita una nuova famiglia di indirizzi e un associato codice SAFI = 5 (Address Family MCAST-VPN). Il codice AFI è come sempre 1 per la famiglia di indirizzi IPv4 e 2 per la famiglia di indirizzi IPv6.
Per il funzionamento del modello sono stati definiti 7 nuovi tipi di NLRI, il cui formato generale è riportato nella figura seguente (codifica TLV).

Sul significato e sull’utilizzo dei vari tipi di NLRI sono costretto a “glissare”, data la loro complessità. In questo post voglio solo esporre le idee di fondo, magari in post successivi darò qualche dettaglio in più.
Il piano di controllo di un modello per la realizzazione di MVPN assolve tre funzioni importanti:
NG-MVPN: IL PIANO DATI
Un altro aspetto dove il modello NG-MVPN si differenzia totalmente dal modello Draft-Rosen, è il piano dati, ossia le modalità con cui i pacchetti multicast sono trasportati all’interno della rete del Service Provider.
Il modello NG-MVPN prevede varie modalità di trasporto, tra cui come caso particolare anche i tunnel GRE segnalati via PIM (SM/SSM/BiDir), utilizzati nel modello Draft-Rosen. Ma il modello NG-MVPN prevede anche l’utilizzo di MPLS, attraverso la realizzazione di LSP MPLS di tipo Point-to-Multipoint (LSP P2MP). Questi LSP possono essere realizzati attraverso una estensione del protocollo RSVP-TE utilizzato per i LSP MPLS Point-to-Point (P2P), oppure attraverso una estensione del protocollo LDP, detta multipoint LDP (mLDP). In realtà, per emulare una modalità tipo PIM BiDir, è previsto anche l’utilizzo di LSP MPLS Multipoint-to-Multipoint (LSP MP2MP), realizzabili però solo attraverso mLDP.
Il punto chiave è che il piano di controllo e piano dati sono completamente disaccoppiati. Questo implica che una volta noti i PE che partecipano alla stessa istanza NG-MVPN, noti i PE dove sono connesse (attraverso i CE) le sorgenti di traffico e noti i PE dove sono connessi (sempre attraverso i CE) i ricevitori, il trasporto del traffico multicast può essere realizzato con una qualsiasi tecnica, realizzando alberi di distribuzione multicast all’interno della rete del Service Provider (Default-MDT e Data-MDT).
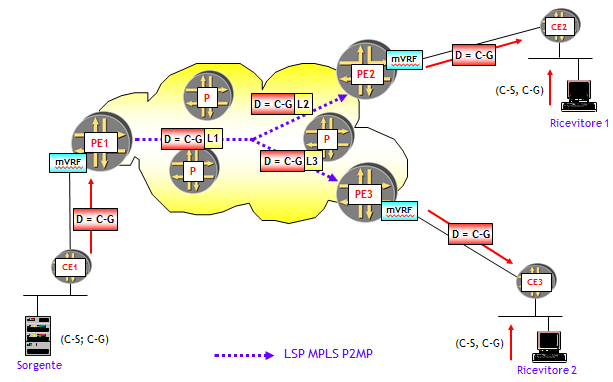
La tendenza attuale, per motivi di scalabilità e compatibilità con il modello BGP/MPLS, è quella di utilizzare LSP MPLS P2MP, realizzati via RSVP-TE o mLDP. La figura seguente ne riporta l’idea base.
La RFC 6514 prevede 7 modalità di trasporto. La modalità utilizzata viene segnalata sul piano di controllo, attraverso il nuovo attributo BGP "PMSI Tunnel", che viene associato agli annunci MCAST-VPN con NLRI di tipo 1, 2 e 3. La figura seguente ne riporta il formato.
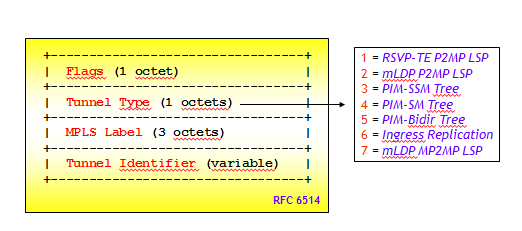
Il tipo di P-tunnel per il trasporto del traffico C-multicast e la modalità di segnalazione sono specificati nel campo Tunnel Type. I valori utilizzati sono riportati nella figura e ufficializzati nella RFC 7385, IANA Registry for P-Multicast Service Interface (PMSI) Tunnel Type Code Points, Ottobre 2014. Il P-tunnel più utilizzato nelle applicazioni pratiche è costituito da LSP MPLS P2MP segnalati attraverso RSVP-TE o mLDP (estensione multipoint di LDP). Il Draft-Rosen utilizza Tunnel Type di tipo 3, 4 o 5.
CONSIDERAZIONI FINALI
In questo post ho introdotto il nuovo modello NG-MVPN per la realizzazione di servizi L3VPN multicast. Il modello è supportato sia nelle piattaforme Cisco che Juniper. Benché ancora poco noto, il modello NG-MVPN è già stato implementato con successo in Italia da un grande provider di servizi di comunicazione via satellite.
Il funzionamento è molto complesso e, parodiando il celebre magistrato-matematico Pierre de Fermat “dispongo di una ampia presentazione che però non entra nello spazio concesso a questo blog”. Però magari in futuro qualche dettaglio in più cercherò di darlo.
Comunque, se volete saperne di più, ho inserito nel nostro catalogo di corsi tecnici, un corso ad hoc di due giorni sull’argomento (IPN269, Next Generation Multicast VPN), dove tutto viene trattato con dovizia di particolari e dove sono previste esercitazioni con piattaforme Juniper.
“Finita la festa, gabbato lo Santo” recita un vecchio detto. Finite le vacanze riprendo a scrivere su questo blog. Ho iniziato questa attività circa un anno fa (il primo post è datato 18 Settembre 2014) e in questo anno il blog si è arricchito di 30 post (31 con questo), ed ha avuto più di 10.000 visite totali.
Ho prodotto vari documenti che sono stati scaricati gratuitamente da centinaia di lettori, a riprova dell’interesse che questa iniziativa ha suscitato. Spero che la comunità si allarghi sempre di più e che questo blog divenga sempre più un punto d’incontro della comunità Italiana del Networking IP.
FINE DELLA PREMESSA
Con questo post voglio introdurre un argomento avanzato che ritengo di interesse. Come è noto, il servizio L3VPN (unicast) è stata la killer application che ha fatto decollare l’introduzione di MPLS nelle reti IP. Questo servizio è oggi offerto da (praticamente) tutti gli ISP mondiali, ed è anche utilizzato internamente da molte grandi reti Enterprise.
Poco più di 10 anni fa, questo servizio è stato esteso al traffico multicast, ossia alla possibilità per i Clienti VPN di veicolare traffico multicast sulla propria VPN. Si parla in questo caso di servizio MVPN (Multicast VPN).
Il primo modello di MVPN, supportato soprattutto da Cisco, ma implementato anche nei router Juniper, è il modello basato sul draft-rosen-vpn-mcast, anche noto come Draft-Rosen. Benché oggi è classificato come historical, è ancora quasi sempre quello implementato nelle applicazioni pratiche. Faccio notare però, che nonostante ciò, il Draft-Rosen non è mai diventato RFC !
L’idea alla base del modello Draft-Rosen è abbastanza intuitiva: rendere il backbone IP/MPLS, agli occhi dei router CE, simile ad una LAN. Nel paragrafo successivo ne illustrerò le idee fondamentali.
Il modello Draft-Rosen si è però dimostrato poco scalabile e soprattutto non conforme al modello generale di VPN BGP/MPLS, non utilizzando il BGP sul piano di controllo, né MPLS sul piano dati (anche se alcuni concetti del modello L3VPN unicast BGP/MPLS sono comunque utilizzati, come ad esempio il concetto di VRF). Per questo motivo è stato sviluppato un nuovo modello, denominato NG-MVPN (Next Generation-MVPN), che si integra perfettamente con il modello di L3VPN unicast BGP/MPLS. Il nuovo modello, supportato soprattutto da Juniper, ma anche da Cisco nell’IOS XR, utilizza il BGP nel piano di controllo, mentre sul piano dati può utilizzare varie alternative, tra cui la più importante è costituita da LSP MPLS Point-to-Multipoint (LSP MPLS P2MP) realizzati via mLDP (= multipoint LDP) o RSVP-TE (NOTA: affronterò in un post successivo la realizzazione di LSP MPLS P2MP).
Il modello NG-MPVN è definito dalle seguenti due RFC, entrambe pubblicate nel Febbraio 2012:
- RFC 6513 : Multicast in MPLS/BGP IP VPNs.
- RFC 6514 : BGP Encodings and Procedures for Multicast in MPLS/BGP IP VPNs.
L’idea base del modello di MVPN basato sul Draft-Rosen, è quella di costruire all’interno del backbone BGP/MPLS, un albero multicast dedicato al trasporto del traffico multicast di ciascun Cliente (Multicast Distribution Tree, MDT) .
Anche i router P partecipano alla realizzazione dell’albero multicast interno, e quindi su questi router è richiesta la configurazione di protocolli di routing multicast (cosa che, si vedrà, non è necessaria nel modello NG-MVPN).
Altro aspetto fondamentale di questo modello è che il traffico multicast dei Clienti viene trasportato utilizzando Tunnel GRE, dove l’indirizzo IP destinazione è un indirizzo multicast che identifica l’albero interno.
È interessante notare che né il piano di controllo utilizza il BGP (utilizza invece un protocollo di routing multicast per costruire l’albero interno), né il piano dati utilizza MPLS.
Nell’architettura del servizio MVPN basato sul modello Draft-Rosen, possono essere evidenziate diverse tipologie di adiacenze; in primo luogo, non appena viene costruita una VRF relativa ad una particolare MVPN all’interno di un router PE, questa dà origine ad una adiacenza fra lo stesso router PE ed il router CE al quale è attestato il cliente appartenente alla VPN (previa configurazione dei protocolli di routing multicast, ovviamente).
Il router PE inoltre costruisce altri due tipi di adiacenze: la prima con i router PE all’interno dei quali è stata configurata una VRF relativa alla stessa MVPN, la seconda a livello globale con gli altri router P e PE suoi vicini.
Le adiacenze costruite fra PE relativi alla stessa MVPN servono a distribuire tra i PE, le informazioni di routing multicast scambiate con i CE della stessa MVPN (ruolo che nel modello L3VPN unicast BGP/MPLS è demandato al BGP). Poiché lo scambio di queste informazioni di routing multicast tra PE è relativo a ciascuna singola MVPN, il numero delle adiacenze tra PE dipende dal numero delle MVPN configurate su quel PE. La figura seguente mostra ad esempio, che tra PE-1 e PE-2 sono stabilite due diverse adiacenze PIM, una per ciascuna MVPN.
Si noti che ciò è profondamente diverso (e meno scalabile !) da quanto avviene nel modello L3VPN unicast BGP/MPLS, dove tra PE, per lo scambio delle informazioni di routing di tutte le MVPN, viene utilizzata una singola sessione BGP.
Le adiacenze PIM costruite fra i router PE e i router P (e tra i router P) sono invece utilizzate per realizzare la costruzione dei Multicast Distribution Tree (MDT) che collegano le varie VRF di ciascuna MVPN. Si noti che è necessario un MDT per ciascuna MVPN, anche se l’istanza PIM utilizzata per la costruzione degli MDT è unica (in altre parole, gli stati (*, G) e (S, G) degli MDT, utilizzano tutti la tabella di routing multicast globale).
Il modello su cui si basa la rete di un ISP che offre servizi MVPN è simile a quello presente nelle L3VPN BGP/MPLS unicast :
- I router P contengono informazioni a livello di routing globale e non sono informati circa le sorgenti e i ricevitori appartenenti alle varie VPN, né tantomeno degli alberi multicast ad essi relativi.
- I router CE hanno adiacenze del protocollo di routing multicast solo con i router PE ai quali sono attestati, e possono scambiare informazioni di routing multicast, pur non avendone conoscenza, con gli altri router CE appartenenti alla stessa MVPN. Le informazioni di routing multicast sono trasportate dal Multicast Distribution Tree.
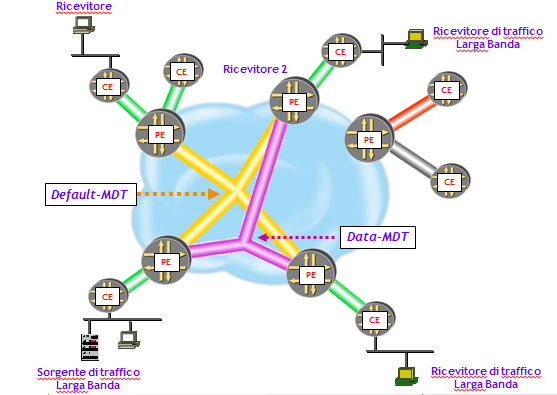
- Default-MDT: è l’albero iniziale creato per ciascuna MVPN; serve a trasportare i messaggi del protocollo di routing multicast (PIM) e dati a bassa velocità. È un albero di tipo “inclusivo”, nel senso che congiunge tutti i PE dove sono configurate mVRF della stessa istanza MVPN.
- Data-MDT: è un albero ottimizzato che entra in funzione solo nei casi in cui qualche sorgente superi una soglia configurata di banda, oltre la quale il traffico multicast viene trasportato sul Data-MDT. È un albero di tipo “selettivo”, nel senso che congiunge tutti i PE dove sono configurate mVRF della stessa istanza MVPN, dove però sono attestati le sorgenti e i ricevitori di traffico multicast della MVPN.
I pacchetti multicast generati dai router CE (C-packet) sono trasportati all’interno della rete dell’ISP utilizzando Tunnel GRE. L’intestazione IP dei pacchetti inseriti nei Tunnel GRE (P-Packet), ha come indirizzo IP destinazione l’indirizzo del gruppo multicast che l’ISP ha assegnato alla MVPN, e indirizzo IP sorgente l’indirizzo di una interfaccia (tipicamente di Loopback) del PE che inserisce il pacchetto nel Tunnel.
I LIMITI DEL MODELLO DRAFT-ROSEN
Il modello Draft-Rosen ha varie limitazioni, che hanno portato IETF a definire un nuovo modello di MVPN:
- Scarsa compatibilità con il modello di VPN IP BGP/MPLS (es. segnalazione basata su PIM e non su BGP, trasporto basato su Tunnel GRE piuttosto che su MPLS, ecc.) .
- Scalabilità del piano di controllo (necessità di mantenere sui PE un elevato numero di adiacenze PIM). Questo perché il modello draft-Rosen utilizza un modello di tipo Virtual Router (vedi nota sotto).
- Necessità di estendere il protocollo PIM anche ai router P, per realizzare gli alberi Default-MDT e Data-MDT. Questo ha come conseguenza che i router P devono mantenere uno stato per-MVPN. Per contro nel modello L3VPN unicast i router P non hanno alcuno stato riguardante le singole VPN. Inoltre, ulteriore conseguenza è che è necessario definire manualmente un indirizzo multicast per MVPN per realizzare l’albero MDT, aumentando le complessità di configurazione.
- Elevato ritardo nella diffusione dei messaggi Join/Prune.
NOTA (CULTURALE): il modello Virtual Router, definito nella RFC 4110 - A Framework for Layer 3 Provider-Provisioned Virtual Private Networks (PPVPNs), Luglio 2005, prevede che lo scambio di informazioni di routing tra PE avvenga realizzando istanze separate di routing, una per ciascuna VPN. Inoltre, lo scambio di traffico dati tra PE avviene realizzando tunnel separati per ciascuna VPN, dove logicamente questi tunnel sono tra VRF della stessa istanza VPN. I tunnel vengono utilizzati come fossero normali link tra router (virtuali), e quindi trasportano anche le informazioni del piano di controllo, creando un forte accoppiamento tra piano dati e piano di controllo.
Il Draft-Rosen si basa proprio un modello di tipo Virtual Router, poiché una data VRF su un dato PE, deve mantenere adiacenze PIM con ogni altra VRF appartenente a quella MVPN su ogni altro PE. Inoltre, queste adiacenze devono essere mantenute non per PE, ma per MVPN. Un PE inoltre deve anche mantenere adiacenze PIM con tutti i CE collegati localmente.
