

Un piccolo prologo. Nei giorni 26-27 Novembre scorso, abbiamo organizzato due seminari sul nuovo verbo del Software Defined Networking (SDN) e del suo "degno compare" Openflow, entrambi tenuti dal mitico Ivan Pepelnjak. Durante gli intervalli mi sono trovato a parlare con molti brillanti Ingegneri, esperti di reti IP e delle architetture dei Data Center. Tra una chiacchiera e l'altra, parlando del più e del meno, una persona ha fatto questa affermazione "Noi non utilizziamo OSPF nel nostro Data Center poiché converge in 40 secondi". Mi ha ricordato quelli che dicono che il BGP "converge in tre minuti" ! Dandogli una bonaria pacca sulla spalla, gli ho detto, guarda che quello che affermi era vero 20 anni fa, oggi i protocolli Link-State (OSPF e IS-IS), convergono in poche decine di millisecondi, a volte anche meno. E così ho preso spunto per una serie di Post, di cui questo è il primo, che vuole sfatare anche questo (pseudo-)mito.
ASPETTI GENERALI
Le reti IP hanno storicamente affrontato il problema del ripristino del servizio, tramite i protocolli di routing convenzionali (RIP, EIGRP, OSPF, IS-IS, ecc.). Questi sono stati progettati per riconfigurare automaticamente le tabelle di instradamento in caso di cambi della topologia della rete, dovuti al fuori servizio e/o ripristino del servizio di elementi di rete. Benché questi protocolli si siano dimostrati sul campo particolarmente efficaci, non sono in grado, per loro natura, di soddisfare i requisiti di velocità di ripristino del servizio richiesti dalle applicazioni real-time, come ad esempio la voce e il video diffusivo (broadcast) o interattivo. Infatti, nelle reti di grandi dimensioni, il tempo di convergenza dei protocolli di routing IP, ossia il tempo che intercorre tra la rilevazione di un cambio della topologia della rete e la determinazione delle nuove tabelle di instradamento, per quanto sceso nel tempo, se non si effettuano opportuni tuning, rimane ancora dell’ordine dei secondi, tempo troppo elevato per applicazioni di tipo mission-critical.
Questo è il primo di alcuni Post attraverso i quali illustrerò nuovi meccanismi che consentono di raggiungere l'obiettivo della sub-second convergence, ossia della convergenza in meno di un secondo nei protocolli Link-State. Per ciascun meccanismo illustrato cercherò anche di dare delle linee guida per il loro utilizzo.
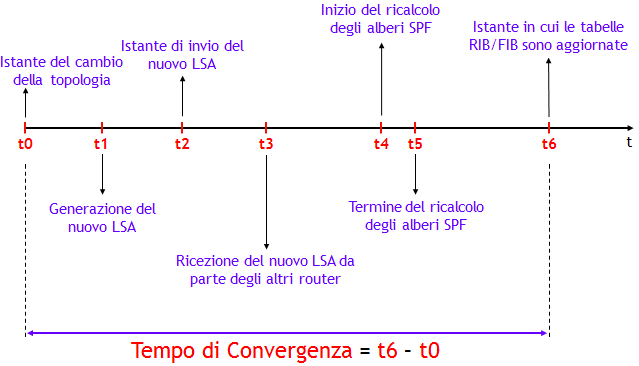
In un protocollo di routing Link-State, a grandi linee, il tempo di convergenza risulta dalla somma di 4 fattori (NOTA: per semplicità utilizzerò nel seguito per i "mattoncini" elementari del Link-State DataBase (LSDB) la terminologia LSA (Link State Advertisement), tipica di OSPF; l'analogo termine in IS-IS è LSP):
- Tempo per rilevare il cambio di topologia : può essere dell’ordine dei msec quando è possibile rilevare un fuori servizio a livello fisico, ma fino a tempi dell’ordine delle decine di secondi quando si fa affidamento sui messaggi HELLO del protocollo. Durante questo periodo di tempo, il traffico che in condizioni di funzionamento nominale avrebbe utilizzato il collegamento e/o nodo fuori servizio, viene inevitabilmente perso.
