

L’idea di base delle VLAN, come ben noto, è legata al concetto di separazione del traffico di Livello 2 (L2 traffic isolation), ossia della creazione di tante LAN virtualmente separate, definite sulla stessa infrastruttura fisica, con gli host appartenenti a VLAN diverse che non possono comunicare direttamente. L’infrastruttura fisica può essere costituita sia da un singolo switch Ethernet che da vari switch Ethernet interconnessi tra loro. In ogni caso, i dispositivi fisici dove vengono realizzate le VLAN sono dispositivi di Livello 2.
Lo sviluppo dei Data Center e delle tecnologie correlate, come ad esempio la possibilità di creare su un server fisico più “macchine virtuali” (da qui in poi abbreviate con l’acronimo VM, Virtual Machine) hanno messo a nudo le limitazioni del concetto di VLAN, primo fra tutti il fatto che il VLAN tag è di soli 12 bit, sicuramente insufficienti per le moderne applicazioni di tipo cloud pubblico, dove i clienti (detti tenant nella documentazione in inglese) sono in genere dell’ordine delle centinaia di migliaia, con ciascun cliente che potrebbe aver bisogno a sua volta di svariate VLAN.
Un altro limite, non però direttamente legato al concetto di VLAN, è che le VLAN realizzate su reti switched Ethernet utilizzano come protocollo per prevenire i loop L2 e i cosiddetti broadcast storm, il protocollo Spanning Tree (STP), di cui esistono delle varianti che ne hanno migliorato alcuni aspetti (es. velocità di convergenza, distribuzione del traffico, ecc.) ma che hanno lasciato inalterato il difetto fondamentale, che il protocollo funziona sul blocco di alcune porte, che così non possono essere utilizzate, sottraendo di fatto banda alla rete.
Chi mi conosce sa che penso tutto il male possibile dell’STP e in generale delle reti switched Ehternet, anzi, secondo me Ethernet sarebbe dovuto esistere solo come standard di livello fisico, dove ha avuto e ha i suoi indubbi meriti. Per il resto credo sia stata una iattura di proporzioni storiche per il mondo del Networking IP. E l’introduzione di recenti tecnologie, che ne stanno decretando la morte (finalmente !) mi stanno dando ragione (una di queste è proprio il concetto di VXLAN che vedremo in questo post). Ma argomentare su questo mi porterebbe facilmente a “partire per la tangente”, magari lo farò in post futuro.
Ciò premesso, un gruppo di note aziende del settore, tra cui Cisco, WMware, Red Hat, Citrix, e altre nel seguito, ha dato vita a una nuova tecnica di virtual overlay networking che consente di eliminare i due principali difetti delle VLAN così come le conosciamo oggi. Questa nuova tecnica, nota come VXLAN (Virtual eXtensible LAN), è stata standardizzata poco più di un anno fa (Agosto 2014) attraverso una RFC di tipo informational: RFC 7348 - Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks, ed è supportata da molte piattaforme, fisiche e virtuali.
Esistono altri tipi di tecniche di overlay networking alternative a VXLAN, come ad esempio NVGRE (Network Virtualization using Generic Routing Encapsulation) e STT (Stateless Transport Tunneling). Ma VXLAN è quella che sta ricevendo più consenso ed è implementata da tutti i principali costruttori di apparati di networking (es. Cisco, Juniper) ed in molti hypervisor (VMware ESX/NSX, KVM, ecc.).
FUNZIONAMENTO DI BASE
L’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete. La convenienza che la rete underlay sia una rete IP è dovuta alla diffusione pervasiva di questo tipo di reti, ormai diventate a tutti gli effetti vere e proprie reti multiservizio.
La rete logica è in questo caso un semplice segmento LAN, denominato da qui in poi segmento VXLAN. Le trame Ethernet generate dagli host (fisici o virtuali) appartenenti a un particolare segmento VXLAN, vengono trasportate da host a host utilizzando un incapsulamento di tipo MAC-in-UDP, i cui dettagli saranno visti in una prossima sezione. In pratica ciò che avviene è la sostituzione, per il trasporto delle trame Ethernet, della rete switched Ethernet con una semplice rete IP. I vantaggi che ne conseguono sono enormi:
- Non è più necessario il protocollo Spanning Tree.
- Vengono eliminati alla radice i (gravi) problemi causati dai broadcast storm.
- Aumenta la banda disponibile poiché non esistono più porte nello stato blocking.