Fino a che il numero medio di siti MVPN collegati ad un dato PE è inferiore rispetto al numero medio di PE che hanno siti di tale MVPN, per un dato PE il sovraccarico di mantenere adiacenze PIM con altri PE dominerà il sovraccarico di adiacenze PIM PE-CE. Si noti che questo sovraccarico cresce con il numero di PE di una istanza MVPN, nonché con il numero di MVPN. Ad esempio, consideriamo il caso di un PE con 1.000 VRF, e ciascuna di queste VRF corrisponda a una MVPN che in media è presente su 100 PE. Il numero medio di adiacenze PIM PE-PE che il PE dovrebbe mantenere è 100.000 e, considerando il periodo di default dei messaggi PIM Hello (= 30 sec), il numero medio di PIM Hello che il PE dovrebbe elaborare è 3.300 al secondo.
IL NUOVO MODELLO NG-MVPN
Per ovviare agli inconvenienti del modello Draft-Rosen, in particolare alla sua scarsa scalabilità, IETF ha definito un nuovo modello di MVPN (Next Generation-MVPN, NG-MVPN), che include comunque come caso particolare, il modello Draft-Rosen. Il nuovo modello si basa sui seguenti principi:
- Segnalazione via BGP (più precisamente attraverso sessioni MP-iBGP).
- Possibilità di trasporto del traffico multicast via MPLS.
- Maggiore integrazione con il modello di VPN IP BGP/MPLS unicast.
NOTA (CULTURALE): facendo un paragone con il modello Draft-Rosen, mentre questo, come detto nel paragragfo precedente, utilizza un modello Virtual Router, NG-MVPN utilizza un modello Aggregated Router (sempre secondo la definizione della già citata RFC 4110).
Il modello Aggregated Router utilizza, per lo scambio delle informazioni di routing VPN, una singola istanza di un protocollo di routing (che nel modello NG-MVPN è il MP-iBGP). Le informazioni di routing di più VPN sono quindi «aggregate» e trasportate dalla medesima istanza di routing (il processo MP-iBGP).
Come nel modello Virtual Router, anche il modello Aggregated Router trasporta il traffico dati su tunnel separati per ciascuna VPN. Ma a differenza del modello Virtual Router, il modello Aggregated Router utilizza questi tunnel esclusivamente per il trasporto dei dati e non delle informazioni del piano di controllo. Il risultato è una netta separazione del piano di controllo dal piano dati. Questo aspetto facilita l’utilizzo di diverse tecniche sul piano dati, cosa che non avviene ad esempio nel modello Draft-Rosen, che basandosi sul modello Virtual Router ha bisogno di un protocollo sul piano dati in grado di trasportare anche informazioni di routing, come ad esempio i tunnel GRE.
NG-MVPN: IL PIANO DI CONTROLLO
Nelle L3VPN unicast, le informazioni di routing dei siti VPN, costituite dai prefissi IP locali dei siti, vengono propagate:
- Localmente da CE a PE attraverso un qualsiasi protocollo di routing PE-CE (statico, dinamico).
- Tra i PE della rete del Service Provider, attraverso sessioni MP-iBGP, dove il NLRI è costituito da un prefisso IP, con anteposto il Route Distinguisher.
Si potrebbe pensare a questo approccio come a un modo di redistribuire informazioni di routing da un protocollo (PIM) ad un altro (BGP). Il concetto di redistribuzione è ben noto in un ambiente unicast, dove ad esempio è possibile redistribuire route apprese via OSPF in BGP. Quello che accade nel modello NG-MVPN è una estensione di questo concetto alle route multicast, che apprese via PIM dai router CE, vengono propagate via MP-iBGP e quindi ripropagate da MP-iBGP in PIM: una sorta di redistribuzione PIM →BGP →PIM.
La figura seguente riporta schematicamente la logica del piano di controllo.
Le informazioni di routing multicast, ossia, le C-multicast route, vengono propagate da CE a PE attraverso il protocollo PIM. Il trasporto all’interno della rete del Service Provider avviene "codificando" in modo opportuno le informazioni di routing multicast in annunci MP-iBGP. A destinazione, il router PE "decodifica" gli annunci BGP e quindi invia i messaggi PIM al CE di destinazione. Si noti che i router CE sono completamente ignari del meccanismo utilizzato dai PE per propagare le C-multicast route. Dal loro punto di vista, può essere utilizzato qualsiasi protocollo. Questa è comunque una caratteristica di tutti i servizi VPN basati sul modello BGP/MPLS.
L’aspetto chiave del piano di controllo è la definizione di come le C-multicast route apprese dai PE via PIM, vengono "codificate" in annunci BGP. Questo è un aspetto molto complesso, di cui darò solo qualche cenno.
La maggiore novità (non l'unica) del modello NG-MVPN è quindi che il piano di controllo, così come avviene per i servizi L3VPN unicast, è basato sul BGP. In particolare, è necessaria una maglia completa di sessioni MP-iBGP tra i router PE, che può essere realizzata per maggiore scalabilità, utilizzando dei Route Reflector.
Per lo scambio delle informazioni di routing (multicast) necessarie al funzionamento del modello NG-MVPN, è stata definita una nuova famiglia di indirizzi e un associato codice SAFI = 5 (Address Family MCAST-VPN). Il codice AFI è come sempre 1 per la famiglia di indirizzi IPv4 e 2 per la famiglia di indirizzi IPv6.
Per il funzionamento del modello sono stati definiti 7 nuovi tipi di NLRI, il cui formato generale è riportato nella figura seguente (codifica TLV).
Sul significato e sull’utilizzo dei vari tipi di NLRI sono costretto a “glissare”, data la loro complessità. In questo post voglio solo esporre le idee di fondo, magari in post successivi darò qualche dettaglio in più.
Il piano di controllo di un modello per la realizzazione di MVPN assolve tre funzioni importanti:
- Auto-Discovery: nelle L3VPN unicast non vi è bisogno di alcun meccanismo di Auto-Discovery: un PE apprende dell’esistenza di un sito remoto quando riceve dal PE dove è attestato il sito remoto, annunci MP-iBGP di reti presenti nel sito. Le MVPN per contro, hanno bisogno di conoscere in anticipo la localizzazione di sorgenti e ricevitori di traffico C-multicast.
- Segnalazione dei messaggi PIM join/prune tra siti MVPN: il modello NG-MVPN utilizza sessioni MP-iBGP. Per contro, nel modello Draft-Rosen vengono utilizzate adiacenze PIM tra PE.
- Segnalazione dei P-tunnel (NOTA: i P-tunnel (Provider-tunnel) sono i tunnel utilizzati nella rete dell’ISP per trasportare il traffico multicast dei Clienti MVPN): il modello NG-MVPN, supporta vari tipi di P-tunnel, di cui alcuni basati su MPLS. Questa è la scelta considerata migliore a causa delle ricche funzionalità supportate da MPLS (traffic engineering, fast rerouting, supporto della QoS, ecc.). Il modello prevede comunque la possibilità di utilizzare P-tunnel basati sul protocollo PIM, come nel Draft-Rosen. Questo è possibile perché nel modello NG-MVPN vi è un totale disaccoppiamento tra piano di controllo e piano dati (ricordo che NG-MVPN utilizza un modello di tipo aggregated router).
NG-MVPN: IL PIANO DATI
Un altro aspetto dove il modello NG-MVPN si differenzia totalmente dal modello Draft-Rosen, è il piano dati, ossia le modalità con cui i pacchetti multicast sono trasportati all’interno della rete del Service Provider.
Il modello NG-MVPN prevede varie modalità di trasporto, tra cui come caso particolare anche i tunnel GRE segnalati via PIM (SM/SSM/BiDir), utilizzati nel modello Draft-Rosen. Ma il modello NG-MVPN prevede anche l’utilizzo di MPLS, attraverso la realizzazione di LSP MPLS di tipo Point-to-Multipoint (LSP P2MP). Questi LSP possono essere realizzati attraverso una estensione del protocollo RSVP-TE utilizzato per i LSP MPLS Point-to-Point (P2P), oppure attraverso una estensione del protocollo LDP, detta multipoint LDP (mLDP). In realtà, per emulare una modalità tipo PIM BiDir, è previsto anche l’utilizzo di LSP MPLS Multipoint-to-Multipoint (LSP MP2MP), realizzabili però solo attraverso mLDP.
Il punto chiave è che il piano di controllo e piano dati sono completamente disaccoppiati. Questo implica che una volta noti i PE che partecipano alla stessa istanza NG-MVPN, noti i PE dove sono connesse (attraverso i CE) le sorgenti di traffico e noti i PE dove sono connessi (sempre attraverso i CE) i ricevitori, il trasporto del traffico multicast può essere realizzato con una qualsiasi tecnica, realizzando alberi di distribuzione multicast all’interno della rete del Service Provider (Default-MDT e Data-MDT).
La tendenza attuale, per motivi di scalabilità e compatibilità con il modello BGP/MPLS, è quella di utilizzare LSP MPLS P2MP, realizzati via RSVP-TE o mLDP. La figura seguente ne riporta l’idea base.
La RFC 6514 prevede 7 modalità di trasporto. La modalità utilizzata viene segnalata sul piano di controllo, attraverso il nuovo attributo BGP "PMSI Tunnel", che viene associato agli annunci MCAST-VPN con NLRI di tipo 1, 2 e 3. La figura seguente ne riporta il formato.
Il tipo di P-tunnel per il trasporto del traffico C-multicast e la modalità di segnalazione sono specificati nel campo Tunnel Type. I valori utilizzati sono riportati nella figura e ufficializzati nella RFC 7385, IANA Registry for P-Multicast Service Interface (PMSI) Tunnel Type Code Points, Ottobre 2014. Il P-tunnel più utilizzato nelle applicazioni pratiche è costituito da LSP MPLS P2MP segnalati attraverso RSVP-TE o mLDP (estensione multipoint di LDP). Il Draft-Rosen utilizza Tunnel Type di tipo 3, 4 o 5.
CONSIDERAZIONI FINALI
In questo post ho introdotto il nuovo modello NG-MVPN per la realizzazione di servizi L3VPN multicast. Il modello è supportato sia nelle piattaforme Cisco che Juniper. Benché ancora poco noto, il modello NG-MVPN è già stato implementato con successo in Italia da un grande provider di servizi di comunicazione via satellite.
Il funzionamento è molto complesso e, parodiando il celebre magistrato-matematico Pierre de Fermat “dispongo di una ampia presentazione che però non entra nello spazio concesso a questo blog”. Però magari in futuro qualche dettaglio in più cercherò di darlo.
Comunque, se volete saperne di più, ho inserito nel nostro catalogo di corsi tecnici, un corso ad hoc di due giorni sull’argomento (IPN269, Next Generation Multicast VPN), dove tutto viene trattato con dovizia di particolari e dove sono previste esercitazioni con piattaforme Juniper.
Pubblicato in
ReissBlog
Etichettato sotto
Venerdì, 26 Giugno 2015 15:37
DOCUMENTO RIASSUNTIVO SULLA CONVERGENZA BGP E ... ARRIVEDERCI A SETTEMBRE
Ho raccolto in un documento di più di 70 pagine il contenuto dei miei post precedenti sulla Convergenza del BGP. Ho inserito qualche dettaglio in più e, per completezza, una Appendice che tratta di aspetti già noti.
Può esservi utile per la vostra biblioteca tecnica.
Potete scaricare il documento a questo link.
Buona lettura !!!
Con questo mini-post, concludo il primo ciclo del blog. E' ora di prendersi una pausa. Nei mesi di Luglio e Agosto non pubblicherò ulteriore materiale, per cui auguro a tutti i lettori Buone Vacanze, e arrivederci a Settembre.
Pubblicato in
ReissBlog
Etichettato sotto
Lunedì, 08 Giugno 2015 05:24
CONVERGENZA DEI PROTOCOLLI LINK-STATE: SPF PER-PREFIX PRIORITIZATION
Quando un processo di routing Link-State in un router deve determinare, attraverso l’algoritmo SPF, nuovi percorsi ottimi, lo fa per ciascun prefisso che gli è stato annunciato. Il problema che sorge a questo punto è: da quale prefisso iniziare il ricalcolo del percorso ottimo ? Perché non tutti i prefissi hanno la stessa importanza. Ad esempio, un prefisso che contiene l’indirizzo IP della sorgente di un servizio multicast basato su PIM SSM (PIM Source Specific Multicast), ha sicuramente maggiore importanza di una subnet con cui si numera un collegamento punto-punto. Questo perché, più tempo è assente dalla tabella di routing un percorso verso la sorgente, più pacchetti multicast vengono scartati a causa del controllo RPF (Reverse Path Forwarding), causando così un disservizio agli utilizzatori. Allo stesso modo, un prefisso /32 di un router PE utilizzato per stabilire sessioni iBGP, è più importante di altri prefissi.
Nei router Cisco e Juniper è stato introdotta una opzione, nota come spf per-prefix prioritization, che consente, nel ricalcolo dei percorsi ottimi, di dare precedenza ai prefissi più importanti rispetto a quelli meno importanti. Il risultato finale è che i prefissi più importanti finiscono nella RIB e quindi nella FIB prima dei prefissi meno importanti, velocizzando così la convergenza per i prefissi più importanti.
IMPLEMENTAZIONE NEI ROUTER CISCO
I router Cisco supportano la funzionalità spf per-prefix prioritization, in tutte le varie versioni dell’IOS, con qualche piccola differenza nei default e nello stile di configurazione. In questo post tratterò l'argomento solo per quanto riguarda OSPF. L'analogo per IS-IS è trattato nel Capitolo 10 del libro "IS-IS: dalla teoria alla pratica", in download gratuito fra qualche mese su questo blog.
Mentre l'opzione spf per-prefix prioritization per IS-IS è supportata nell’IOS, IOS XE, e IOS XR, la stessa funzionalità per OSPF è supportata solo nell'IOS XR, dove di default è disabilitata. In questo caso, i prefissi /32 vengono trattati con priorità assoluta. Nel caso in cui l'opzione venisse abilitata, i prefissi /32 non verrebbero trattati con priorità assoluta, ma vanno assegnati a una classe di priorità.
La configurazione nell’IOS XR utilizza una route-policy, che a sua volta fa riferimento a dei prefix-set, attraverso i quali si assegnano i prefissi a 4 possibili classi di priorità: critical, high, medium, low. In realtà, l’assegnazione manuale avviene solo alle prime tre classi, alla classe low vengono assegnati tutti i prefissi non assegnati manualmente alle altre tre classi.
Il comando IOS XR che consente l’assegnazione a una particolare classe è il seguente:
RP/0/RP0/CPU0:router(config)# router ospf process-ID
RP/0/RP0/CPU0:router(config-ospf)# spf prefix-priority route-policy nome-RP
Ad esempio, supponendo di voler assegnare tutti i prefissi /32 alla classe critical, tutti i prefissi /30 e /31 alla classe high, tutti i prefissi /29 alla classe medium e i rimanenti alla classe low, la configurazione da eseguire è la seguente:
prefix-set OSPF-CRITICAL
0.0.0.0/0 eq 32
end-set
!
prefix-set OSPF-HIGH
0.0.0.0/0 ge 30 le 31
end-set
!
prefix-set OSPF-MED
0.0.0.0/0 eq 29
end-set
!
route-policy OSPF-SPF-PRIORITY
if destination in OSPF-CRITICAL then
set spf-priority critical
endif
if destination in OSPF-HIGH then
set spf-priority high
endif
if destination in OSPF-MED then
set spf-priority medium
endif
end-policy
!
router ospf 1
spf prefix-priority route-policy OSPF-SPF-PRIORITY
IMPLEMENTAZIONE NEI ROUTER JUNIPER
Nei router Juniper che adottano il JUNOS, l'opzione spf per-prefix prioritization è supportata solo per OSPF. La configurazione utilizza una routing policy, da applicare al processo OSPF nella direzione import. La routing policy a sua volta fa riferimento a dei route-filter, attraverso i quali si assegnano i prefissi a 3 possibili classi di priorità: high, medium, low.