- Tempo di generazione, invio e propagazione dei LSA: questo tempo è dato dalla differenza tra l’istante in cui il nuovo LSA viene inviato, e la ricezione del nuovo LSA da parte degli altri router. In assenza di perdita dei LSA, i tempi di ritardo variano da una decina a circa un centinaio di msec per router attraversato. Si noti che per motivi di stabilità, dopo la generazione del nuovo LSA, vi è un ritardo nel suo invio (LSA-delay).
- Ricalcolo dei percorsi ottimi via SPF: l’applicazione dell’algoritmo di Dijkstra, nei moderni router, richiede tempi dell’ordine delle decine di msec, anche in presenza di un numero di centinaia di nodi e di centinaia di link. Vi è però un ritardo iniziale del calcolo, anche qui per motivi di stabilità (SPF-delay).
- Aggiornamento RIB e FIB : questo è un tempo che dipende molto dalla particolare piattaforma, e dal numero di prefissi che cambiano il proprio Next-Hop a causa del fuori servizio. Include anche il tempo di aggiornamento delle FIB sulle singole linecard, se applicabile. Come ordine di grandezza, si può pensare a un tempo di un centinaio di msec. Questo tempo dipende però fortemente dal numero di prefissi appresi attraverso il protocollo.
L’obiettivo delle reti moderne è quello di avere tempi di convergenza dell’ordine delle poche decine di msec, comparabili ad esempio a quelli garantiti dai sistemi di protezione dell'ormai vecchio standard SDH. Per questo sono stati sviluppati dei meccanismi che consentono di portare la velocità di convergenza al di sotto del secondo, e in alcuni casi di raggiungere tempi di convergenza dell’ordine delle poche decine di msec.
Con l’evoluzione delle piattaforme, l’affinamento del codice che implementa i protocolli di routing e l’introduzione di nuove funzionalità, i tempi di convergenza dei protocolli Link-State sono diminuiti di molto, passando dalle decine di secondi alle decine di millisecondi.
In passato, uno degli aspetti critici nell’implementazione di questo tipo di protocolli, era il tempo di ricalcolo dei percorsi ottimi attraverso l’algoritmo di Dijkstra. Il notevole aumento della capacità di elaborazione (la celebre legge di Moore !), insieme all’ottimizzazione del codice, ha portato, anche per reti di grandi dimensioni, a tempi dell'esecuzione dell’algoritmo di Dijkstra dell’ordine delle poche decine di msec. Inoltre, la maggiore stabilità dei collegamenti trasmissivi, ha consentito di ridurre notevolmente alcuni timer, che rappresentavano un collo di bottiglia per il tempo di convergenza.
Un altro aspetto fondamentale cambiato rispetto al passato, è che sono stati sviluppati criteri per rilevare più velocemente la perdita di una adiacenza. Infatti, fare affidamento sui timer associati ai messaggi HELLO, comporta tempi elevati per rilevare la caduta dell’adiacenza. Tempi che si potrebbero abbreviare agendo sui valori del periodo dei messaggi HELLO e sull'Holdtime associato, ma il prezzo da pagare è una maggiore occupazione della CPU. Tra le funzionalità introdotte per abbreviare in modo efficiente il tempo per rilevare la perdita di una adiacenza, ho già trattato ampiamente in Post passati il Bidirectional Forwarding Detection (BFD). In questo Post darò informazioni aggiuntive su questo aspetto.
Tra le funzionalità introdotte per l’ottimizzazione del tempo di convergenza, tratterò in Post successivi, le seguenti:
- Tuning dei timer: molti timer, in particolare LSA-delay e SPF-delay, hanno la possibilità di essere abbreviati notevolmente tramite meccanismi di Exponential Backoff o simili. (NOTA: come citato sopra, LSA-delay e SPF-delay sono rispettivamente, il ritardo di generazione di un LSA a fronte della ricezione di un cambio di topologia, e il ritardo di ricalcolo dell’albero SPF a fronte della ricezione di un LSA che annuncia un campio di topologia (NOTA nella NOTA: anche un cambio delle metriche associate alle interfacce viene interpretato come un cambio di topologia, e quindi ha come effetto la generazione di un nuovo LSA e il ricalcolo dei percorsi ottimi via SPF)).