- È possibile sfruttare meglio tutta la banda a disposizione utilizzando le tecniche di load balancing tipiche dei protocolli di routing IP.
La figura seguente illustra l’idea di base.
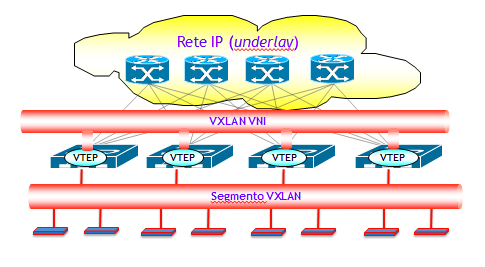
Nella figura compaiono due concetti chiave nel funzionamento delle VXLAN:
- VNI (VXLAN Network Identifier): è l’identificativo del segmento VXLAN. Praticamente sostituisce il VLAN tag come identificativo di un segmento LAN. Come si vedrà nel seguito nella sezione dedicata all’incapsulamento VXLAN, il VNI è di 24 bit, il che consente di definire più di 16,7 milioni di segmenti VXLAN (contro i 4096 (teorici) delle VLAN classiche).
- VTEP (VXLAN Tunnel End Point): è una funzione che gestisce l’origine e la terminazione, ossia l’incapsulamento e il decapsulamento, dei pacchetti VXLAN. Inoltre, si occupa di associare ciascun host a un determinato segmento VXLAN. Questa funzione può essere definita sia su una macchina fisica (es. un switch L2), oppure su un Hypervisor (es. VMware ESX/NSX, KVM, ecc.).
Poiché le trame Ethernet generate dagli host vengono incapsulate dalla funzione VTEP in pacchetti UDP/IP e a destinazione, sempre da una funzione VTEP vengono decapsulate, una VXLAN può anche essere pensata come uno schema di tunneling di trame di Livello 2 (trame Ethernet) su una rete di Livello 3 (la rete IP underlay). I tunnel sono di tipo stateless, che significa che ciascuna trama L2 viene incapsulata seguendo certe regole, e i router della rete underlay non hanno bisogno di alcuno stato aggiuntivo per espletare la funzione di trasporto. Inoltre, gli host si comportano come normali host connessi a un normale switch L2, e sono totalmente ignari della modalità di trasporto. La gestione dei VNI e dell’incapsulamento e decapsulamento delle trame L2 è demandata interamente alla funzione VTEP.
TRASPORTO DELLE TRAME L2 UNICAST
Vediamo ora con un esempio, come avviene il trasporto host-to-host (o VM-to-VM) delle trame Ethernet. La figura seguente riporta l’architettura generale di rete e il flusso delle trame e pacchetti IP scambiati.
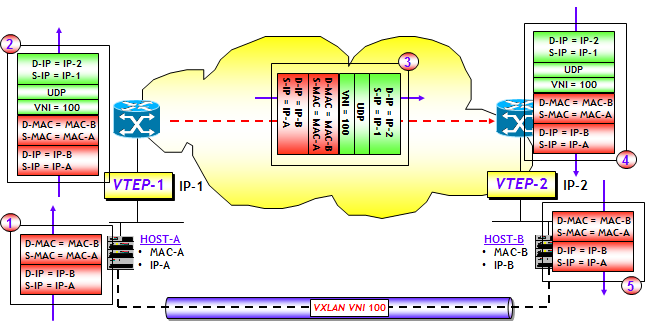
Nella figura, i due host HOST-A e HOST-B, entrambi parte del segmento VXLAN 100, comunicano tra loro attraverso il tunnel VXLAN realizzato tramite le due interfacce VTEP-1 e VTEP-2. I due host appartengono allo stesso segmento VXLAN identificato da VNI = 100, e alla stessa subnet IP. L’esempio assume che il MAC learning sia già avvenuto e le corrispondenti mappe MAC-to-VTEP esistano già su entrambe le VTEP. Questo è ovviamente un aspetto chiave del funzionamento sul quale nel seguito dovremo necessariamente far luce.
Per semplicità vedremo solo il “viaggio” di una trama Ethernet generata da HOST-A e diretta verso HOST-B. I passi evidenziati nella figura sono i seguenti:
- HOST-A genera una classica trama Ethernet con MAC destinazione MAC-B, ossia l’indirizzo MAC di HOST-B, e MAC sorgente MAC-A, ossia il proprio MAC. All’interno della trama Ethernet viene trasportato un pacchetto IP con indirizzo IP destinazione IP-B, ossia l’indirizzo IP di HOST-B, e indirizzo IP sorgente IP-A, ossia il proprio indirizzo IP (NOTA: vi siete mai chiesti perché un host è identificato da due indirizzi diversi ? Non sarebbe stato sufficiente un solo indirizzo ? Vi lascio con questo dubbio amletico. Io ho una mia opinione al riguardo, che tutto il mondo del networking sarebbe stato molto più semplice e lineare senza questo dualismo di indirizzi, ma argomentare su questo mi porterebbe fuori tema, lo farò in un prossimo post).