Come esempio, illustrerò come implementare una politica di priorità analoga a quella vista sopra per l'IOS XR. In particolare, tutti i prefissi /32 sono assegnati alla classe high, tutti i prefissi /30 e /31 alla classe medium, tutti gli altri prefissi alla classe low. La configurazione da eseguire è la seguente:
tt@router# show policy-options policy-statement OSPF-SPF-PRIORITY
term LOW {
from {
route-filter 0.0.0.0/0 upto /29;
}
then {
priority low;
accept;
}
}
term MEDIUM {
from {
route-filter 0.0.0.0/0 prefix-length-range /30-/31;
}
then {
priority medium;
accept;
}
}
term HIGH {
from {
route-filter 0.0.0.0/0 prefix-length-range /32-/32;
}
then {
priority high;
accept;
}
}
tt@router# show protocols ospf
import OSPF-SPF-PRIORITY;
Per verificare la correttezza della configurazione si può utilizzare il comando "show ospf route detail", che mostra, per ciascun prefisso appreso via OSPF, il livello di priorità. Riporto di seguito un esempio, in cui per brevità ho eliminato molte righe:
tt@P1-1> show ospf route detail
Topology default Route Table:
Prefix Path Route NH Metric NextHop Nexthop
Type Type Type Interface Address/LSP
... < righe omesse > ...
10.1.11.0/30 Intra Network IP 2 fe-0/0/0.0 172.20.1.111
area 0.0.0.0, origin 192.168.0.11, priority medium
10.1.12.0/30 Intra Network IP 2 fe-0/0/0.0 172.20.1.111
area 0.0.0.0, origin 192.168.0.11, priority medium
172.20.1.0/24 Intra Network IP 1 fe-0/0/0.0
area 0.0.0.0, origin 192.168.0.11, priority low
172.30.1.0/24 Intra Network IP 1 fe-0/0/1.0
area 0.0.0.0, origin 192.168.1.11, priority low
192.168.0.11/32 Intra Network IP 1 fe-0/0/0.0 172.20.1.111
area 0.0.0.0, origin 192.168.0.11, priority high
192.168.0.12/32 Intra Network IP 1 fe-0/0/0.0 172.20.1.112
area 0.0.0.0, origin 192.168.0.12, priority high
... < righe omesse > ...
CONCLUSIONI
Con questo post, ho illustrato un altro tassello sulle metodiche per ridurre i tempi di convergenza dei protocolli Link State. L'idea di fondo dell'opzione illustrata è quella di privilegiare alcuni prefissi rispetto ad altri nel ricalcolo dell'albero dei percorsi ottimi. Questo porta vantaggi ad alcuni servizi, come ad esempio i servizi multicast SSM, riducendo la perdita di pacchetti.
Il prossimo post, e credo ultimo, su questo argomento sarà sul "Loop Free Alternate", una funzionalità di convergenza sul piano dati simile (concettualmente) a quanto già visto con la funzionalità BGP PIC, e simile anche al concetto di Feasible Successor del protocollo EIGRP.
Se siete interessati a eseguire un assessment sulla vostra implementazione di OSPF e IS-IS e valutare l'introduzione di funzionalità avanzate di convergenza, non avete che da consultare i nostri servizi di consulenza tecnologica. Se invece siete interessati a saperne di più, consultate il nostro catalogo di corsi tecnici.
Se siete interessati a eseguire un assessment sulla vostra implementazione di OSPF e IS-IS e valutare l'introduzione di funzionalità avanzate di convergenza, non avete che da consultare i nostri servizi di consulenza tecnologica. Se invece siete interessati a saperne di più, consultate il nostro catalogo di corsi tecnici.
Pubblicato in
ReissBlog
Etichettato sotto
Venerdì, 22 Maggio 2015 13:07
DMVPN FASE 3
Questo post è il seguito dei precedenti dedicati al modello DMVPN. Ricordo dai post precedenti, che la caratteristica fondamentale del modello DMVPN Fase 1 è che il traffico Spoke-Spoke deve necessariamente transitare per il router Hub, mentre quella del modello DMVPN Fase 2 è la possibilità che hanno i router Spoke di scambiare traffico direttamente, senza passare dai router Hub.
In questo post illustrerò una importante evoluzione del modello DMVPN fase 2, in cui è sempre permesso lo scambio diretto del traffico Spoke-Spoke, eliminando alcune restrizioni di questo modello, come ad esempio l'impossibilità per i router Hub di aggregare i prefissi IP annunciati dai router Spoke. Questa evoluzione è nota come modello DMVPN fase 3 (per fortuna l'ultimo stadio di evoluzione), ed è stata introdotta nell'IOS Cisco a partire dalla versione 12.4(6)T.
VANTAGGI DEL MODELLO DMVPN FASE 3
Il modello DMVPN fase 3, che come vedremo è basato su una idea già nota agli esperti del protocollo IP, consente di eliminare alcune limitazioni del modello DMVPN fase 2.
La prima e forse la più importante, è la possibilità di non poter effettuare aggregazioni di prefissi sui router Hub. Ricordo che nel modello DMVPN fase 2, la ragione per cui non è possibile effettuare aggregazioni sui router Hub è che altrimenti il prefisso aggregato verrebbe annunciato con il Next-Hop del router Hub, impedendo la comunicazione diretta Spoke-Spoke. Infatti, nel modello DMVPN fase 2 ricordo che è cruciale che il Next-Hop che i router Spoke "vedono" sia quello degli altri router Spoke. L'impossibilità di aggregare i prefissi in un modello DMVPN non deve essere trascurata, poiché potrebbe creare importanti problemi di scalabilità quando il numero di Spoke è elevato. Ad esempio, se una rete DMVPN ha 1.000 Spoke e ciascun Spoke annuncia un solo prefisso, ciascun router Hub deve inviare poco meno di 1.000.000 di annunci, con un carico di CPU non indifferente e una notevole occupazione di memoria su tutti i router, Hub e Spoke. Questo, se sui router Hub potrebbe non creare grossi problemi, li può però creare sui router Spoke, che di solito sono router di "piccola taglia".
Una seconda limitazione riguarda l'utilizzo di topologie DMVPN gerarchiche. A volte, per aumentare la scalabilità si tende a creare DMVPN regionali, unite tra loro da Hub di livello gerarchico superiore, che vedono come propri Spoke gli Hub regionali. Con una simile topologia, se si utilizzasse il modello DMVPN fase 2, ciascuna rete DMVPN regionale sarebbe indipendente dalle altre e quindi il traffico Spoke-Spoke tra router Spoke di regioni diverse, deve necessariamente transitare sui router Hub regionali (non necessariamente sui router Hub di gerarchia superiore), aumentando i ritardi end-to-end. Per contro, con il modello DMVPN fase 3, le reti regionali e i router Hub di gerarchia superiore sono visti come una unica DMVPN, consentendo al traffico Spoke-Spoke percorsi ottimali.
Infine, un'altra limitazione, meno importante, che è possibile eliminare riguarda l'utilizzo di OSPF come protocollo di routing. Nel modello DMVPN fase 2, poiché è cruciale che gli annunci da Hub a Spoke mantengano il Next-Hop originale, si è costretti ad utilizzare la modalità "broadcast" di OSPF su reti NBMA. Questa modalità, come noto, richiede l'elezione di DR e BDR, e pone quindi delle limitazioni al numero di Hub, che al massimo possono essere due. Con il modello DMVPN fase 3 è invece possibile, come accennerò in seguito, l'utilizzo della modalità "point-to-multipoint", che non richiede l'elezione di DR e BDR, e quindi lascia maggiori libertà sulla scelta dei router Hub.
Infine, un ultimo vantaggio del modello DMVPN fase 3, anche questo meno importante, è che tutti pacchetti dati vengono inoltrati utilizzando le informazioni della tabella CEF, e non come avviene nel modello DMVPN fase 2, dove il primo pacchetto viene sempre "process switched".
FUNZIONAMENTO
A questo punto è necessario illustrare il funzionamento del modello DMVPN fase 3, mettendo in risalto le differenze con il funzionamento del modello DMVPN fase 2.
La prima e più importante differenza è che nel modello DMVPN fase 3 gli Spoke possono rispondere direttamente ai messaggi NHRP Resolution Request. Nel modello DMVPN fase 2 invece, sono solo i router Hub che possono rispondere a questi messaggi.
Vediamo il funzionamento passo per passo. Come nel modello DMVPN fase 2, i router Spoke registrano le loro associazioni <Indirizzo logico ; Indirizzo NBMA> al NHS (che è un router Hub). Questo, come nei modelli precedenti, consente ai router Hub di "scoprire" dinamicamente i router Spoke e quindi di stabilire le adiacenze di routing (o sessioni nel caso del BGP). A valle di tutto questo vengono scambiate le informazioni di routing. E fin qui nessuna novità. Ma in realtà una differenza sostanziale rispetto al modello DMVPN fase 2 c'è, e riguarda il Next-Hop. Ho ripetuto più volte che nel modello DMVPN fase 2 è cruciale preservare il Next-Hop originale, cosa non più necessaria nel modello DMVPN fase 3. Il perché di questo si capirà a breve, faccio notare però che è proprio questo aspetto che consente l'aggregazione dei prefissi sui router Hub.
Alla ricezione degli annunci del protocollo di routing, i router Spoke popolano la loro RIB e FIB (= tabella CEF). A questo punto, poiché il Next-Hop è l'indirizzo logico dell'Hub, noto ai router Spoke, non vi sono più nella tabella CEF adiacenze nello stato "invalid" o "glean", come invece accadeva nel modello DMVPN fase 2 a causa del fatto che il Next-Hop rimaneva quello originale dello Spoke, non noto agli altri router Spoke, ma solo al router Hub. Tutto questo implica che i pacchetti Spoke-Spoke utilizzano sempre la tabella CEF, e non sono mai "process switched", come invece avviene per il primo pacchetto nel modello DMVPN fase 2. Ma qui sorge il problema chiave: poiché non vi è più un trigger del protocollo NHRP per conoscere l'indirizzo NBMA dello Spoke destinazione, trigger che nel modello DMVPN fase 2 avveniva proprio grazie allo stato "invalid" del prefisso destinazione nella tabella CEF, come fa il router Spoke sorgente a conoscere l'indirizzo NBMA del router Spoke destinazione ? Tra l'altro, il router Spoke sorgente nella propria tabella di routing ha sempre come Next-Hop il router Hub, e quindi deve in qualche modo coinvolgere nella soluzione del mistero, anche il router Hub.
La magia che consente di risolvere l'arcano è l'analogo di una vecchia conoscenza del protocollo IP: la funzione ICMP redirect. Per chi non ne ricordasse il funzionamento, un caldo invito, prima di continuare la lettura, a rinfrescare la memoria (magari rileggendo la celebre RFC 791 di Jonathan (Jon) Postel del Settembre 1981 !!!). Quello che accade nel modello DMVPN fase 3 è che appena il router Spoke sorgente invia il primo pacchetto, questo viene regolarmente inoltrato al router Hub (che è il Next-Hop). Il router Hub riceve il pacchetto sull'interfaccia virtuale mGRE "tunnel X", e lo invia al router Spoke destinazione attraverso la stessa interfaccia mGRE "tunnel X". Questo fa da trigger a un messaggio NHRP redirect, che consente di informare il router sorgente dell'indirizzo NBMA dello Spoke destinazione, noto al router Hub dal processo iniziale di registrazione (vedi figura seguente). Il messaggio NHRP redirect informa il router Spoke sorgente che sta utilizzando un percorso non ottimo, e che invece dovrebbe utilizzare il percorso ottimo Spoke-Spoke.
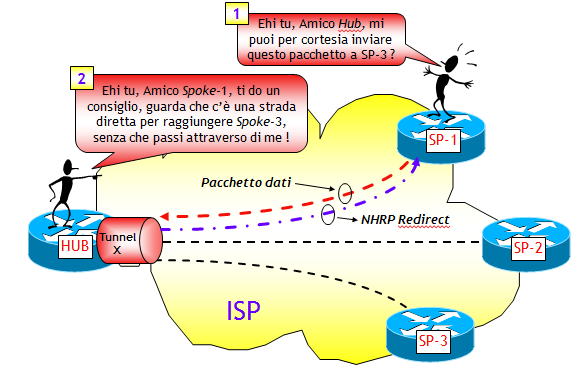
A questo punto, il router Spoke sorgente, a seguito della ricezione del messaggio NHRP redirect, invia un messaggio NHRP Resolution Request non al NHS (l'Hub) ma direttamente al router Spoke destinazione. Il messaggio attraversa l'Hub (perché ?), che però non lo ispeziona ma fa da semplice "tramite" tra gli Spoke.
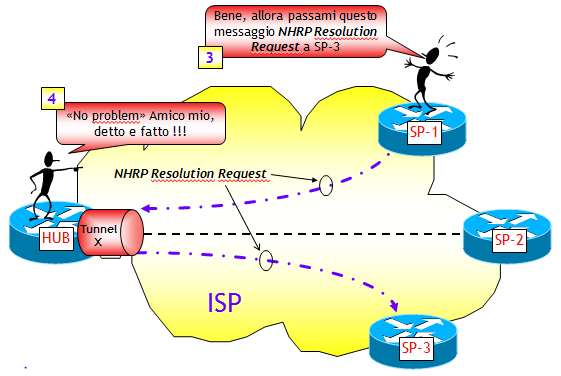
Il router Spoke destinazione, e non il NHS, alla ricezione di questo messaggio risponde con un normale messaggio NHRP Resolution Reply. Tutte le informazioni necessarie per veicolare questo messaggio al router Spoke sorgente sono contenute nel messaggio NHRP Resolution Request ricevuto. Il messaggio NHRP Resolution Reply contiene l'intero prefisso IP di cui fa parte l'indirizzo IP destinazione del pacchetto inviato dallo Spoke sorgente.
A questo punto il gioco è fatto. Il router Spoke sorgente, oltre a popolare la tabella delle associazioni ottenute via NHRP, riscrive il Next-Hop sulla tabella CEF, che verrà utilizzato successivamente per tutti i pacchetti destinati a indirizzi del prefisso appartenente al router Spoke destinazione.
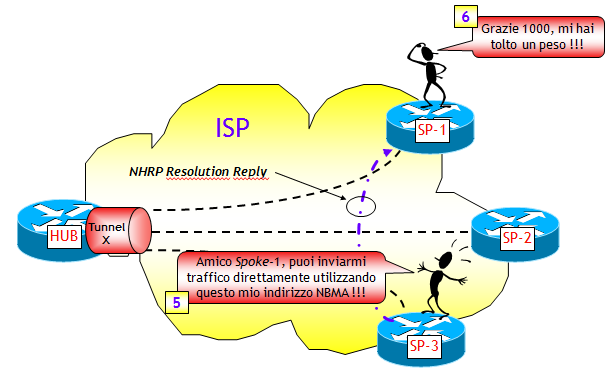
Riassumendo:
- I messaggi NHRP Resolution Request non sono più innescati da adiacenze "invalid" e "glean" della tabella CEF. L'implicazione più importante di questo punto è che non è necessario mantenere negli annunci del protocollo di routing il Next-Hop originale, e quindi è possibile eseguire aggregazioni di prefissi sugli Hub.
- I router Hub non sono più le sole fonti di informazioni NHRP, ma al gioco partecipano anche i router Spoke. Oltre a un modello NHRP client-server, DMVPN fase 3 utilizza anche un modello NHRP di tipo peer-to-peer.
- I messaggi NHRP Reply contengono informazioni su un intero prefisso, invece che delle sole informazioni sulla risoluzione del Next-Hop.
A questo punto, come sempre, non ci rimane che passare "dalla poesia alla prosa" ...
ASPETTI DI CONFIGURAZIONE DEL PROTOCOLLO NHRP
La configurazione del protocollo NHRP, oltre ai comandi di base già visti per le fasi 1 e 2 richiede:
- Sui soli router Hub il comando "ip nhrp redirect", che abilita l'invio dei messaggi NHRP Redirect.
- Sui soli router Spoke il comando "ip nhrp shortcut", che consente di riscrivere sulla tabella CEF il nuovo Next-Hop comunicato attraverso il messaggio NHRP Redirect. Si noti che senza questo comando un router Spoke si comporta esattamente come in un modello DMVPN fase 1, con il traffico Spoke-Spoke che fa sempre transito su un router Hub.
Illu strerò con un esempio cosa avviene utilizzando questi comandi. La rete test che utilizzerò è la stessa dei post precedenti sull'argomento, e riportata nella figura seguente. I router sono tutti equipaggiati con IOS 12.4(11)T. Per questo test, nell'ottica di focalizzare meglio l'attenzione sul meccanismo di funzionamento del modello DMVPN Fase 3, non utilizzerò il router H2.

Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. La configurazione di SP2 è analoga e viene lasciata come esercizio.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp network-id 200
ip nhrp redirect
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
hostname SP1
!
interface Tunnel1
ip address 20.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.1
ip nhrp map 20.0.0.11 172.16.1.1
ip nhrp nhs 20.0.0.11
ip nhrp network-id 200
ip nhrp holdtime 120
ip nhrp registration timeout 90
ip nhrp shortcut
tunnel source FastEthernet2/0
tunnel mode gre multipoint
!
La configurazione del protocollo NHRP termina qui. A questo punto non è possibile vedere granché, il funzionamento del modello DMVPN fase 3 inizia con l'aggiunta di un protocollo di routing.
ROUTING VIA EIGRP
L'utilizzo di EIGRP richiede gli stessi comandi già visti per il modello DMVPN fase 1, né uno in più né uno in meno. Faccio notare che il comando "no ip next-hop-self eigrp numero-AS" sui router Hub non va eseguito !
Inoltre è possibile, sui router Hub, effettuare aggregazione di prefissi con il comando "ip summary-address eigrp numero-AS prefisso maschera" a livello interfaccia "tunnel X". In particolare, è possibile utilizzare il comando "ip summary-address eigrp numero-AS 0.0.0.0 0.0.0.0" per generare una default-route.
Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. La configurazione di SP2 è analoga e viene lasciata come esercizio.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
no ip split-horizon eigrp 200
ip summary-address eigrp 200 0.0.0.0 0.0.0.0
ip nhrp map multicast dynamic
ip nhrp network-id 200
ip nhrp redirect
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router eigrp 200
no auto-summary
network 20.0.0.0
network 50.0.0.0
!
NOTA: ricordo che il comando "ip summary-address eigrp 200 0.0.0.0 0.0.0.0" consente di generare una default-route EIGRP, che viene inviata su tutte le adiacenze EIGRP stabilite attraverso l'interfaccia "tunnel 11".
hostname SP1
!
interface Tunnel1
ip address 20.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.1
ip nhrp map 20.0.0.11 172.16.1.1
ip nhrp nhs 20.0.0.11
ip nhrp network-id 200
ip nhrp holdtime 120
ip nhrp registration timeout 90
ip nhrp shortcut
tunnel source FastEthernet2/0
tunnel mode gre multipoint
!
router eigrp 200
no auto-summary
network 20.0.0.0
network 50.0.0.0
eigrp stub
!
Si noti che le interfacce "tunnel X" configurate sui router Spoke non hanno alcun comando relativo a EIGRP.
A questo punto, per capire tutto l'handshake di messaggi NHRP, è necessario attivare un "debug nhrp packet" sui vari router e analizzare il risultato. Per non appesantire il post, ho riportato i risultati in un file allegato, a disposizione dei più curiosi.
Con i classici comandi "show ip route" e "show ip cef" in effetti non è possibile vedere granché. Una informazione importante si vede invece con il comando "show ip nhrp". Prima che un qualsiasi pacchetto dati fluisca da SP1 a SP2, il comando da il seguente risultato:
SP1# show ip nhrp
20.0.0.11/32 via 20.0.0.11, Tunnel1 created 00:21:21, never expire
Type: static, Flags: nat used
NBMA address: 172.16.1.1
Per inviare un primo pacchetto a un Host del prefisso 50.0.12.0/24, ho utilizzato il solito traceroute:
SP1# traceroute 50.0.12.12
Type escape sequence to abort.
Tracing the route to 50.0.12.12
1 20.0.0.11 48 msec 60 msec 52 msec
2 20.0.0.2 98 msec * 85 msec
Come si può notare, i pacchetti IP del traceroute seguono il percorso attraverso il router Hub H1, per arrivare a destinazione. Lo stesso identico comportamento si aveva con il modello DMVPN fase 2.
Vediamo ora le associazioni <Indirizzo logico ; Indirizzo NBMA> presenti sul router SP1, dopo l'esecuzione del traceroute:
SP1# show ip nhrp
20.0.0.1/32 via 20.0.0.1, Tunnel1 created 00:00:05, expire 00:01:55
Type: dynamic, Flags: router unique nat local
NBMA address: 10.1.11.2
(no-socket)
20.0.0.2/32 via 20.0.0.2, Tunnel1 created 00:00:05, expire 00:01:54
Type: dynamic, Flags: router nat implicit
NBMA address: 10.1.11.6
(no-socket)
20.0.0.11/32 via 20.0.0.11, Tunnel1 created 00:27:13, never expire
Type: static, Flags: nat used
NBMA address: 172.16.1.1
50.0.12.0/24 via 20.0.0.2, Tunnel1 created 00:00:05, expire 00:01:53
Type: dynamic, Flags: router nat used
NBMA address: 10.1.11.6
Rispetto a quanto avveniva con il modello DMVPN fase 2, si ha una riga in più, l'ultima. Questo deriva dal fatto che, in base a quanto detto nella descrizione del funzionamento, il router SP2 invia a SP1 un NHRP Resolution Reply, contenente l'intero prefisso IP di cui fa parte l'indirizzo IP destinazione del pacchetto (= 50.0.12.12) inviato da SP1.
Nella tabella di routing IP non vi è traccia di questo prefisso:
SP1#sh ip route 50.0.12.0
% Subnet not in table
mentre nella tabella CEF vi è l'informazione che il prefisso 50.0.12.0/24 viene instradato verso l'Hub.
SP1#sh ip cef 50.0.12.0
0.0.0.0/0, version 34, epoch 0
0 packets, 0 bytes
via 20.0.0.11, Tunnel1, 0 dependencies
next hop 20.0.0.11, Tunnel1
valid adjacency
Qualora dopo il primo traceroute, se ne eseguisse immediatamente un altro:
SP1#trace 50.0.12.12
Type escape sequence to abort.
Tracing the route to 50.0.12.12
1 20.0.0.2 86 msec * 74 msec
si può notare che il traffico da SP1 verso l'indirizzo IP 50.0.12.12 non passa più attraverso l'Hub H1, ma segue un percorso diretto SP1-->SP2. In particolare, i pacchetti IP vengono incapsulati un tunnel GRE con indirizzo IP sorgente coincidente con quello dell'interfaccia FastEthernet2/0 (= 10.1.11.2) e indirizzo IP destinazione l'indirizzo NBMA 10.1.11.6, corrispondente all'indirizzo logico 20.0.0.2 di SP2. Quest'ultimo indirizzo viene dedotto dalla tabella delle associazioni <Indirizzo logico ; Indirizzo NBMA> presenti sul router SP1, e ottenute da SP2 attraverso il protocollo NHRP (più precisamente attraverso un messaggio NHRP Resolution Reply).
Concludendo, per abilitare EIGRP in uno scenario DMVPN fase 3, è necessario utilizzare i seguenti accorgimenti:
1. Disabilitare sui router Hub lo split-horizon con il comando "no ip split-horizon eigrp numero-AS".
E per una soluzione altamente scalabile:
2. Effettuare sui router Hub aggregazione di prefissi con il comando "ip summary-address eigrp ..." a livello interfaccia "tunnel X", ed eventualmente, al
limite, generare una default-route EIGRP.
limite, generare una default-route EIGRP.
3. Abilitare la funzionalità EIGRP Stub sui router Spoke.
ROUTING VIA OSPF
Qualora si decidesse di utilizzare OSPF, poiché non è necessario preservare il Next-Hop originale, è possibile utilizzare la stessa modalità di OSPF su reti NBMA utilizzata per il modello DMVPN fase 1, ossia la "point-to-multipoint".
Però vi voglio mettere in guardia dall'utilizzo di OSPF, perché con questo protocollo non è possibile effettuare alcuna aggregazione sugli Hub, a meno di non utilizzare qualche trucchetto diabolico. Il problema nasce dal fatto che di norma tutte le interfacce "tunnel X" della DMVPN vengono assegnate a una sola area OSPF, ed è noto che non è possibile aggregare alcunché all'interno di un'area OSPF.
Il problema può essere aggirato con un po' di fantasia, che vi lascio volentieri (io per curiosità ho fatto delle prove e i trucchetti che ho elaborato funzionano). Ma il mio consiglio è di non utilizzare OSPF !!! E quindi con OSPF la finisco qui.
ROUTING VIA BGP
Qualora si decidese di utilizzare come protocollo di routing il BGP, valgono le stesse considerazioni fatte per il modello DMVPN fase 1. Per cui rimando alla discussione del post precedente "DMVPN FASE 1 - PARTE II". Vorrei però porre l'attenzione su un aspetto che riguarda l'utilizzo di sessioni iBGP. In questo scenario, l'applicazione della funzionalità di Route Reflection richiede qualcosa di aggiuntivo. Infatti, come noto e come visto nell'applicazione di questa funzionalità nel modello DMVPN fase 2, gli annunci iBGP riflessi dai Route Reflector, conservano il Next-Hop originario. E questo, mentre è necessario nel modello DMVPN fase 2, per quanto abbiamo detto sopra non va bene nel modello DMVPN fase 3. Recentemente, l'IOS Cisco ha introdotto un escamotage per variare questo che è il comportamento di default dei Route Reflector: si tratta del comando "neighbor ... next-hop-self all", che consente comunque di variare il BGP Next-Hop, ponendolo pari al proprio indirizzo IP utilizzato per le sessioni iBGP verso i Route Reflector Client. Va comunque detto che in uno scenario DMVPN fase 3, la funzionalità di Route Reflection non è necessaria. Vedi a questo proposito l'esempio di utilizzo di sessioni iBGP descritto nel post "DMVPN FASE 1 - PARTE II".
In questo post, voglio illustrare il funzionamento del modello DMVPN fase 3 con un prova su una topologia Dual DMVPN, utilizzando sessioni eBGP. La rete che utilizzerò è un po' più articolata ed è riportata nella figura seguente.
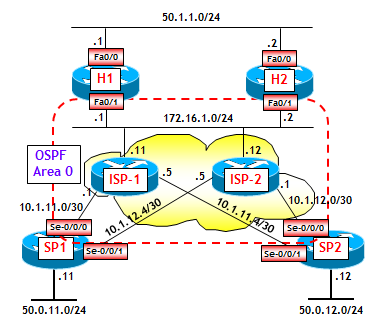
Il piano di numerazione logico è riportato nella figura seguente.
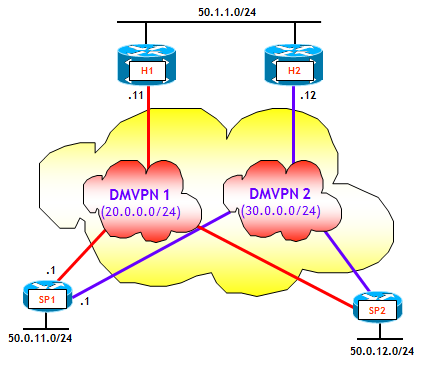
Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. Come sempre, le configurazioni di H2 e SP2 sono analoghe e vengono lasciate come esercizio. Per semplicità, anche qui nella configurazione ho omesso il comando per l'autenticazione dei messaggi NHRP.
hostname SP1
!
interface Tunnel1
ip address 20.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.11
ip nhrp map 20.0.0.11 172.16.1.11
ip nhrp network-id 204
ip nhrp holdtime 120
ip nhrp nhs 20.0.0.11
ip nhrp registration timeout 90
ip nhrp shortcut
tunnel source Serial0/0/0
tunnel mode gre multipoint
!
interface Tunnel11
ip address 30.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.12
ip nhrp map 30.0.0.12 172.16.1.12
ip nhrp network-id 304
ip nhrp holdtime 120
ip nhrp nhs 30.0.0.12
ip nhrp registration timeout 90
ip nhrp shortcut
tunnel source Serial0/0/1
tunnel mode gre multipoint
!
router bgp 65201
redistribute connected
neighbor 20.0.0.11 remote-as 65101 ! sessione eBGP verso H1
neighbor 20.0.0.11 filter-list 1 out
neighbor 30.0.0.12 remote-as 65102 ! sessione eBGP verso H2
neighbor 30.0.0.12 filter-list 1 out
neighbor 30.0.0.12 route-map SET-LP in ! utilizzo l'interfaccia "tunnel 11" come backup
!
ip as-path access-list 1 permit ^$
!
route-map SET-LP permit 10
set local-preference 90
!
La configurazione del BGP è abbastanza classica e può essere utilizzata come template di configurazione per tutti i router Spoke. Solo per "giocare" un po', ho assegnato agli annunci BGP provenienti dalla sessione con il BGP peer 30.0.0.12, un valore 90 di Local Preference. Poiché come noto, il valore di default del Local Preference è 100, ciò equivale ad utilizzare l'interfaccia "tunnel 1" come collegamento primario e l'interfaccia "tunnel 11" come backup. Inoltre, vorrei far notare la presenza del filtro AS_PATH con Regular Expression "^$". In questo esempio il filtro è necessario, oltre che per fare in modo che ciascun router Spoke annunci solamente i propri prefissi, per evitare che le default-route annunciate dai router Hub, vengano automaticamente propagate dai route Spoke all'altro Hub, facendo in modo che i router Spoke diventino di transito per il traffico tra router Hub. Ad, esempio, si consideri sul router SP1 la default-route ricevuta da H1. Poiché SP1 ha una seconda sessione eBGP con H2, senza alcun accorgimento, la default-route verrebbe automaticamente propagata da SP1 a H2. H2 quindi, in caso di fuori servizio dell'interfaccia Fa0/0, utilizzerebbe SP1 come transito per raggiungere la rete 50.1.1.0/24. Ma questo non è una buona cosa, poiché significherebbe riversare sui router Spoke, che di solito sono di "piccola taglia", un traffico che potrebbero non essere in grado di sostenere. Giusto per fare una analogia, questo filtro emula la funzionalità EIGRP stub nel caso il protocollo di routing utilizzato sia EIGRP. In realtà c'è una soluzione alternativa che evita l'utilizzo di quest'ultimo filtro, è sufficiente utilizzare sui due router Hub lo stesso identico numero di AS.
Vediamo ora la configurazione di H1.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp network-id 204
ip nhrp redirect
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router bgp 65101
bgp listen range 20.0.0.0/24 peer-group SPOKE
bgp listen limit 200
neighbor SPOKE peer-group
neighbor SPOKE remote-as 65201
neighbor SPOKE default-originate
neighbor SPOKE prefix-list SOLODEFAULT out
!
ip prefix-list SOLODEFAULT permit 0.0.0.0/0
La configurazione del processo BGP su H1 utilizza i già citati BGP Dynamic Neighbors. Per chi non ricordasse il loro funzionamento e le loro proprietà di scalabilità, invito alla rilettura del post "DMVPN Fase 1 - Parte II". Inoltre, ho configurato un filtro di tipo "prefix-list" che consente l'annuncio della sola default-route.
Con queste configurazioni, sulla tabella BGP di H1 compaiono i prefissi annunciati dai router Spoke:
H1# show bgp ipv4 unicast
BGP table version is 4, local router ID is 192.168.1.1
. . . < legenda omessa > . . .
Network Next Hop Metric LocPrf Weight Path
0.0.0.0 0.0.0.0 0 i
*> 50.0.11.0/24 20.0.0.1 0 0 65201 ?
*> 50.0.12.0/24 20.0.0.2 0 0 65201 ?
Su SP1 la tabella BGP è la seguente:
SP1# show bgp ipv4 unicast
BGP table version is 5, local router ID is 10.1.99.11
. . . < legenda omessa > . . .
Network Next Hop Metric LocPrf Weight Path
*> 0.0.0.0 20.0.0.11 0 65101 i
* 30.0.0.12 90 0 65102 i
*> 50.0.11.0/24 0.0.0.0 32768 ?
Come si può notare, il BGP Next-Hop per la default-route best-path è 20.0.0.11 (H1). Ciò è confermato anche dal contenuto (parziale) della tabella di routing:
SP1# show ip route bgp
Gateway of last resort is 20.0.0.11 to network 0.0.0.0
B* 0.0.0.0/0 [20/0] via 20.0.0.11, 00:02:26
A questo punto, è possibile ripetere tutte le considerazioni già illustrate con il protocollo EIGRP, considerazioni che non riporto per appesantire ulteriormente il post.