- Ottimizzazione dell’algoritmo SPF: sono state introdotte metodologie come Incremental SPF e Partial Route Calculation, che consentono di non eseguire l’intero algoritmo quando non necessario.
- spf per-prefix prioritization: partendo dalla considerazione che non tutti i prefissi hanno la stessa importanza (es. un prefisso /32 di un router PE utilizzato per stabilire sessioni iBGP, è più importante di una subnet con cui si numera un collegamento punto-punto), sono stati introdotti meccanismi che consentono ai prefissi più importanti di essere trattati con precedenza rispetto a quelli meno importanti (e quindi finiscono nella RIB e FIB prima di altri prefissi !).
- Loop-Free Alternate: è una funzionalità che consente di inserire nella FIB anche un Next-Hop di backup, da utilizzare temporaneamente durante il tempo di convergenza.
Uno degli effetti indesiderati che si ha durante la convergenza di un protocollo di routing, è la formazione di micro-loop, ossia loop temporanei che si formano per brevi periodi, e che scompaiono una volta terminata la convergenza.
La formazione dei micro-loop è causata dallo sfasamento con cui i router determinano i nuovi percorsi ottimi. La figura seguente riporta un esempio del fenomeno.

Con le metriche riportate nella figura, il router A, per raggiungere il prefisso X ha come Next-Hop il router D, mentre il router D ha come Next-Hop il router E. Ora, si supponga che l’adiacenza tra i router D ed E cada, ad esempio per un fuori servizio del collegamento D-E. Come conseguenza, i router D ed E generano il loro nuovo Router Link LSA, per comunicare agli altri router la caduta dell’adiacenza.
A causa dei ritardi di propagazione sul collegamento D-A, che nelle applicazioni pratiche possono raggiungere tempi anche delle decine di msec, il router A riceverà gli LSA generati da D ed E, dopo che il router D ha determinato il nuovo percorso. Il nuovo Next-Hop di D per il prefisso X sarà necessariamente A, per cui, prima che A abbia ricalcolato il nuovo percorso, si verifica un evidente micro-loop. Infatti, A ha (prima del ricalcolo dell’SPF) Next-Hop D, e D ha come nuovo Next-Hop A.
Quanto sono dannosi i micro-loop ? Dipende dalla durata e dai servizi trasportati dalla rete. Nelle reti moderne, dove i timer dei protocolli, come vedremo nel seguito, sono ottimizzati, la durata di un micro-loop è dell’ordine delle decine o al più centinaia di msec, tollerabili dalla maggior parte dei servizi.
È possibile evitare i micro-loop ? Si, sarebbe sufficiente che ciascun nodo avesse, per ciascun prefisso raggiungibile, un Next-Hop alternativo già «pronto per l’uso», ossia precalcolato e presente nella FIB. Il Next-Hop alternativo dovrebbe garantire l’assenza di loop (ossia, essere loop-free) e consentire l’instradamento del traffico su un percorso alternativo (benché non ottimo !), per il tempo necessario alla rete a raggiungere una nuova e stabile situazione di convergenza. Questa funzionalità, nota come Loop-Free Alternate (LFA) è stata sviluppata dai principali costruttori, è oggetto di uno standard IETF, e sarà vista in un Post successivo (NOTA: il lettore familiare con il protocollo proprietario Cisco EIGRP, avrà notato una certa similitudine del LFA con i concetti di Successor e Feasible Successor di EIGRP. In realtà sono la stessa cosa, ma applicati in contesti completamente diversi. Un’altra nota idea simile al LFA, è il servizio Fast Rerouting, che si ha in MPLS-TE (MPLS Traffic Engineering). Altra idea analoga, per chi ha già letto il Post precedente, è la funzionalità BGP PIC).
CARRIER-DELAY
Dopo questa doverosa introduzione generale sulla convergenza dei protocolli di tipo Link-State, voglio trattare in questo Post il primo elemento fondamentale nel processo di convergenza: come minimizzare il tempo per rilevare la perdita di una adiacenza.