- La trama Ethernet generata da HOST-A viene inviata all’interfaccia VTEP-1, che provvedere a incapsularla in un pacchetto UDP/IP. I dettagli dell’incapsulamento saranno visti in una successiva sezione. Qui è sufficiente dire che alla trama originale viene aggiunto il VNI (un po’ allo stesso modo di come a una trama untagged viene aggiunto un VLAN tag, quando questa viene trasportata su un collegamento trunk), e quindi una classica intestazione UDP/IP. La porta destinazione UDP è una porta well-known mentre quella sorgente è determinata attraverso una funzione di hash (ulteriori dettagli nella sezione dedicata all’incapsulamento). Gli indirizzi IP sorgente e destinazione sono rispettivamente gli indirizzi IP delle interfacce VTEP-1 e VTEP-2 (assegnati su base configurazione).
- Il pacchetto IP così costruito viene instradato sulla rete IP underlay seguendo le classiche regole dell’instradamento IP. Il pacchetto IP arriva così all’interfaccia VTEP-2.
- L’interfaccia VTEP-2 esegue l’operazione di decapsulamento, ossia toglie dal pacchetto le intestazioni IP e UDP e il VNI, ottenendo la trama Ethernet originale.
- Sulla base del segmento VXLAN di appartenenza (VNI = 100) e dell’indirizzo MAC destinazione (= MAC-B), la trama Ethernet viene inviata all’host destinazione (HOST-B).
- Come avviene il MAC learning e in particolare l’acquisizione della corrispondenza MAC-to-VTEP ? In altre parole, come fa l’interfaccia VTEP-1 a conoscere verso quale interfaccia VTEP instradare la trama Ethernet con destinazione MAC-B ?
- Come viene trasportato il traffico BUM (Broadcast, Unknown unicast, Multicast) ?
TRASPORTO DEL TRAFFICO BUM
Supponiamo che l’HOST-A della figura sopra non conosca l’indirizzo MAC dell’HOST-B. Come avviene nelle classiche reti switched Ethernet, per scoprirlo, HOST-A utilizza il protocollo ARP. HOST-A invia quindi un classico ARP request all’interfaccia VTEP. Il messaggio ARP request, come noto, ha indirizzo MAC destinazione broadcast (= ffff.ffff.ffff). In uno scenario non-VXLAN, il messaggio ARP verrebbe veicolato dalla rete switched Ethernet a tutti gli host della stessa VLAN. In uno scenario VXLAN, il messaggio ARP request viene incapsulato in un pacchetto VXLAN con VNI = 100, indirizzo IP sorgente quello dell’interfaccia VTEP-1 e indirizzo IP destinazione un indirizzo multicast preconfigurato, associato al segmento VXLAN identificato dal VNI = 100. L’indirizzo multicast consente di inviare il pacchetto VXLAN contenente il messaggio ARP request a tutte le interfacce VTEP dove sono collocati host del segmento VXLAN identificato dal VNI = 100.
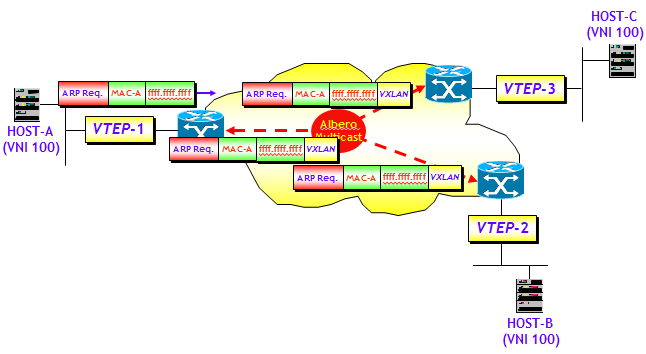
Tutto questo presuppone che all’interno della rete IP sia attivo un protocollo di routing multicast, e che le interfacce VTEP siano in grado di generare messaggi IGMP membership report per effettuare il join/leave dell’albero multicast. Anche se in teoria è possibile utilizzare un qualsiasi protocollo di routing multicast, è noto che “de facto” l’unico protocollo utilizzato nella quasi totalità delle applicazioni pratiche è il protocollo PIM. Una nota a latere è poi che, poiché ciascuna VTEP può essere sia sorgente che destinazione dei pacchetti multicast, è conveniente e raccomandato utilizzare il modello PIM-BiDir (vedi post precedente su mLDP).