CONCLUSIONI
In questo post ho cercato di illustrare l'utilizzo degli stessi tre ben noti protocolli di routing al modello DMVPN Fase 2. Sulla scelta valgono le stesse considerazioni già illustrate nel post "DMVPN Fase 1 - Parte II". Io non avrei dubbi, comunque l'unico protocollo che mi sento di sconsigliare è OSPF.
I post sul modello DMVPN però non finiscono qui, manca un argomento molto importante, come aggiungere gli aspetti di sicurezza, che consentono attraverso i classici tunnel IPsec, di cifrare il traffico. Poi, ho un amico che mi ha promesso un post sull'integrazione del modello DMVPN nelle L3VPN BGP/MPLS . . . Arrivederci alle prossime puntate.
Coming up next, un post su un argomento poco noto che riguarda un "trucco" per migliorare la velocità di convergenza dei protocolli Link-State : "spf per-prefix prioritization".
I post sul modello DMVPN però non finiscono qui, manca un argomento molto importante, come aggiungere gli aspetti di sicurezza, che consentono attraverso i classici tunnel IPsec, di cifrare il traffico. Poi, ho un amico che mi ha promesso un post sull'integrazione del modello DMVPN nelle L3VPN BGP/MPLS . . . Arrivederci alle prossime puntate.
Coming up next, un post su un argomento poco noto che riguarda un "trucco" per migliorare la velocità di convergenza dei protocolli Link-State : "spf per-prefix prioritization".
Pubblicato in
ReissBlog
Etichettato sotto
Martedì, 12 Maggio 2015 09:32
CONVERGENZA DEI PROTOCOLLI LINK-STATE: OTTIMIZZAZIONI DELL’ALGORITMO SPF
La determinazione dell’albero SPF ha rappresentato in passato il collo di bottiglia nel tempo di convergenza dei protocolli Link State, considerato l’alto tempo di calcolo necessario per la determinazione dell’albero SPF, tramite l’algoritmo di Dijkstra.
Vari fattori hanno contribuito negli anni a ridurre in modo sostanziale il tempo di calcolo dell’albero SPF, come ad esempio, la maggiore potenza di elaborazione a disposizione dei router, l’ottimizzazione del codice e l’introduzione di metodi che contribuiscono ad evitare il ricalcolo quando in realtà non servirebbe.
Tra i metodi che consentono di evitare inutili ricalcoli dell’algoritmo SPF, illustrerò in questo post l’Incremental SPF (iSPF) e il Partial Route Calculation (PRC).
Il metodo iSPF consente di evitare il ricalcolo dell’albero SPF quando la variazione della topologia logica non interessa l’albero SPF originale, mentre il PRC consente di evitare il ricalcolo dell’albero SPF quando la topologia logica della rete rimane invariata.
Grazie a questi metodi, se applicati, il tempo per la determinazione dell’albero dei cammini ottimi subisce una ulteriore sostanziale diminuzione.
INCREMENTAL SPF (iSPF)
L’idea dell’algoritmo iSPF è molto vecchia e fu introdotta per la prima volta nel routing della rete ARPANET nel lontano Marzo 1979. Il metodo e i risultati dell’applicazione furono riportati nell’articolo «ARPANET Routing Algorithm Improvements», di Eric Rosen e altri.
Per comprendere il funzionamento di iSPF, consideriamo dapprima la topologia logica riportata a sinistra nella figura seguente. A destra è riportato l’albero SPF determinato dal router A (di cui il lettore può facilmente verificare la correttezza).
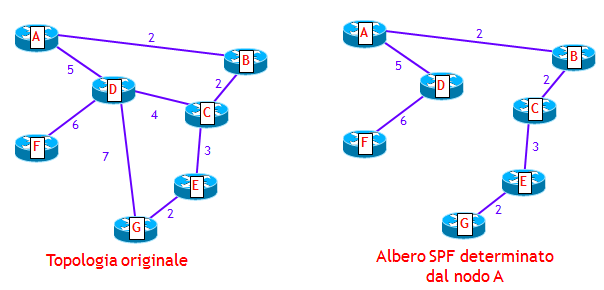
Si noti che l’albero SPF non contiene i link logici (adiacenze !) DC e DG. Ciò significa che la perdita delle adiacenze DC e/o DG, non ha alcun effetto sulla determinazione dell’albero SPF, che rimane esattamente identico, come mostrato nella figura seguente.
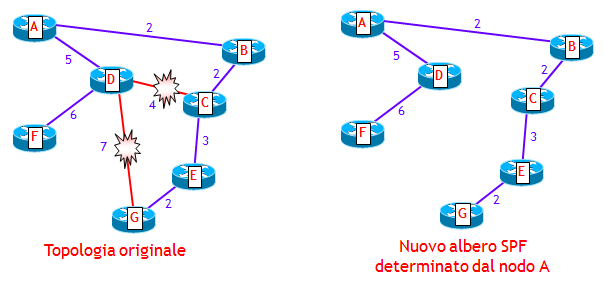
La conseguenza pratica è che in caso di perdita delle adiacenze DC e/o DG, il processo di routing non ha alcun bisogno di ricalcolare l’algoritmo SPF. L’eventuale ricalcolo dell’albero SPF produrrebbe esattamente lo stesso albero SPF !
Un altro caso in cui il metodo iSPF consente di risparmiare il ricalcolo dell’intero albero SPF, si ha quando viene aggiunto alla topologia logica un router «foglia» (stub router), ossia un router che ha una singola connessione con un altro router.
La figura seguente mostra cosa avviene in una simile situazione.
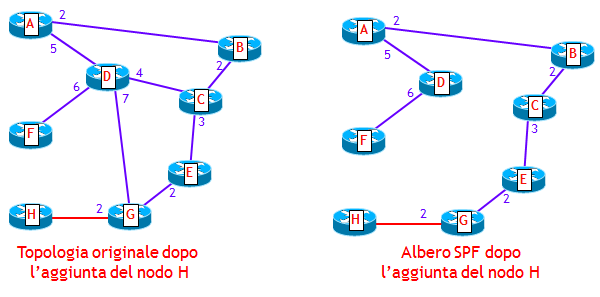
Alla topologia originale viene aggiunto lo stub router H. Il nuovo albero SPF, dopo l’aggiunta dello stub router H risulta identico al precedente, con la sola variante dell’aggiunta dello stub router H. In altre parole, l’albero SPF è semplicemente "esteso" con l’aggiunta del nuovo stub router. Ciò significa che l’albero SPF, anche in questo caso non va ricalcolato.
Un altro caso in cui il metodo iSPF consente di risparmiare il ricalcolo dell’intero albero SPF, si ha quando viene persa un’adiacenza che è parte dell’albero SPF originale. In questo caso è necessario il ricalcolo di quella sola parte dell’albero SPF che coinvolge tutti i router collegati a valle dell’adiacenza persa.
La figura seguente mostra cosa avviene in una simile situazione.
Supponiamo che l’adiacenza tra i router C ed E cada. L’adiacenza è parte dell’albero SPF originale, quindi è necessario un ricalcolo dell’albero SPF. Ma il ricalcolo non coinvolge i router B, C, D e F, ma solo i router G ed E, che sono a valle dell’adiacenza persa. In altre parole, il router A, la radice dell’albero SPF, ricalcola i percorsi ottimi solo verso i router E e G, e non verso gli altri.
Una proprietà interessante di iSPF in questa situazione, è che più l’adiacenza persa è lontana dalla radice dell’albero, meno calcoli vengono effettuati. Sebbene per la radice dell’albero il tempo di rilevazione dell’adiacenza persa aumenti, a causa dell’aumento dei tempi di propagazione (via flooding) dei LSP (o LSU nel linguaggio OSPF), il nodo radice, grazie all’utilizzo di iSPF, esegue meno calcoli, riducendo sostanzialmente il tempo per determinare i nuovi percorsi ottimi.
Si noti comunque che, poiché ciascun router ha un diverso albero SPF per la topologia originale, la perdita di una stessa adiacenza può avere effetti diversi sul guadagno di efficienza di iSPF, rispetto alla determinazione classica dell’albero SPF.
Altro aspetto interessante di iSPF è che la sua efficienza, rispetto alla determinazione classica dell’albero SPF, è tanto maggiore quanto minore la magliatura della rete. Nel caso asintotico di rete completamente magliata, iSPF non da alcun vantaggio.
Questo esempio, e quello riportato nelle due figure precedenti, rendono l’idea del funzionamento del metodo iSPF, che consiste nell’evitare ricalcoli inutili dell’algoritmo di Dijkstra o anche di diminuire il numero di calcoli da effettuare.
IMPLEMENTAZIONE CISCO DI iSPF
Nelle piattaforme di routing Cisco, di default l’iSPF non è abilitato e non sempre è possibile abilitarlo.
Nei router che utilizzano IOS o IOS XE, iSPF per OSPF (e anche per IS-IS) può essere abilitato con il semplice comando "ispf" eseguito a livello di processo di routing.
Nell’IOS XR invece, l’implementazione di OSPF non prevede l’abilitazione di iSPF, mentre è possibile per il protocollo IS-IS.
La figura seguente riporta i risultati di un esperimento che mette a confronto l’algoritmo SPF classico e l’iSPF.
Come si può notare, all’aumentare del numero di nodi, il miglioramento introdotto dall’iSPF diventa veramente sensibile. In una rete di 10.000 nodi, si passa da tempi di circa 520 msec per l’algoritmo SPF classico, a circa 50 msec per l’algoritmo iSPF.
PARTIAL ROUTE CALCULATION (PRC)
Il lettore familiare con il protocollo IS-IS sa che un aspetto chiave di IS-IS, è che i prefissi IP sono visti come particolari stub networks (End System nel linguaggio di IS-IS), ossia, direttamente connessi ad un router. Quando un router che utilizza IS-IS invia il suo LSP che descrive la sua «topologia locale», inserisce in questo anche l’elenco dei prefissi IP direttamente connessi (sia IPv4 che eventualmente IPv6, che di altri protocolli di Livello 3).
Questo ha implicazioni importanti nel calcolo/ricalcolo dei percorsi ottimi. Infatti, per raggiungere un Host di qualsiasi prefisso IP è sufficiente «localizzare» il prefisso, ossia determinare il router dove questo è direttamente connesso, e quindi determinare il percorso verso questo router. In caso di cambio dello stato (up/down) del prefisso IP, oppure di una variazione della metrica della sua interfaccia, ma non di cambio della topologia di rete, non viene ricalcolato l’intero albero SPF, ma solo identificata l’eventuale presenza su un altro router del prefisso IP, o la sua assenza. Questo comportamento viene indicato come Partial Route Calculation (PRC) ed è alla base della maggiore scalabilità di IS-IS rispetto ad OSPF. Si noti che un ricalcolo dell’intero albero SPF, è necessario solo in caso di cambio di topologia della rete e/o di cambio delle metriche associate ai collegamenti.
La situazione in OSPF (o meglio, in OSPFv2), è un po’ diversa. Infatti in OSPFv2, a fare da trigger per l’esecuzione dell’algoritmo SPF è la ricezione di LSA di tipo 1 e tipo 2, mentre nel caso di ricezione di LSA di tipo 3, 4, 5, 7, il ricalcolo completo non viene eseguito, ma viene eseguito un Partial Route Calculation. Questo perché i LSA di tipo 1 e 2 incorporano sia informazioni topologiche, che informazioni sulle stub network.
Ciò significa che quando una stub network viene annunciata attraverso un LSA di tipo 1 (o tipo 2 nel caso di prefissi di segmenti broadcast con router dove è attivo un processo OSPF), OSPF ricalcola inutilmente l’intero albero SPF. Questo è uno degli aspetti negativi di OSPFv2, che è stato sanato successivamente con OSPFv3, dove, come per IS-IS, vi è un disaccoppiamento totale tra topologia logica della rete e stub network. Infatti in OSPFv3, le stub network sono annunciate da LSA separati (Intra-Area-Prefix-LSA, LS type = 0x2009), e non più da LSA di tipo 1 o 2, che invece annunciano solo variazioni di topologia.
Tutto ciò, genera in OSPFv2 l’interessante quesito pratico, riportato nella figura seguente: come è meglio annunciare una stub network, tramite LSA di tipo 1 oppure tramite LSA di tipo 5 (o 7 se il router è parte di un’area NSSA) ? (NOTA: le configurazioni della figura sono relative all'IOS XR)

Il problema con il primo approccio è che le stub network annunciate via LSA di tipo 1 comportano un inutile ricalcolo dell’intero albero SPF, mentre se la stessa stub network fosse annunciata attraverso LSA di tipo 5 o 7, verrebbe eseguito un PRC.
Il rovescio della medaglia è, utilizzando LSA di tipo 5, una possibile maggiore occupazione di memoria. Ad esempio, se un router avesse 25 stub network, la dimensione del LSA di tipo 1 aumenterebbe di 300 byte, mentre nel caso di utilizzo del comando "redistribute connected" verrebbero generati 25 LSA di tipo 5, per un totale 1.100 byte. In realtà, se fosse possibile aggregare i 25 prefissi esterni, o una parte di essi, si potrebbe avere una occupazione di memoria minore.
Nelle reti di piccole dimensioni probabilmente questa alternativa non da luogo a differenze sensibili, per cui quale sia il metodo utilizzato per annunciare le stub network poco importa. In reti di grandi dimensioni invece questo è un altro trade-off da valutare nel progetto complessivo della rete.
NOTA: nel caso particolare in cui le stub network siano interfacce di Loopback, è più conveniente utilizzare il primo metodo. Infatti, poiché queste non vanno mai fuori servizio, non cambiano di stato, e quindi non devono essere mai riannunciate.
CONCLUSIONI
Con questo post, ho illustrato un altro tassello sulle metodiche per ridurre i tempi di convergenza dei protocolli Link State. Non credo sia questo un aspetto dirimente del problema, perché i tempi di calcolo dell'algoritmo SPF anche in reti di grandi dimensioni vanno via via riducendosi. Però tutto aiuta ...
Il prossimo post su questo argomento sarà sul "spf per-prefix prioritization", ossia sui meccanismi che consentono ai prefissi più importanti di essere trattati con precedenza rispetto a quelli meno importanti (e che quindi finiscono nella RIB e FIB prima di altri prefissi !).
Pubblicato in
ReissBlog
Etichettato sotto
Giovedì, 30 Aprile 2015 08:22
DMVPN FASE 2
PREMESSA: ho scritto questo post per completezza e per mostrare l'evoluzione completa del modello DMVPN nelle varie fasi. E poi anche perché vi sono in produzione DMVPN basate su questo modello. Ma sappiate che questo modello è stato migliorato notevolmente con la Fase 3, per cui se dovete creare una DMVPN ex-novo, con necessità di scambio di traffico diretto Spoke-Spoke, è fortemente consigliato utilizzare il modello DMVPN fase 3, che tratterò diffusamente in un prossimo post.
Questo post è il seguito dei precedenti dedicati al modello DMVPN. Ricordo dai post precedenti, che la caratteristica fondamentale del modello DMVPN Fase 2 è la possibilità che hanno i router Spoke di scambiare traffico direttamente, senza passare dai router Hub.
Le configurazioni di base del protocollo NHRP sono le stesse già viste per il modello DMVPN Fase 1. Per quanto riguarda invece tunnel mGRE e routing vi sono delle differenze importanti.
Abbiamo visto nel modello DMVPN Fase 1 che sui router Spoke è sufficiente configurare tunnel GRE p2p e solo sui router Hub è necessario attivare tunnel mGRE. Nel modello DMVPN Fase 2 invece, è necessario configurare tunnel mGRE anche sui router Spoke. Il perché è abbastanza intuitivo: un router Spoke deve poter scambiare traffico anche con altri router Spoke, e quindi a meno che non si voglia attivare tunnel p2p verso ciascun altro Spoke, cosa assolutamente non scalabile, è necessario e opportuno anche qui utilizzare tunnel mGRE.