Ho già illustrato ampiamente nei precedenti Post il BFD, che trova il suo naturale scenario di applicazione nel caso di collegamenti costituiti da più segmenti come ad esempio PVC Frame Relay o ATM o VLAN Ethernet. Può anche essere utilizzato nel caso di collegamenti back-to-back per risolvere certi tipi di fuori servizio, per cui ne consiglio comunque l'utilizzo.
Nel caso di collegamenti back-to-back, in aggiunta al BFD, è possibile utilizzare un meccanismo di comunicazione "veloce" al protocollo di routing del fuori servizio di una interfaccia, simile al già visto BGP fast-external-fallover.
Nei router Cisco questo meccanismo viene indicato come carrier-delay, ed è il tempo che l’interfaccia attende prima di notificare al supervisor, che il collegamento è down oppure è ritornato nello stato up. Si noti che se una interfaccia va nello stato down e ritorna nello stato up prima della scadenza del carrier-delay, lo stato down viene “filtrato”, ossia non notificato al resto del software.
La configurazione del carrier-delay, nell'IOS/IOS-XR Cisco avviene tramite il seguente comando (NOTA: come sempre, fate attenzione alla versione IOS, il comando non è sempre uguale !):
(config)# interface tipo numero
(config-if)# carrier-delay down msec [up msec]
Per il significato delle parole chiave down e up, si consideri il seguente esempio nell'IOS-XR:
RP/0/RSP0/CPU0:(config)# interface gi0/1/0/0
RP/0/RSP0/CPU0:(config-if)# carrier-delay down 0 up 1000
Questa configurazione implica che la comunicazione di interfaccia down all’IOS avviene immediatamente, mentre un eventuale nuovo up, per mitigare l’effetto di eventuali link flap viene ritardato di 1 sec (= 1.000 msec). Come best-practice di solito si pone down = 0 msec, o nel caso di protezione ottica, a un valore leggermente superiore al tempo di protezione (50-60 msec). Si noti che in molte versioni IOS il valore di default del down è 2.000 msec (=2 sec), ma consiglio comunque sempre di verificare la documentazione Cisco.
Le interfacce POS (Packet Over SONET/SDH), possono fornire una protezione nativa in tempi molto brevi, tipicamente inferiori a 50 msec. Per queste interfacce, è opportuno porre il timer specifico della tecnologia POS, il delay trigger line, a un valore maggiore del tempo di protezione nativo, al fine di nascondere al Livello 3 un fuori servizio non-critico a livello fisico. Nel caso la protezione nativa non sia attivata, è bene porre il delay trigger line a un valore nullo.
Anche nelle interfacce POS è definito il carrier-delay. Il carrier-delay è il ritardo tra la rilevazione dell’assenza di segnale SONET/SDH (o la fine del delay trigger line) e l’update dell’interfaccia a livello IOS. È buona pratica porre questo ritardo sempre a un valore nullo, o come citato sopra, in presenza di protezione ottica a un valore leggermente superiore al tempo di protezione.
Nei router Juniper, è possibile configurare il carrier-delay con il comando seguente:
[edit interfaces interface-name]
tt@router# show
hold-time up msec down msec;
dove il significato delle parole chiave up e down è identico a quello visto per l'IOS Cisco.
IP EVENT DAMPENING
Per una protezione addizionale contro i link flap è bene poi attivare la funzionalità IP event dampening. Questa funzionalità, a grandi linee, è basata su un meccanismo “a memoria”, che permette al router, di costruire uno storico dell’instabilità di una interfaccia, sulla base del quale intraprendere azioni di fuori servizio "forzato" momentaneo dell’interfaccia, ossia, l'interfaccia viene comunque fatta rimanenre nello stato down per un certo tempo, indipendentemente dal suo possibile ritorno nello stato up.
Per definire un’interfaccia instabile, si utilizza un meccanismo di penalizzazione, basato su un valore di penalità, che viene incrementata di un valore costante (nei router Cisco pari a 1.000), in corrispondenza di un down dell'interfaccia.
Nell’intervallo di tempo tra due down successivi, il valore di penalità viene fatto decrescere esponenzialmente. L’andamento del valore di penalità nel tempo, risulta così simile a un tipico “dente di sega”, con il valore che incrementa di una quantità costante negli istanti di ritorno allo stato down dell'interfaccia, e che decrementa esponenzialmente tra due down successivi.