Si noti che non è necessario avere un albero multicast per VXLAN, aspetto che potrebbe portare a seri problemi di scalabilità, potendo essere le VXLAN dell’ordine delle centinaia di migliaia (in teoria, come detto sopra, fino a più di 16 Milioni). Possono essere utilizzati tranquillamente alberi multicast condivisi da più VXLAN, comunque la segregazione del traffico tra VXLAN non ne viene influenzata poiché questa dipende esclusivamente dal valore del VNI. Il rovescio della medaglia nell’utilizzo di alberi multicast condivisi, è che il traffico BUM può arrivare anche a VTEP che non hanno host di una particolare VNI, con conseguente spreco di banda.
L’utilizzo del routing multicast per il traffico BUM è quanto prescritto nella versione originale della RFC 7348, ma questo ha costituito un forte freno all'introduzione di VXLAN in reti che non utilizzano routing multicast per altri servizi (la quasi totalità dei Data Center in realtà, a parte quelli di alcune istituzioni finanziarie, che lo utilizzano per inviare a clienti selezionati dati di mercato). Per questo sono state adottate anche soluzioni alternative tipo ad esempio la Unicast-only VXLAN, adottata da Cisco nel proprio switch virtuale Nexus 1000v, di cui tratterò in un post successivo. Però attenzione a possibili problemi di interlavoro, a volte queste soluzioni alternative sono proprietarie !
MAC LEARNING
Il MAC learning avviene in due fasi. La prima è di tipo classico, ed è un MAC learning locale. Tramite questo processo l’interfaccia VTEP “impara” quali sono gli indirizzi MAC locali, ossia degli host che sono “direttamente connessi” alla macchina (fisica o virtuale) dove è definita l’interfaccia VTEP. Ad esempio, ritornando al caso della figura sopra, quando l’HOST-A invia un messaggio ARP request, la macchina dove è definita la funzione VTEP-1 inserisce nella tabella di forwarding L2 (CAM table) l’associazione <MAC-A ; porta>, come farebbe un qualsiasi classico switch L2. La commutazione del traffico locale tra host dello stesso segmento VXLAN avviene in modo tradizionale, senza “scomodare” la funzione VTEP, poiché non è necessario alcun incapsulamento VXLAN.
La seconda fase è quella più delicata, ma comunque semplice. Sempre ritornando al nostro esempio, quando l’interfaccia VTEP-2 (e anche l’interfaccia VTEP-3) riceve il messaggio ARP request, inserisce nella tabella di forwarding L2 della macchina dove è definita l’interfaccia VTEP-2, l’associazione <MAC-A ; IP-1>. L’associazione indica che per raggiungere l’indirizzo MAC-A dell’HOST-A, la trama Ethernet ricevuta dall’interfaccia VTEP-2 utilizza il tunnel VXLAN VTEP-2↔VTEP-1, ossia in pratica la trama viene incapsulata con VNI = 100, e trasportata in UDP/IP con porte UDP che vedremo, indirizzo IP sorgente IP-2 e indirizzo IP destinazione IP-1 (ossia, gli indirizzi IP rispettivamente delle interfacce VTEP-2 e VTEP-1).
Il tutto è riassunto nella figura seguente.
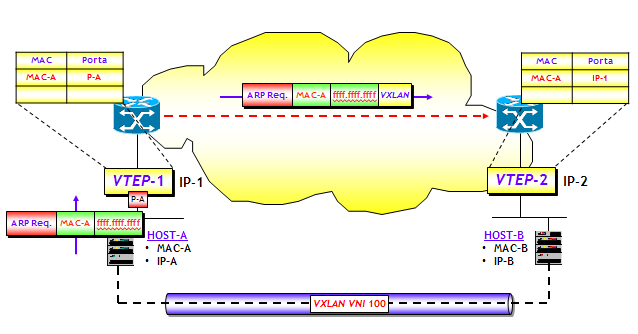
I lettori familiari con il servizio VPLS (Virtual Private LAN Service) avranno prontamente notato che il MAC learning è essenzialmente identico (a parte ovviamente il diverso contesto), ossia avviene interamente sul piano dati (come spesso scritto nella letteratura in inglese, in modalità flood-and-learn).