Per quanto riguarda il routing invece, un aspetto chiave da considerare è che quando un router Hub propaga verso i router Spoke un annunci ricevuto da un router Spoke, deve conservare il Next-Hop originale. In altre parole, sulla tabella di routing dei router Spoke, i prefissi raggiungibili da altri router Spoke devono avere come Next-Hop un indirizzo IP del router Spoke che li annuncia. Ma questo genera un problema molto interessante: come fa un router Spoke a conoscere l'indirizzo NBMA corrispondente all'indirizzo logico del Next-Hop ? Infatti, un router Spoke di norma, attraverso il protocollo NHRP registra la sua associazione <Indirizzo logico ; Indirizzo NBMA> al NHS, ma il NHS non comunica agli altri Spoke, via NHRP, le associazioni registrate. Per fare un parallelo, lo stesso problema si ha su un segmento Ethernet: cosa avviene quando un Host sul segmento deve inviare un pacchetto IP a un altro Host dello stesso segmento (il cosiddetto routing diretto !) ? L'Host origine non conosce l'indirizzo fisico (MAC) corrispondente all'indirizzo logico (IP) dell'Host destinazione. E come tutti sappiamo, il problema è risolto dal protocollo ARP, che è attivato dall'invio del primo pacchetto IP. Bene, nel modello DMVPN Fase 2 avviene una cosa simile, solo che il ruolo del protocollo ARP è svolto dal protocollo NHRP e il trigger del messaggio NHRP Resolution Request è dato dalla tabella CEF.
La rete test che utilizzerò è la stessa dei post precedenti sull'argomento, e riportata nella figura seguente.

I router sono tutti equipaggiati con IOS 12.4(11)T.
ROUTING VIA EIGRP
Per questo test, nell'ottica di focalizzare meglio l'attenzione sul meccanismo di funzionamento del modello DMVPN Fase 2, non utilizzerò il router H2.
L'utilizzo di EIGRP richiede, rispetto al modello DMVPN Fase 1, l'aggiunta sul router Hub di un comando che consenta di preservare il Next-Hop originale. Il comando è "no ip next-hop-self eigrp numero-AS". Inoltre:
- Non è possibile, sui router Hub, effettuare aggregazione di prefissi con il comando "ip summary-address eigrp numero-AS prefisso maschera" a livello interfaccia "tunnel X", altrimenti il prefisso aggregato verrebbe annunciato con il Next-Hop del router Hub, impedendo la comunicazione diretta Spoke-Spoke. In particolare, non è possibile utilizzare il comando "ip summary-address eigrp numero-AS 0.0.0.0 0.0.0.0" per generare una default-route, altrimenti non verrebbero annunciati dal router Hub i prefissi ricevuti dai router Spoke.
- Ricordare di disabilitare sui soli router Hub lo split-horizon con il comando "no ip split-horizon eigrp numero-AS".
- Ricordare che è buona pratica abilitare la funzionalità EIGRP Stub sui router Spoke.
Qualora si volesse utilizzare la default-route per raggiungere dai router Spoke i prefissi "dietro" ai router Hub, è possibile configurarla direttamente sui router Spoke attraverso una normale default-route statica. Un esempio classico è la raggiungibilità dei prefissi off-net, per i quali potrebbe essere richiesto il passaggio sui router Hub (es. i prefissi Internet, quando i router Hub svolgono il ruolo di Internet Gateway).
Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. La configurazione di SP2 è analoga e viene lasciata come esercizio.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
no ip next-hop-self eigrp 200
no ip split-horizon eigrp 200
ip nhrp map multicast dynamic
ip nhrp network-id 200
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router eigrp 200
no auto-summary
network 20.0.0.0
network 50.0.0.0
hostname SP1
!
interface Tunnel1
ip address 20.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.1
ip nhrp map 20.0.0.11 172.16.1.1
ip nhrp nhs 20.0.0.11
ip nhrp network-id 200
ip nhrp holdtime 120
ip nhrp registration timeout 90
tunnel source FastEthernet2/0
tunnel mode gre multipoint
!
router eigrp 200
no auto-summary
network 20.0.0.0
network 50.0.0.0
eigrp stub
!
ip route 0.0.0.0 0.0.0.0 Tunnel1
Si noti che le interfacce "tunnel X" configurate sui router Spoke non hanno alcun comando relativo a EIGRP. Il risultato della configurazione è che il router Spoke SP1 vede il prefisso 50.0.12.0/24 annunciato dal router SP2, con Next-Hop 20.0.0.2, ossia l'indirizzo IP logico dell'interfaccia tunnel di SP2.
SP1# show ip route 50.0.12.0
Routing entry for 50.0.12.0/24
Known via "eigrp 200", distance 90, metric 310172416, type internal
Redistributing via eigrp 200
Last update from 20.0.0.2 on Tunnel1, 00:00:27 ago
Routing Descriptor Blocks:
* 20.0.0.2, from 20.0.0.11, 00:00:27 ago, via Tunnel1
Route metric is 310172416, traffic share count is 1
Total delay is 1005000 microseconds, minimum bandwidth is 9 Kbit
Reliability 255/255, minimum MTU 1472 bytes
Loading 1/255, Hops 2
Però a questo punto sorge un problema: SP1 non ha un percorso valido verso il Next-Hop 20.0.0.2 (SP2) poiché SP2 ha registrato la sua associazione <Indirizzo logico ; Indirizzo NBMA> al NHS H1, il quale non ha propagato questa informazione a SP1. Ciò si evince facilmente dalla tabella CEF su SP1, che mostra per il prefisso 50.0.12.0/24 una "invalid adjacency":
SP1# show ip cef 50.0.12.0
50.0.12.0/24, version 34, epoch 0
0 packets, 0 bytes
via 20.0.0.2, Tunnel1, 0 dependencies
next hop 20.0.0.2, Tunnel1
invalid adjacency
La stessa tabella CEF, per il Next-Hop 20.0.0.2 mostra invece una "glean adjacency":
SP1# show ip cef 20.0.0.2
20.0.0.0/24, version 19, epoch 0, attached, connected
0 packets, 0 bytes
via Tunnel1, 0 dependencies
valid glean adjacency
Una "glean adjacency" indica che il Next-Hop 20.0.0.2 non è ancora stato risolto, ossia che SP1 non ha un'associazione <Indirizzo logico ; Indirizzo NBMA> per l'indirizzo logico 20.0.0.2. Il problema è che con il CEF abilitato, i messaggi NHRP Resolution Request sono inviati per la risoluzione del Next-Hop e non del prefisso 50.0.12.0/24. Il trigger del messaggio NHRP Resolution Request si ha sul piano dati, quando viene inviato il primo pacchetto dati verso un Host del prefisso 50.0.12.0/24 (la stessa cosa avviene con l'ARP, l'ARP Request è inviato non appena un Host sorgente tenta di inviare un pacchetto IP verso l'Host destinazione; solo dopo la ricezione dell'ARP Reply il pacchetto IP viene effettivamente veicolato verso la destinazione).
Per inviare un primo pacchetto a un Host del prefisso 50.0.12.0/24, ho utilizzato un banale traceroute (NOTA: avrei potuto utilizzare anche un semplice ping, ma fra poco capirete perché ho preferito utilizzare un traceroute):
SP1# traceroute 50.0.12.12
Type escape sequence to abort.
Tracing the route to 50.0.12.12
1 20.0.0.11 48 msec 8 msec 4 msec
2 20.0.0.2 14 msec * 8 msec
Come si può notare, i pacchetti IP del traceroute seguono il percorso attraverso il router Hub H1, per arrivare a destinazione. Potrebbe a questo punto venire il sospetto che c'è qualche errore di configurazione, poiché siamo in presenza di un modello DMVPN Fase 2. In realtà, come sarà visto tra poco, non è così, solo il primo pacchetto passa attraverso il router Hub.
Vediamo ora le associazioni <Indirizzo logico ; Indirizzo NBMA> presenti sul router SP1, prima e dopo l'esecuzione del traceroute:
Prima dell'esecuzione del traceroute:
SP1# show ip nhrp
20.0.0.11/32 via 20.0.0.11, Tunnel1 created 00:21:21, never expire
Type: static, Flags: nat used
NBMA address: 172.16.1.1
Dopo l'esecuzione del traceroute:
SP1# show ip nhrp
20.0.0.1/32 via 20.0.0.1, Tunnel1 created 00:07:31, expire 00:01:35
Type: dynamic, Flags: router unique nat local
NBMA address: 10.1.11.2
(no-socket)
20.0.0.2/32 via 20.0.0.2, Tunnel1 created 00:07:31, expire 00:01:21
Type: dynamic, Flags: router nat used
NBMA address: 10.1.11.6
20.0.0.11/32 via 20.0.0.11, Tunnel1 created 00:21:21, never expire
Type: static, Flags: nat used
NBMA address: 172.16.1.1
A questo punto, la tabella CEF mostra un'adiacenza valida sia per il prefisso 50.0.12.0/24 che per il Next-Hop 20.0.0.2:
SP1# show ip cef 50.0.12.0
50.0.12.0/24, version 34, epoch 0
0 packets, 0 bytes
via 20.0.0.2, Tunnel1, 0 dependencies
next hop 20.0.0.2, Tunnel1
valid adjacency
SP1# show ip cef 20.0.0.2
20.0.0.2/32, version 35, epoch 0, connected
0 packets, 0 bytes
via 20.0.0.2, Tunnel1, 0 dependencies
next hop 20.0.0.2, Tunnel1
valid adjacency
E infine, eseguiamo di nuovo il traceroute verso l'indirizzo IP 50.0.12.12:
SP1# traceroute 50.0.12.12
Type escape sequence to abort.
Tracing the route to 50.0.12.12
1 20.0.0.2 120 msec * 104 msec
Come si può notare, il traffico da SP1 verso l'indirizzo IP 50.0.12.12 non passa attraverso l'Hub H1, ma segue un percorso diretto SP1-->SP2. In particolare, i pacchetti IP vengono incapsulati un tunnel GRE con indirizzo IP sorgente coincidente con quello dell'interfaccia FastEthernet2/0 (= 10.1.11.2) e indirizzo IP destinazione l'indirizzo NBMA 10.1.11.6, corrispondente all'indirizzo logico di SP2 20.0.0.2. Quest'ultimo indirizzo viene dedotto dalla tabella delle associazioni <Indirizzo logico ; Indirizzo NBMA> presenti sul router SP1, e ottenute attraverso il protocollo NHRP.
E' importante notare che, come avviene con gli entry di una ARP Cache, anche le associazioni <Indirizzo logico ; Indirizzo NBMA> hanno una scadenza, che nell'esempio è 120 sec (valore definito via configurazione). Ciò significa che passati 120 secondi senza traffico tra SP1 e SP2, il primo pacchetto SP1-->SP2 successivo alla scadenza passa per H1, e quindi reinizia tutto il processo descritto sopra.
Concludendo, per abilitare EIGRP in uno scenario DMVPN fase 2, è necessario utilizzare i seguenti accorgimenti:
- Disabilitare sui router Hub, con il comando "no ip next-hop-self eigrp numero-AS", il "Next-Hop self" automatico dell'EIGRP.
- Disabilitare sui router Hub lo split-horizon con il comando "no ip split-horizon eigrp numero-AS".
- Non effettuare sui router Hub aggregazione di prefissi con il comando "ip summary-address eigrp ..." a livello interfaccia "tunnel X".
- Abilitare la funzionalità EIGRP Stub sui router Spoke.
Inoltre, per una soluzione più scalabile:
5. Configurare sui router Spoke una default-route statica verso i router Hub, per il traffico Spoke-->Hub.
ROUTING VIA OSPF
OSPF non è un protocollo consigliato per il modello DMVPN, per le ragioni che ho esposto nel post "DMVPN Fase 1 - Parte II". Però molti networker hanno familiarità con OSPF, e anche se questo non è molto scalabile in questo ambito, nelle reti di medie dimensioni ha una sua ragion d'essere.
Una limitazione di OSPF, oltre agli aspetti legati alla scalabilità, è di tipo architetturale: non è possibile avere più di due Hub, di cui uno avrà il ruolo di DR e l'altro di BDR. Topologie sofisticate come gerarchie di Hub, con OSPF non possono essere implementate.
Per preservare il Next-Hop, l'accorgimento principale da utilizzare è scegliere la modalità "broadcast" di OSPF su reti NBMA. E poi, è necessario fare in modo che i due Hub siano eletti DR e BDR. Ma questo è semplice, basta assegnare la priorità 0 alle interfacce tunnel dei router Spoke.
Infine, anche qui, come detto per EIGRP, per raggiungere prefissi "dietro" i router Hub è possibile configurare sui router Spoke delle default-route statiche verso gli Hub.
Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. Come sempre, le configurazioni di H2 e SP2 sono analoghe e vengono lasciate come esercizio. Per semplicità, anche qui nella configurazione ho omesso il comando per l'autenticazione dei messaggi NHRP.
hostname SP1
!
interface Tunnel1
ip address 20.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.1
ip nhrp map 20.0.0.11 172.16.1.1
ip nhrp map multicast 172.16.1.2
ip nhrp map 20.0.0.12 172.16.1.2
ip nhrp network-id 200
ip nhrp holdtime 120
ip nhrp nhs 20.0.0.11
ip nhrp nhs 20.0.0.12
ip nhrp registration timeout 90
ip ospf network broadcast
ip ospf priority 0
tunnel source FastEthernet2/0
tunnel mode gre multipoint
!
router ospf 123
router-id 20.1.1.1
network 20.0.0.0 0.0.0.255 area 1
redistribute connected subnets
!
ip route 0.0.0.0 0.0.0.0 Tunnel1
Si noti che nella configurazione del protocollo NHRP, sono stati definiti come NHS entrambi i router Hub, e di conseguenza è stato definito un mapping statico <Indirizzo logico ; Indirizzo NBMA> per entrambi i router Hub. Lo stesso, il mapping dei pacchetti multicast è stato abilitato per entrambi i router Hub (comandi "ip nhrp map multicast ..."). Per la configurazione del processo OSPF valgono le stesse considerazioni sul tipo di area e sulla modalità degli annunci delle reti direttamente connesse, già fatte nel post "DMVPN Fase 1 - Parte II".
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp map multicast 172.16.1.2
ip nhrp map 20.0.0.12 172.16.1.2
ip nhrp network-id 200
ip ospf network broadcast
ip ospf priority 100
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router ospf 123
router-id 20.0.0.11
network 20.0.0.0 0.0.0.255 area 1
Si noti che nella configurazione del protocollo NHRP, è stato definito un mapping statico <Indirizzo logico ; Indirizzo NBMA> verso l'altro router Hub. Lo stesso, il mapping dei pacchetti multicast è stato abilitato per entrambi i router Hub (comandi "ip nhrp map multicast ...").
Il risultato della configurazione è che i router Spoke e i due router Hub sono visti dal processo OSPF come appartenenti a un normale segmento broadcast, e quindi i router seguono le usuali regole di OSPF su reti broadcast. Ad esempio, le adiacenze viste da H1, che viene eletto DR poiché ho configurato il valore di priorità associata all'interfaccia tunnel su H2 pari a 10, sono quelle classiche:
H1# show ip ospf 123 neighbor
Neighbor ID Pri State Dead Time Address Interface
20.1.1.1 0 FULL/DROTHER 00:00:39 20.0.0.1 Tunnel11
20.1.1.2 0 FULL/DROTHER 00:00:39 20.0.0.2 Tunnel11
20.1.1.12 10 FULL/BDR 00:00:31 20.0.0.12 Tunnel11
Il prefisso 50.0.12.0/24 è visto sulla tabella di routing di SP1 con Next-Hop 20.0.0.2 (SP2):
SP1# show ip route ospf 123
50.0.0.0/24 is subnetted, 2 subnets
O 50.0.12.0 [110/11112] via 20.0.0.2, 00:01:46, Tunnel1
A questo punto, tutte le considerazioni fatte nella sezione precedente circa la tabella CEF e la risoluzione del Next-Hop, valgono esattamente allo stesso modo anche qui. Concludendo, per abilitare OSPF in uno scenario DMVPN Fase 2, è necessario utilizzare i seguenti accorgimenti:
- Abilitare sulle interfacce "tunnel X" di tutti i router, la modalità OSPF su reti NBMA "broadcast" (comando "ip ospf network broadcast").
- Definire sui router Spoke una priorità nulla per l'elezione di DR e BDR.
- (Opzionale) Configurare sui router Spoke delle default-route statiche verso i router Hub.
ROUTING VIA BGP
Infine il caro vecchio BGP. Qui valgono molte delle considerazioni già fatte per il modello DMVPN Fase 1. Qualora si decida di utilizzare il BGP, anche qui, come nel modello DMVPN Fase 1, la prima decisione da affrontare è se utilizzare sessioni iBGP o eBGP.