La costante che regola il decadimento esponenziale è denominata half-life, e rappresenta il tempo impiegato a dimezzare il valore di penalità corrente.
Superato un determinato limite, denominato suppress-limit, l’interfaccia viene “congelata”, ossia, viene forzata nello stato down anche se dovesse tornare nello stato up.
L’interfaccia potrà essere riutilizzata, se e solo se è soddisfatta almeno una delle due seguenti condizioni:
- Il valore di penalità scende al di sotto di un valore configurabile, denominato reuse-limit.
- Il tempo trascorso dall’istante in cui l’interfaccia è dichiarata “congelata”, supera il valore configurabile denominato max-suppress-time.
Infine, quando il valore di penalità scende sotto della metà del reuse-limit, la penalità viene azzerata.
(NOTA: per i cultori del BGP, questa funzionalità è stata mutuata dal meccanismo (standard) di stabilità BGP Route Flap Damping, descritto nella RFC 2439).
La funzionalità IP event dampening si configura nell'IOS tramite il comando:
(config)# interface tipo numero
(config-if)# dampening [half-life reuse-limit suppress-limit max-suppress-time]
dove i parametri temporali half-life e max-suppress-time sono espressi in secondi, e i valori di default dei 4 parametri sono [5 1000 2000 20].
Nell'IOS-XR il comando è identico ma i parametri temporali half-life e max-suppress-time sono espressi in minuti, e i valori di default dei 4 parametri sono [1 750 2000 4].
Per chi fosse interessato ad ulteriori approfondimenti sulla funzionalità IP event dampening, consiglio di dare un'occhiata a questo Post, dove tra l'altro potrete trovare una ottima discussione sulla scelta dei parametri.
Nel JUNOS la funzionalità IP event dampening, così come implementata nei router Cisco, non è invece supportata. Credo che gli Ingegneri Juniper ritengano sufficiente l'effetto anti-flapping del comando "hold-time ..." descritto sopra.
OTTIMIZZAZIONE DELLA COMUNICAZIONE DELLO STATO DELL'INTERFACCIA
Infine c'è un altro tuning interessante che è possibile eseguire. Di default nell'IOS, l'evento interfaccia down viene segnalato direttamente alla RIB. Questo implica che la RIB debba eseguire un processo di scanning per cercare i percorsi che hanno come Next-Hop l'interfaccia down, per poi rimuovere tutti i percorsi che hanno quel Next-Hop. Quindi, dopo questo processo viene informato il protocollo di routing, il quale riconverge dopo un certo tempo e quindi vengono riaggiornate RIB e FIB. Un processo che non è molto efficiente, poiché coinvolge due volte l'aggiornamento di RIB e FIB (di cui il primo evitabile). Questo comportamento, nelle versioni più recenti dell'IOS può essere cambiato in modo che a fronte del down dell'interfaccia, venga informato direttamente il protocollo di routing (e non la RIB !), in modo da avere un solo aggiornamento di RIB e FIB (quello a valle della convergenza del protocollo di routing). Nell'IOS, il comando che abilita questo comportamento è il seguente:
router(config)# ip routing protocol purge interface
Nell'IOS-XR questo comportamento "ottimizzato" è di default, quindi non ha bisogno di alcun comando di abilitazione.
Non ho trovato nel JUNOS un comando analogo, probabilmente perché il JUNOS implementa di default il comportamento ottimizzato descritto sopra, ma non l'ho trovato scritto da nessuna parte.
CONCLUSIONI
Con questo Post inizio una trilogia sulla convergenza dei protocolli di routing Link-State, ossia OSPF e IS-IS. Il contenuto di questo Post, nella sua seconda parte è in realtà generale, e si applica a tutti i protocolli di routing. Nei prossimi due illustrerò invece aspetti specifici dei protocolli Link-State.
Se ne volete sapere di più potete seguire i nostri corsi IPN232, IPN233 (entrambi per la tecnologia Cisco), IPN253 e IPN260 (per la tecnologia Juniper).