Recentemente si sta affermando però un’altra strategia, secondo la quale il MAC learning avviene il parte sul piano dati e in parte sul piano di controllo. La parte sul piano dati è quella locale, mentre la propagazione delle associazioni <MAC ; IP-VTEP> avviene sul piano di controllo, utilizzando l’estensione multiprotocollo del caro vecchio BGP (della serie, gallina vecchia fa buon brodo !). Tratterò diffusamente questa modalità in post successivi, ma prima dovrò scrivere qualcosa sul modello E-VPN (Ethernet-VPN, è un modello standard specificato nella RFC 7432 del Febbraio 2015), che può essere pensato come un NG-VPLS (Next Generation-VPLS). Questo modello, molto sofisticato, è già disponibile come piano di controllo per le VXLAN in alcune piattaforme commerciali (es. Cisco Nexus 9k, a partire dalla versione NX-OS 7.0(3)I1(1)). Esiste, ed è ancora in corso, un processo di standardizzazione per l’integrazione VXLAN/E-VPN (draft-ietf-bess-evpn-overlay-02). Tutto questo e altro ancora alle prossime puntate.
FORMATO DEI PACCHETTI VXLAN
I pacchetti VXLAN hanno un incapsulamento del tipo MAC-in-UDP, nel senso che le trame Ethernet originali sono incapsulate in pacchetti UDP/IP. Tra le trame originali e l’incapsulamento UDP/IP vi è il campo VNI. La figura seguente riporta l’intero incapsulamento (NOTA: in realtà è stato omesso l’incapsulamento di Livello 2 esterno, che dipende dal tipo di data-link utilizzato nel trasporto sulla rete IP underlay):
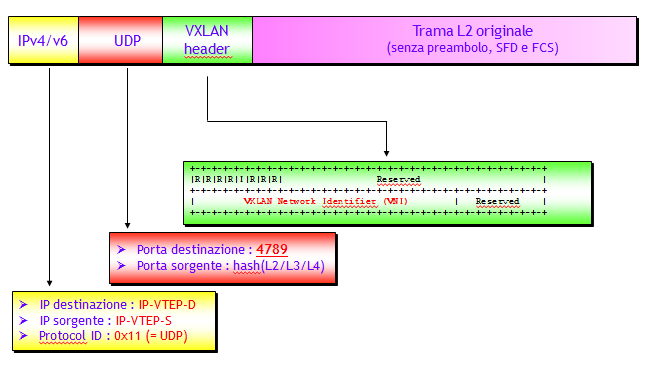
Il campo VXLAN header, in totale di lunghezza 8 byte, è suddiviso in tre parti:
- Flag: sono i primi 8 bit più significativi. Di questi bit, solo il quinto (bit I) va posto a 1, che indica che il VNI è valido. Gli altri 7 bit (bit R) sono sempre nulli e sono ignorati in ricezione.
- VNI: è un campo di 24 bit che contiene il valore di VNI più volte citato.
- Reserved: sono tutti i bit rimanenti, al momento non definiti. Nelle implementazioni correnti sono sempre nulli e sono ignorati in ricezione.
- Porta destinazione: valore well-known riservato dallo IANA all’applicazione VXLAN, pari a 4789.
- Porta sorgente: è il risultato di una operazione di hash di campi predefiniti L2/L3/l4 della trama originale. Lo scopo è quello di avere un valore da utilizzare per il Load Balancing sulla rete del traffico host-to-host, essendo gli indirizzi IP delle interfacce VTEP e la porta UDP destinazione fissi. Il valore risultante dovrebbe essere compreso nell’intervallo [49.152-65.535] riservato per usi privati (vedi RFC 6335).
Un aspetto operativo importante, quando si utilizzano le VXLAN, è la MTU delle interfacce (fisiche) attraversate dai pacchetti VXLAN. Infatti, rispetto al payload della trama L2 originale, per il trasporto vengono aggiunti 50 o 54 byte: IP (20 byte) + UDP (8 byte) + VXLAN (8 byte) + L2 (14 o 18 byte in funzione del tipo di trama Ethernet originale, v2 o IEEE802.1Q). Per cui è necessario accertarsi che la MTU sia sufficiente (es. 1.550 byte), anche perché la RFC 7348 (sez. 4.3) dice chiaramente che “VTEPs MUST NOT fragment VXLAN packets”. Si noti che la RFC 7348 è un po' ambigua circa il trattamento delle trame Ethernet originali contenenti un VLAN tag. Secondo la RFC infatti, le trame contenenti un VLAN tag "dovrebbero" essere scartate in ricezione dalla VTEP, mentre dal lato incapsulamento, il VLAN tag "non dovrebbe" essere trasportato (ossia, deve essere tolto !). Però viene lasciato uno spiraglio in quanto viene detto "unless configured otherwise". E come è noto, sono proprio queste ambiguità che spesso e volentieri creano i maggiori grattacapi nel caso di interlavoro di dispositivi di diversi costruttori.