In teoria anche nel modello DMVPN Fase 2 si possono utilizzare entrambi i tipi. Personalmente io propendo per l'utilizzo di sessioni iBGP per le seguenti ragioni:
- E' richiesto l'utilizzo di un solo numero di AS. Per contro, con sessioni eBGP è necessario utilizzare più numeri di AS, al limite un numero di AS per ciascun router.
- L'utilizzo del trucchetto dei BGP Dynamic Neighbor diviene molto più semplice, aumentando di molto la scalabilità della configurazione.
- Utilizzando sessioni iBGP è possibile sfruttare la funzionalità BGP Route Reflection, eleggendo (via configurazione) i router Hub come Route Reflector (RR) e i router Spoke come Route Reflector Client (RRC). Ricordo che i RR non cambiano il BGP Next-Hop quando riflettono gli annunci ai RRC, e questo è fondamentale per l'applicazione del modello DVPN Fase 2.
Vedremo che con il modello DMVPN Fase 3, alcune di queste ragioni verranno meno, per cui si ritornerà alle considerazioni fatte nel modello DMVPN Fase 1. Qualora sia necessario, per i router Spoke, utilizzare una default-route per raggiungere i prefissi "dietro" i router Hub, questa può essere tranquillamente inviata via BGP con il comando "neighbor <IP-RRC> default-originate".
Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. Come sempre, le configurazioni di H2 e SP2 sono analoghe e vengono lasciate come esercizio. Per semplicità, anche qui nella configurazione ho omesso il comando per l'autenticazione dei messaggi NHRP.
hostname SP1
!
La configurazione dell'interfaccia "tunnel 1" è identica a quella già illustrata per il protocollo OSPF (senza ovviamente i comandi relativi a OSPF !).
!
router bgp 65101
redistribute connected route-map ALLOW-DC
neighbor 20.0.0.11 remote-as 65101 ! sessione iBGP verso il RR H1
neighbor 20.0.0.12 remote-as 65101 ! sessione iBGP verso il RR H2
!
ip prefix-list NET-DC seq 5 permit 50.0.0.0/16 le 32
!
route-map ALLOW-DC permit 10
match ip address prefix-list NET-DC
La configurazione del BGP su SP1 è abbastanza classica e può essere utilizzata come template di configurazione per tutti i router Spoke. L'unica cosa che va valutata è la replicabilità della prefix-list, ma ripeto ciò che ho detto in un precedente post, se uno ha fatto un piano di numerazione serio ... (per gli esperti di BGP, una possibile alternativa è utilizzare un filtro basato sull'AS_PATH: ip as-path access-list 1 permit ^$ ; neighbor <IP-peer> filter-list 1 out).
Vediamo ora la configurazione del router Hub H1.
Vediamo ora la configurazione del router Hub H1.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp map 20.0.0.12 172.16.1.2
ip nhrp map multicast 172.16.1.2
ip nhrp network-id 200
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router bgp 65101
neighbor 20.0.0.12 remote-as 65101
neighbor SPOKE peer-group
neighbor SPOKE remote-as 65101
neighbor SPOKE route-reflector-client
neighbor SPOKE default-originate
bgp listen limit 200
bgp listen range 20.0.0.0/24 peer-group SPOKE
La configurazione di H1 utilizza i già citati BGP Dynamic Neighbors. Per chi non ricordasse il loro funzionamento e le loro proprietà di scalabilità, invito alla rilettura del post "DMVPN Fase 1 - Parte II".
Con queste configurazioni, sulla tabella BGP di H1 compaiono i prefissi annunciati dai router Spoke (due annunci per ciascun prefisso, uno proveniente da un RRC e l'altro proveniente da H2 poiché non ho configurato un BGP Cluster-ID comune):
H1# show bgp ipv4 unicast
BGP table version is 3, local router ID is 192.168.1.1
... < legenda omessa > ...
Network Next Hop Metric LocPrf Weight Path
* i 50.0.11.0/24 20.0.0.1 0 100 0 ?
*>i 20.0.0.1 0 100 0 ?
* i 50.0.12.0/24 20.0.0.2 0 100 0 ?
*>i 20.0.0.2 0 100 0 ?
Su SP1 la tabella BGP è la seguente:
SP1# show bgp ipv4 unicast
BGP table version is 4, local router ID is 50.0.11.11
... < legenda omessa > ...
Network Next Hop Metric LocPrf Weight Path
*>i 0.0.0.0 20.0.0.11 0 100 0 i
* i 20.0.0.12 0 100 0 i
*> 50.0.11.0/24 0.0.0.0 0 32768 ?
*>i 50.0.12.0/24 20.0.0.2 0 100 0 ?
* i 20.0.0.2 0 100 0 ?
Come si può notare, il BGP Next-Hop per il prefisso 50.0.12.0/24 è 20.0.0.2 (SP2), così come richiesto dal modello DMVPN Fase 2. Ciò è confermato anche dal contenuto (parziale) della tabella di routing:
SP1# show ip route bgp
50.0.0.0/24 is subnetted, 2 subnets
B 50.0.12.0 [200/0] via 20.0.0.2, 00:25:50
B* 0.0.0.0/0 [200/0] via 20.0.0.11, 00:25:50
A questo punto, anche qui possiamo ripetere tutte le considerazioni sulla tabella CEF e sui messaggi NHRP già illustrate con il protocollo EIGRP. In realtà sulla tabella CEF c'è una minima differenza, comunque inifluente. Il CEF infatti, prima dell'invio del primo pacchetto al router Spoke, per gli annunci BGP considera sempre il Next-Hop di tipo ricorsivo e quindi l'adiacenza è sempre di tipo "glean" e mai "invalid", come invece accade per EIGRP e OSPF.
SP1# show ip cef 50.0.12.12
50.0.12.0/24, version 29, epoch 0
0 packets, 0 bytes
via 20.0.0.2, 0 dependencies, recursive
next hop 20.0.0.2, Tunnel1 via 20.0.0.0/24
valid glean adjacency
Anche qui, dopo l'invio del primo pacchetto, l'adiacenza CEF diventa "valid":
SP1# show ip cef 50.0.12.12
50.0.12.0/24, version 29, epoch 0
0 packets, 0 bytes
via 20.0.0.2, 0 dependencies, recursive
next hop 20.0.0.2, Tunnel1 via 20.0.0.2/32
valid adjacency
Infine, per verificare che il traffico Spoke-Spoke fluisce effettivamente senza passare attraverso il router Hub H1, si può eseguire un classico traceroute:
SP1# traceroute 50.0.12.12 source 50.0.11.11
Type escape sequence to abort.
Tracing the route to 50.0.12.12
1 20.0.0.2 84 msec * 80 msec
CONCLUSIONI
In questo post ho cercato di illustrare l'utilizzo degli stessi tre ben noti protocolli di routing al modello DMVPN Fase 2. Sulla scelta valgono le stesse considerazioni già illustrate nel post "DMVPN Fase 1 - Parte II". Io non avrei dubbi, comunque l'unico protocollo che mi sento di sconsigliare è OSPF.
Pubblicato in
ReissBlog
Etichettato sotto
Venerdì, 17 Aprile 2015 20:21
LIBRO "IS-IS: DALLA TEORIA ALLA PRATICA" : CAPITOLO 7
Finalmente, dopo 6 capitoli di "poesia" (che comunque non è ancora finita ...), con questo capitolo 7 iniziamo un po' di "prosa".
Infatti, il capitolo 7 del libro su IS-IS illustra le configurazioni di base per implementare IS-IS nelle piattaforme Cisco. Come noto Cisco utilizza varie versioni del suo IOS, in particolare IOS base, IOS XE, NX-OS, IOS XR, e forse anche qualche altra versione minore. Le prime tre versioni hanno comandi identici, mentre l'IOS XR adotta uno stile di configurazione abbastanza diverso.
Nel capitolo ho introdotto le configurazioni relative a IOS, IOS XE e IOS XR. La versione NX-OS non è citata nel capitolo, ma le configurazioni sono pressoché identiche a quelle dell'IOS e IOS XE.
Come detto, il capitolo illustra l’implementazione base di IS-IS. Altre configurazioni di aspetti avanzati saranno viste nei capitoli 9, 10 e 11. Ulteriori dettagli si trovano nella documentazione ufficiale Cisco delle varie piattaforme, reperibile facilmente sul web.
A grandi linee, il capitolo illustra:
- I comandi di configurazione di base (assegnazione del NET, abilitazione delle interfacce a IS-IS, scelta del tipo di IS, elezione del DIS, definizione delle metriche, ecc.).
- I comandi per configurare l’aggregazione dei prefissi e le modalità di configurazione.
- La procedura di configurazione del Route Leaking.
- I comandi di tipo “show …” e “debug …” per la verifica della configurazione e la soluzione di problemi di troubleshooting.
Buona lettura !!!
Coming up next ... un post su DMVPN fase 2 e successivamente un post sulla convergenza dei protocolli link-state che tratta dei metodi di ottimizzazione nella determinazione dell'albero SPF.
Pubblicato in
ReissBlog
Etichettato sotto
Venerdì, 03 Aprile 2015 06:25
DMVPN FASE 1 - PARTE II
Questo post è il seguito del post precedente "DMVPN FASE 1 - PARTE I". Come citato alla fine di quel post, per completare l'implementazione del modello DMVPN è necessario abilitare un protocollo di routing IP. E qui nascono problematiche interessanti come, quale protocollo scegliere, come configurarlo ? Nelle applicazioni pratiche sono tre i protocolli di interesse: EIGRP, OSPF e BGP.
NOTA 1: in teoria può essere utilizzato anche il RIP, ma come noto questo vecchio protocollo ha due ordini di problemi: convergenza lenta e diametro delle rete limitato.
NOTA 2: tra i classici protocolli IGP, l'IS-IS non è supportato nel modello DMVPN. Secondo la documentazione Cisco, la ragione per cui IS-IS non è applicabile nel modello DMVPN è che i messaggi IS-IS sono trasportati direttamente dal Livello 2 e non da pacchetti IP ! La frase testuale che ho letto in una presentazione al Cisco Live 2013 dal titolo "Advanced Concepts of DMVPN", è la seguente: "IS-IS cannot be used since it doesn’t run over IP".
Questa ragione in teoria non sta in piedi poiché nei tunnel GRE è possibile trasportare di tutto, anche messaggi IS-IS, ma Cisco forse non aveva voglia di implementare un comando del tipo "ip nhrp map iso [dynamic | indirizzo NBMA]" ... . D'altra parte, nei tunnel GRE p2p, i messaggi IS-IS viaggiano tranquillamente, anche nei router Cisco.
Ciascuno di questi protocolli va valutato rispetto a caratteristiche importanti come la scalabilità della configurazione (nelle applicazioni pratiche ci si può tranquillamente trovare davanti a reti con centinaia, se non migliaia di router Spoke) e soprattutto la velocità di convergenza.
In questo post, partendo dalla rete del post precedente, che riporto per completezza, illustrerò come utilizzare i tre protocolli EIGRP, OSPF e BGP, mettendo in evidenza gli aspetti di scalabilità e convergenza di ciascuna soluzione. In tutti i test successivi, utilizzerò una topologia Dual DMVPN. La rete test è la stessa del post precedente, che riporto qui per completezza.
ROUTING VIA EIGRP
L'abilitazione di EIGRP sulla rete test richiede un solo accorgimento fondamentale: disabilitare lo split-horizon sulle interfacce "tunnel X" dei router Hub. Questo è un aspetto ben noto nel funzionamento di EIGRP su reti NBMA. La regola dello split-horizon, quando abilitata, impedisce ai router Hub di annunciare i prefissi ricevuti da un router Spoke, agli altri router Spoke. In altre parole, a ciascun router Spoke viene impedita la visibilità delle reti raggiungibili attraverso gli altri router Spoke.
In realtà non è sempre necessario disabilitare lo split-horizon sulle interfacce "tunnel X" dei router Hub. Poiché il modello DMVPN fase 1 non prevede la comunicazione diretta tra router Spoke, una soluzione molto semplice e altamente scalabile potrebbe quella di far generare ai router Hub una default-route EIGRP, rendendo così inutile la presenza sulla Tabella di Routing dei router Spoke, dei prefissi IP raggiungibili attraverso gli altri router Spoke. In questo caso, disabilitare lo split-horizon non comporta alcunché. Comunque, per tranquillità, considerato che nel modello DMVPN fase 2, come si vedrà (e come è intuitivo) è invece obbligatorio disabilitarlo, consiglio comunque, in uno scenario DMVPN, di disabilitare sempre lo split-horizon.
Un altro accorgimento classico da adottare, in presenza di topologie Hub-and-Spoke con protocollo di routing EIGRP, è abilitare la funzionalità EIGRP Stub sui router Spoke, per impedire che i router Spoke vengano utilizzati come transito per destinazioni raggiungibili attraverso i router Hub, nel caso di fuori servizio di uno dei due Hub.
Riporto di seguito le configurazioni dei router H1 e SP1 della rete Test. Come sempre, le configurazioni di H2 e SP2 sono analoghe e vengono lasciate come esercizio. Per semplicità, nella configurazione ho omesso il comando per l'autenticazione dei messaggi NHRP e sui router Spoke i comandi dei timer che regolano la registrazione delle associazioni <Indirizzo IP logico ; Indirizzo NBMA>.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
no ip split-horizon eigrp 200
ip nhrp map multicast dynamic
ip nhrp network-id 200
ip summary-address eigrp 200 0.0.0.0 0.0.0.0
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router eigrp 200
no auto-summary
network 20.0.0.0
network 50.0.0.0
!
Il comando "ip summary-address eigrp 200 0.0.0.0 0.0.0.0" consente di generare una default-route EIGRP, che viene inviata su tutte le adiacenze EIGRP stabilite attraverso l'interfaccia "tunnel 11". Si noti inoltre che, anche se non necessario a causa della generazione della default-route EIGRP, ho disabilito comunque sull'interfaccia "tunnel 11", lo split-horizon.
hostname SP1
!
interface Tunnel1
ip address 20.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.1
ip nhrp map 20.0.0.11 172.16.1.1
ip nhrp network-id 200
ip nhrp nhs 20.0.0.11
tunnel source FastEthernet2/0
tunnel destination 172.16.1.1
!
interface Tunnel11
ip address 30.0.0.1 255.255.255.0
ip nhrp map multicast 172.16.1.2
ip nhrp map 30.0.0.11 172.16.1.2
ip nhrp network-id 300
ip nhrp nhs 30.0.0.11
tunnel source FastEthernet2/0
tunnel destination 172.16.1.2
!
router eigrp 200
no auto-summary
network 20.0.0.0
network 30.0.0.0
network 50.0.0.0
eigrp stub
Si noti che le interfacce "tunnel X" configurate sui router Spoke non hanno alcun comando relativo a EIGRP. Si noti inoltre il comando "eigrp stub" all'interno del processo EIGRP, che abilita sul router Spoke SP1 la funzionalità EIGRP Stub. Ricordo che il comando "eigrp stub" consente di default l'annuncio dei prefissi direttamente connessi e delle summary route.
Il risultato della configurazione è che il router Spoke SP1 vede due Next-Hop per la default-route annunciata da EIGRP, i tunnel 1 e 11. Ciò significa che i due tunnel 1 e 11 sono utilizzati in Load Balancing.
SP1# show ip route eigrp
. . . < legenda omessa > . . .
Gateway of last resort is 30.0.0.11 to network 0.0.0.0
D* 0.0.0.0/0 [90/26882560] via 30.0.0.11, 00:00:58, Tunnel11
[90/26882560] via 20.0.0.11, 00:00:58, Tunnel1
Qualora si volesse utilizzare un tunnel come primario (ad esempio il tunnel 1) e l'altro come backup, è sufficiente aumentare il costo complessivo con cui SP1 vede la default-route attraverso il tunnel di backup (ad esempio il tunnel 11), oppure, in modo equivalente, diminuire il costo complessivo con cui SP1 vede la default-route attraverso il tunnel primario.
Per fare questo, ricordo che è buona regola agire sul parametro delay dell'interfaccia "tunnel X". Si potrebbe anche agire sul parametro bandwidth, ma questo è utilizzato anche da altri protocolli e funzioni (es. OSPF per il calcolo delle metriche, meccanismi di QoS, ecc.), per cui è bene non variarlo.