INTERCONNESSIONE VXLAN-VLAN
Uno degli aspetti evidenti sin dall’inizio dell’introduzione delle VXLAN, è quello di come interconnettere mondo “virtuale” e mondo “fisico”. In altre parole, come interconnettere macchine virtuali che risiedono dietro una VXLAN, con macchine fisiche o virtuali che invece risiedono dietro una tradizionale VLAN (NOTA: la nomenclatura mondo fisico/mondo virtuale, anche se spesso utilizzata, è un po’ ambigua; sarebbe più corretto, secondo me, parlare di interconnessione VXLAN-VLAN).
Il problema è fondamentale perché nella transizione da mondo fisico a mondo virtuale, la convivenza di questi due mondi è inevitabile (un po’ come accade per l’introduzione di IPv6, dove la convivenza tra IPv4 e IPv6 sarà per molti anni anche questa inevitabile).
La funzione di interconnessione in se è concettualmente semplice. È però necessario un dispositivo che abbia il ruolo di gateway tra VXLAN e VLAN, spesso chiamato VXLAN gateway, con il compito di commutare il traffico da segmenti VXLAN a segmenti non-VXLAN e viceversa.
La figura seguente illustra il problema. Il ruolo del VXLAN gateway è quello di prendere i pacchetti VXLAN in arrivo dal segmento VXLAN, togliere l’incapsulamento VXLAN e quindi inoltrare la trama Ethernet originale sulla porta fisica corretta, sulla base dell’indirizzo MAC. Nella direzione opposta, le trame Ethernet in arrivo su una porta fisica non-VXLAN vengono mappate a un determinato segmento VXLAN sulla base del VLAN tag presente nella trama (ossia, nel caso di trame tagged) oppure sulla base dell’associazione (via configurazione) della porta di ingresso a una determinata VLAN (nel caso di trame untagged).
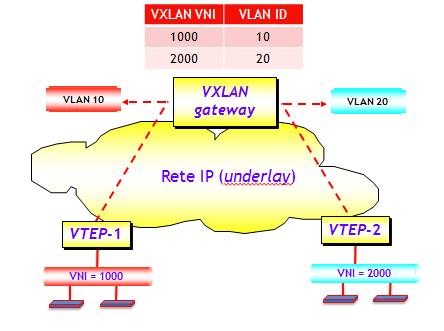
La funzione di VXLAN gateway può essere integrata negli switch ToR (Top of Rack) o in switch più in alto nella gerarchia topologica di un Data Center (core o addirittura WAN edge). Inoltre, la funzione può essere realizzata in Hardware o in Software.
La funzione descritta è in realtà una funzione di Livello 2 poiché mette in comunicazione due segmenti di rete, entrambi di Livello 2, appartenenti allo stesso dominio di broadcast. Vi è anche la possibilità di interconnettere segmenti VXLAN e VLAN appartenenti a diverse subnet IP, e in questo caso si parla di funzione VXLAN gateway di Livello 3. Su questo tornerò in seguito.
La funzione VXLAN gateway è attualmente implementata da vari costruttori, come ad esempio Cisco (Nexus 1000v, Nexus 9k), Juniper (serie MX, EX9200, QFX5100), Arista, Brocade, ecc. . Però, poiché è tutto un mondo dove le cose cambiano dall’oggi al domani, vi consiglio di consultare la documentazione dei costruttori per notizie più “fresche”.
CONCLUSIONI
Con questo post ho iniziato a scrivere su un mondo estremamente dinamico, che è quello dell’overlay virtual networking. Ho iniziato con lo standard VXLAN perché sta godendo dei maggiori favori tra i costruttori e produttori di software. Ma le cose da dire sono infinite e spero in futuro di scrivere molto altro su questi argomenti, cercando di seguire i trend tecnologici giusti. Ad esempio, tra i temi che tratterò presto ci sono quelli relativi al piano di controllo per le VXLAN e all’inter-VXLAN routing.