Il parametro delay associato all'interfaccia "tunnel X" si può visualizzare con il classico comando "show interface tunnel X". Ad esempio, per l'interfaccia "tunnel 11" si ottiene:
SP1#sh int tunnel 11 | i DLY
MTU 17916 bytes, BW 100 Kbit/sec, DLY 50000 usec,
da cui si evince che il parametro delay è pari a 50.000 microsec. Per aumentare questo valore, ad esempio per raddoppiarlo, si utilizza la seguente configurazione (NOTA: nella configurazione il nuovo valore va espresso in decine di microsec):
interface tunnel 11
delay 10000
Una identica configurazione andrebbe fatta sugli altri router Spoke. Il risultato che si ottiene è il seguente:
SP1# show ip route eigrp
. . . < legenda omessa > . . .
Gateway of last resort is 20.0.0.11 to network 0.0.0.0
D* 0.0.0.0/0 [90/26882560] via 20.0.0.11, 00:15:04, Tunnel1
Infine, per verificare che il traffico Spoke-Spoke fluisce effettivamente attraverso il router Hub H1, si può eseguire un classico traceroute:
SP1# traceroute 50.0.12.12 source 50.0.11.11
Type escape sequence to abort.
Tracing the route to 50.0.12.12
VRF info: (vrf in name/id, vrf out name/id)
1 20.0.0.11 34 msec 44 msec 37 msec
2 20.0.0.2 38 msec * 34 msec
"Et voilà", il gioco è fatto !!!
Concludendo, per abilitare EIGRP in uno scenario DMVPN fase 1, utilizzare i seguenti accorgimenti:
1) Disabilitare lo split-horizon sulle interfacce "tunnel X" dei router Hub.
2) Abilitare la funzionalità EIGRP Stub sui router Spoke.
Per una soluzione altamente scalabile:
3) Generare sui router Hub una default-route EIGRP verso i router Spoke. In questo caso non è necessario disabilitare lo split-horizon (ma magari fatelo comunque).
ROUTING VIA OSPF
Un secondo protocollo supportato dal modello DMVPN fase 1 è l'OSPF. Nella sua implementazione è però necessario fare molta attenzione agli aspetti di scalabilità. Tutti noi conosciamo la vecchia regoletta Cisco di non realizzare mai aree di più di 50 router. Dicamo che oggi questa regoletta può essere notevolmente ampliata ed arrivare anche ad aree di centinaia di router. Ma tenete conto che in una implementazione reale di un modello DMVPN, i router Spoke non sono mai delle "schegge", e anche i router Hub non sono certo i CRS !!! Quindi io farei molta attenzione ad utlizzare OSPF quando i router Spoke superano qualche centinaio.
Nel modello DMVPN fase 1 comunque qualche accorgimento interessante c'è. Innanzitutto, poiché siamo in presenza di OSPF su una rete NBMA, è necessario scegliere la modalità di funzionamento. La più semplice è in questo caso la point-to-multipoint, che è tra l'altro una modalità standard descritta nella RFC 2328 "OSPF Version 2". Le ragioni per il suo utilizzo sono che in questa modalità, ogni tunnel GRE viene trattato come fosse un collegamento punto-punto, e quindi non è necessario specificare manualmente i router vicini, né vi è bisogno di eleggere DR e BDR.
Un altro aspetto molto interessante, che ha un impatto molto importante sulla scalabilità, è la possibilità offerta dall'IOS Cisco di bloccare l'invio di LSA OSPF su una particolare interfaccia. Attenzione però, questo comporta un disallineamento dei LSDB all'interno dell'area, ma fortunatamente con una topologia Hub-and-Spoke questo non crea alcun problema. Infatti, disabilitando sui router Hub l'invio di LSA sull'interfaccia "tunnel X", si ha che i router Spoke non riceveranno informazioni sui prefissi raggiungibili dagli altri router Spoke. Ma il problema di connettività può essere risolto, come fatto con il protocollo EIGRP, con una default-route sui router Spoke verso i router Hub. Però attenzione a un aspetto. Se si disabilita sui router Hub l'invio dei LSA OSPF, non è possibile far generare ai router Hub una default-route OSPF. Questo perché la generazione avviene attraverso un LSA di tipo 5, che però non viene inviato se si disabilita sui router Hub l'invio dei LSA OSPF. La soluzione, benché un po' antipatica quando si ha che fare con centinaia di Spoke, è configurare delle default-route statiche sui router Spoke.
I comandi da eseguire sono quindi i seguenti:
1) Su tutte le interfacce "tunnel X" dei router Hub e Spoke, abilitare la modalità "point-to-multipoint" con il comando "ip ospf network point-to-multipoint".
2) Sulle interfacce "tunnel X" dei soli router Hub, disabilitare l'invia dei LSA OSPF con il comando "ip ospf database-filter all out".
3) Configurare sui router Spoke delle default-route statiche verso gli Hub, eventualmente di tipo floating (ossia, con diversa distanza amministrativa).
Riporto di seguito le configurazioni dei router H1 e SP1 della rete test. Come sempre, le configurazioni di H2 e SP2 sono analoghe e vengono lasciate come esercizio. Per semplicità, anche qui nella configurazione ho omesso il comando per l'autenticazione dei messaggi NHRP e sui router Spoke i comandi dei timer che regolano la registrazione delle associazioni <Indirizzo IP logico ; Indirizzo NBMA>.
hostname SP1
! NOTA: La configurazione delle interfacce "tunnel 1" e "tunnel 11" è identica a quella già illustrata per il protocollo EIGRP, con la sola differenza che è necessario aggiungere il comando "ip ospf network point-to-multipoint".
!
router ospf 100
router-id 1.1.1.1
redistribute connected subnets
network 20.0.0.0 0.0.0.255 area 1
network 30.0.0.0 0.0.0.255 area 1
!
ip route 0.0.0.0 0.0.0.0 Tunnel1
ip route 0.0.0.0 0.0.0.0 Tunnel11 10
Nella configurazione delle (floating) default-route statiche, ho ipotizzato di utilizzare come Hub primario H1, e di utilizzare H2 come Hub di backup. Qualora si volessero utilizzare le due default-route statiche in Load Balancing, è sufficente eliminare la distanza amministrativa nella seconda default-route.
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp network-id 200
ip ospf network point-to-multipoint
ip ospf database-filter all out
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router ospf 100
router-id 11.11.11.11
redistribute connected subnets
network 20.0.0.0 0.0.0.255 area 1
NOTA 1: sia nella configurazione dei router Spoke che in quella dei router Hub, per annunciare le reti direttamente connesse ho utilizzato un comando di redistribuzione, piuttosto che inserire i prefissi nel processo OSPF attraverso il comando "network ...". La ragione è che, come gli esperti di OSPF sanno, è molto più efficiente annunciare i prefissi via redistribuzione, piuttosto che inserirli nel processo OSPF. Anche se il risultato finale è equivalente.
NOTA 2: nella configurazione ho utilizzato un'area OSPF standard. A volte, per maggiore scalabilità, potrebbe essere conveniente configurare aree NSSA (non aree Stub, altrimenti non sarebbe possibile la redistribuzione sui router con almeno un'interfaccia nell'area !).
Con queste configurazioni, sulla tabella di routing di H1 compaiono i prefissi annunciati (via OSPF) dai router Spoke:
H1# show ip route ospf 100 | i O E2
O E2 50.0.11.0/24 [110/20] via 20.0.0.1, 00:18:42, Tunnel11
O E2 50.0.12.0/24 [110/20] via 20.0.0.2, 00:17:10, Tunnel11
Infine, anche qui, per verificare che il traffico Spoke-Spoke fluisce effettivamente attraverso il router Hub H1, si può eseguire un classico traceroute:
SP1# traceroute 50.0.12.12 source 50.0.11.11
Type escape sequence to abort.
Tracing the route to 50.0.12.12
VRF info: (vrf in name/id, vrf out name/id)
1 20.0.0.11 42 msec 44 msec 38 msec
2 20.0.0.2 48 msec 55 msec 42 msec
Concludendo, per abilitare OSPF in uno scenario DMVPN fase 1, utilizzare i seguenti accorgimenti:
1) Abilitare sulle interfacce "tunnel X" di tutti i router, la modalità OSPF su reti NBMA "point-to-multipoint".
2) Disabilitare sui soli router Hub la propagazione dei LSA OSPF.
3) Configurare sui router Spoke delle default-route statiche verso i router Hub, eventualmente di tipo floating.
Attenzione che il punto 3), purtroppo necessario se utilizzate il punto 2), richiede configurazioni di default-route statiche su tutti i router Spoke, che potrebbero essere centinaia. A onor del vero è comunque possibile utilizzare il "copia e incolla", con un template di configurazione unico.
ROUTING VIA BGP
Infine il caro vecchio BGP. Il BGP ormai viene utilizzato dappertutto, poteva mancare sul modello DMVPN ? Certamente no, e forse è anche l'alternativa migliore.
Qualora si decida di utilizzare il BGP, e nella prossima sezione cercherò di dare qualche motivazione, la prima decisione da affrontare è se utilizzare sessioni iBGP o eBGP. In teoria si possono utilizzare entrambi i tipi. Utilizzare sessioni iBGP è sicuramente molto più semplice nel caso di DMVPN Fase 1, mentre richiede qualche accorgimento aggiuntivo nel caso di DMVPN Fase 2. L'utilizzo di sessioni eBGP richiede l'assegnazione di un diverso numero di AS a ciascun router e questo potrebbe esere un rompicapo quando si ha che fare con centinaia o migliaia di Spoke. Ci sono vari modi di aggirare il problema, il BGP è ricco di funzioni che consentono di effettuare configurazioni scalabili. Poi, molto è legato alla diversa gestione del BGP Next-Hop sulle sessioni iBGP ed eBGP. Quello che voglio fare in questo post che tratta del DMVPN Fase 1, è applicare entrambe le soluzioni e valutare sul campo pregi e difetti.
Per utilizzare sessioni iBGP bisogna scegliere un (unico) numero di AS. Tipicamente si sceglie un numero di AS privato, ma non è obbligatorio. Poi bisogna configurare sessioni iBGP tra router Hub e router Spoke (non sessioni Spoke-Spoke). Per rendere la configurazione scalabile, è possibile utilizzare il trucchetto dei BGP Dynamic Neighbor, introdotto nelle versioni più recenti dell'IOS Cisco (nel JUNOS era presente da molto tempo). Questo fa risparmiare moltissime righe di configurazione e, aspetto più interessante, consente di introdurre nuovi Spoke senza alcuna nuova configurazione sugli Hub. Infine, poiché lo scenario è DMVPN Fase 1, è sufficiente, come già fatto per EIGRP e OSPF, far annunciare ai router Hub una default-route BGP verso i router Spoke.
Con il solito nostro scenario di rete, queste sono le configurazioni da effettuare sui router SP1 e H1:
hostname SP1
! La configurazione delle interfacce "tunnel 1" e "tunnel 11" è identica a quella già illustrata per il protocollo EIGRP.
!
router bgp 65101
redistribute connected route-map ALLOW-DC
neighbor 20.0.0.11 remote-as 65101
neighbor 30.0.0.11 remote-as 65101
!
ip prefix-list NET-DC seq 5 permit 50.0.0.0/16 le 32
!
route-map ALLOW-DC permit 10
match ip address prefix-list NET-DC
La configurazione del BGP è abbastanza classica e può essere utilizzata come template di configurazione per tutti i router Spoke. L'unica cosa che va valutata è la replicabilità della prefix-list, ma se uno ha fatto un piano di numerazione serio ...
hostname H1
!
interface Tunnel11
ip address 20.0.0.11 255.255.255.0
ip nhrp map multicast dynamic
ip nhrp network-id 200
tunnel source FastEthernet0/1
tunnel mode gre multipoint
!
router bgp 65101
neighbor SPOKE peer-group
neighbor SPOKE remote-as 65101
neighbor SPOKE default-originate
bgp listen limit 200
bgp listen range 20.0.0.0/24 peer-group SPOKE
La configurazione di H1 utilizza i già citati BGP Dynamic Neighbors. Il comando chiave è "bgp listen range 20.0.0.0/24 peer-group SPOKE", che richiede la definizione di un BGP peer-group. Il comando consente di accettare tutte le sessioni BGP aperte da altri BGP peer, che hanno come estremo remoto un indirizzo IP incluso nella subnet IP 20.0.0.0/24. Il comando "bgp listen limit 200" limita a 200 il numero di sessioni BGP accettate da H1. Non è obbligatorio, poiché vi è un limite comunque, dettato dalla "grandezza" della subnet IP. Però in alcune situazioni potrebbe risultare utile. Tutto dipende da quante sessioni BGP è in grado di supportare il router Hub (e per questo è necessario consultare la documentazione tecnica relativa alla piattaforma in uso).
Faccio notare che con l'utilizzo dei BGP Dynamic Neighbors, l'aggiunta di un nuovo Spoke, purché permessa dal limite massimo di sessioni BGP attivabili, non comporta sul router Hub alcuna riga di configurazione aggiuntiva.
Con queste configurazioni, sulla tabella di routing di H1 compaiono i prefissi annunciati (via iBGP) dai router Spoke:
H1# show ip route bgp
... < legenda omessa > ...
Gateway of last resort is not set
50.0.0.0/8 is variably subnetted, 4 subnets, 2 masks
B 50.0.11.0/24 [200/0] via 20.0.0.1, 00:11:55
B 50.0.12.0/24 [200/0] via 20.0.0.2, 00:23:10
Anche qui, per verificare che il traffico Spoke-Spoke fluisce effettivamente attraverso il router Hub H1, si può eseguire un classico traceroute:
SP1# traceroute 50.0.12.12 source 50.0.11.11
Type escape sequence to abort.
Tracing the route to 50.0.12.12
VRF info: (vrf in name/id, vrf out name/id)
1 20.0.0.11 37 msec 34 msec 26 msec
2 20.0.0.2 44 msec 41 msec 45 msec
Poi, utilizzando le classiche metriche del BGP è possibile implementare sui router Spoke scenari di tipo primario/backup, oppure si potrebbe abilitare il BGP multipath e utilizzare le due default-route disponibili in Load Balancing. Ma tutto questo esula da questo post, e lo lascio come eventuale esercizio.
Se invece di utilizzare sessioni iBGP si utilizzassero sessioni eBGP, la prima scelta da fare è se utilizzare numeri diversi di AS sugli Spoke o utilizzare lo stesso numero. Utilizzare numeri diversi ha due grossi svantaggi: la complessità di configurazione in presenza di un elevato numero di Spoke e l'impossibilità di utilizzare i BGP Dynamic Neighbors sugli Hub, poiché il loro utilizzo richiede che tutti i BGP peer dinamici appartengano allo stesso AS. Per cui mi sento di sconsigliare l'utilizzo di numeri di AS diversi. Secondo me la soluzione migliore, nel caso di sessioni eBGP, è di utilizzare un numero di AS per i router Hub e un diverso numero di AS per tutti gli Spoke. Nel nostro esempio utilizzerò i numeri 65101 per i router Hub e 65201 per i router Spoke. Le configurazioni del BGP su SP1 e H1 diventano così:
hostname SP1
!
router bgp 65201
redistribute connected route-map ALLOW-DC
neighbor 20.0.0.11 remote-as 65101
neighbor 30.0.0.11 remote-as 65101
!
ip prefix-list NET-DC seq 5 permit 50.0.0.0/16 le 32
!
route-map ALLOW-DC permit 10
match ip address prefix-list NET-DC
hostname H1
!
router bgp 65101
neighbor SPOKE peer-group
neighbor SPOKE remote-as 65201
neighbor SPOKE default-originate
bgp listen limit 200
bgp listen range 20.0.0.0/24 peer-group SPOKE
!
Quindi, con gli accorgimenti giusti, nel modello DMVPN Fase 1, utilizzare sessioni iBGP o eBGP, dal punto di vista della configurazione, non fa grandi differenze. Ad essere pignoli, un po' di differenza c'è sulla segnalazione. Mentre nel caso di sessioni iBGP, grazie alla nota regola dello split-horizon, gli Hub non annunciano ai router Spoke i prefissi annunciati dagli Spoke
Pubblicato in
ReissBlog
Etichettato sotto
Il tuo IPv4: 216.73.217.33
Newsletter
